Foreseeing the Unforeseeable: How U.S. Negligence Law Should Address the Foreseeability of Harms Caused by Autonomous AI Agents
Abstract
As AI systems increasingly perform tasks with limited human oversight, courts will soon be required to determine how negligence law should respond when autonomous AI agents cause personal injury. Traditional foreseeability doctrine, as many scholars have observed, may fail to account for the opacity and unpredictability that characterize these systems. The main challenge could arrive when AI developers claim that a harmful outcome was unforeseeable because the specific causal pathway was novel, complex, or obscure. This article argues that such reasoning misallocates responsibility. Building on recent scholarly work, it takes the view that opacity and unpredictability are not inherent features of advanced AI systems. Rather, they are the result of abstraction choices made by AI developers, who often prioritize accuracy and efficiency over interpretability and predictability. When those choices increase the likelihood of opaque or unexpected outcomes, the legal framework should be adjusted to reflect that responsibility. In particular, where the foreseeability standard in negligence law typically makes it difficult for plaintiffs to prevail, it should be relaxed in their favor. The article examines how U.S. courts apply foreseeability across duty, breach, and proximate cause, and identifies the duty stage as the most urgent point for reform. It proposes a three-part doctrinal framework for cases involving personal injury caused by autonomous AI agents. First, courts should preserve existing law where foreseeability is already sympathetic to plaintiffs. Second, they should replace overly fact-intensive duty inquiries with clear, plaintiff-friendly categorical reasoning. Third, they should retain fact-intensive analysis at the breach and proximate cause stages to prevent overextension of liability. This approach maintains foreseeability as a meaningful constraint while calibrating it to the distinctive risks posed by autonomous AI agents.
Mapping AI Policy: Where, Why, and How to Intervene
Abstract
State lawmakers introduced over 1200 bills on artificial intelligence (AI) in 2025, nearly doubling the number from the year before. Almost 150 were enacted.[ref 1] They cover topics as varied as deepfakes, biased decision-making systems, or rogue AI systems. Yet the media describes them all as “AI legislation,” revealing an impreciseness that makes it hard for legal practitioners, policymakers, and the public to understand key AI policy issues.
This primer offers a framework for thinking more precisely about AI policy. It analyzes legislation along three dimensions: the harm being addressed (the why), the factors that should guide intervention design (the how), and the actor in the AI ecosystem being targeted (the where).
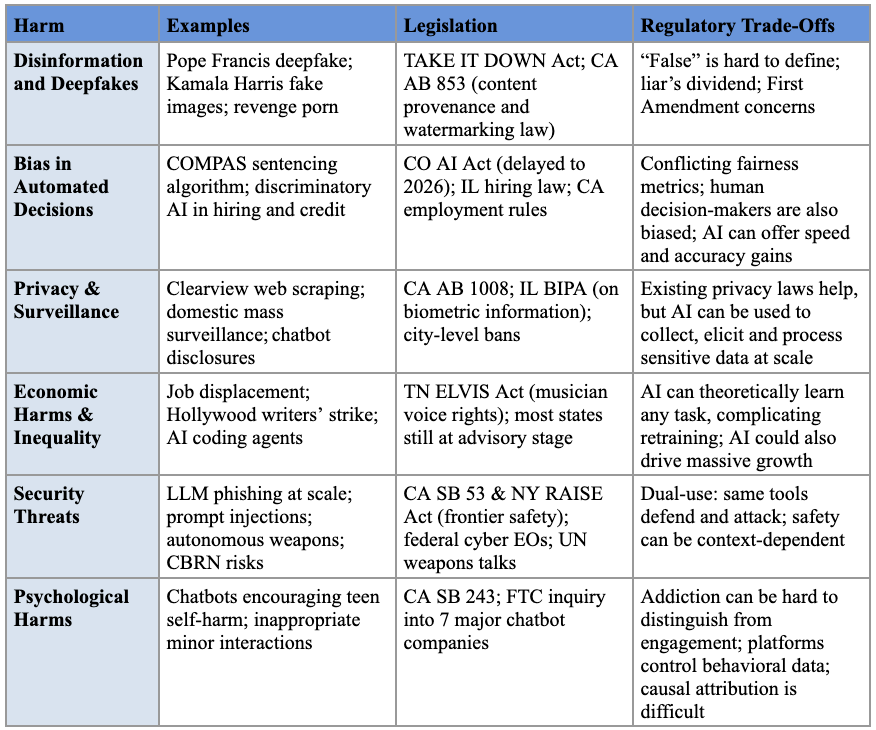
Part I organizes the universe of AI harms into six categories: (1) mis- and disinformation-related harms; (2) bias in automated decision systems; (3) privacy and surveillance harms; (4) economic harms and inequality from automation; (5) security threats; and (6) psychological harms. With so many applications being called AI—including search engines, chatbots, pricing algorithms, and robots—lawmakers risk being overwhelmed by the consequences of AI if they do not have a clear goal in mind.
Part II introduces seven design factors that recur across harms and stages: whether to prevent harms or respond to them, how an intervention affects concentration of power, whether regulation is the right tool at all, and others. These factors are often in tension. An intervention that decentralizes the AI ecosystem may make enforcement harder; one that restricts offensive capabilities may also degrade beneficial ones.
Part III maps the actors in the AI ecosystem—from chip manufacturers to end users—and analyzes the advantages and limitations of targeting each. Analyzing AI in this way highlights the distinct functions performed by the actors within the AI ecosystem, enabling policymakers to design more tailored interventions rather than relying on overly broad regulatory categories.
Ultimately, this primer underscores two core principles for navigating the complexities of AI policy. First, the more precisely policymakers can identify the harm and the actor best positioned to prevent it, the more effective their interventions are likely to be. Second, policymaking in this rapidly evolving domain is rarely simple; there are few free lunches, and choices will inevitably require confronting difficult tradeoffs. Accordingly, this primer does not advocate for specific policy positions. It offers a framework to empower policymakers to make better decisions on AI.
I. The Why: What AI-Related Harm Does the Policy Intervention Address?
To understand how to regulate AI, policymakers must first understand why they want to regulate it. How can one write laws to achieve a desirable end without knowing what that end is? This part gives policymakers language for specifying what they wish to achieve by outlining the AI-related harms they might wish to address.
The categories below are neither mutually exclusive nor comprehensive. One practice, for example, can fit into multiple buckets of harm. Algorithmic pricing, where companies use AI to charge different consumers different prices for the same product, can cause privacy harms (through the surveillance data collection that powers it), economic harms (through the higher prices it can impose), and bias harms (when higher prices correlate with protected characteristics like race or religion).
They are intended to be an illustrative list of commonly referenced AI harms that can serve as a starting point for policymakers writing and debating AI legislation. In particular, this primer does not address environmental harms from AI training and deployment or the intellectual property issues that arise from the use of copyrighted material in AI training. Here our focus is on harms caused by using AI, not those arising from the process of creating AI systems.
Each of the following subsections describes an example of the harm, offers examples of relevant legislation, and explains the unique aspects of the harm that make it difficult to address, as well as benefits that might be lost if the regulations are poorly designed.
A. Misinformation and Disinformation-Related Harms
The potential harms of AI-generated content resurface in the public discourse each time a deepfake goes viral. In 2023, a fabricated image of Pope Francis in a white puffer highlighted the impressive capabilities of state-of-the-art image generators,[ref 2] while the circulation of AI-generated images by Donald Trump’s presidential campaign in 2024—depicting his rival Kamala Harris at a communist rally and the singer Taylor Swift as a campaign supporter—underscored the technology’s potential for political disruption.[ref 3]
Amidst these concerns, several states have already enacted some legislation, though they have largely focused on two specific contexts: politics and pornography. To protect election integrity, over half of states have enacted laws requiring disclaimers on or banning the distribution of deceptive AI-generated campaign media.[ref 4] In addition, nearly all states have enacted laws prohibiting deepfake non-consensual intimate imagery (“revenge porn”).[ref 5] At the federal level, the recently enacted TAKE IT DOWN Act further strengthens these protections by creating a private right of action against individuals who produce or share such content and by requiring platforms to remove it upon notification.[ref 6]
Beyond these targeted applications, some legislative efforts have aimed to address content authenticity more broadly. California’s AI Transparency Act, for example, requires developers of generative AI models to enable digital watermarking and content provenance capabilities.[ref 7]
Despite this legislative activity, addressing the misinformation-related harms of AI remains challenging for at least four reasons. First, defining “false” or “misleading” in an objective, consistent, and apolitical way is extraordinarily difficult.[ref 8]
Second, the public perception of widespread misinformation is itself dangerous by eroding trust in the information ecosystem, creating a “liar’s dividend” where authentic content is more easily dismissed as fake.[ref 9]
Third, many interventions face First Amendment hurdles because they may infringe upon the free speech rights of platforms or users. This is not a theoretical concern; federal courts have enjoined Hawaii’s and California’s election deepfake laws, reasoning that their broad scope could unconstitutionally chill protected forms of speech like parody and satire.[ref 10]
Fourth, overly stringent regulations could inadvertently cripple the very capabilities that make large language models transformative. If LLM performance substantially suffers from excessive content restrictions, burdensome compliance mandates, or unclear liability rules, their utility could be severely diminished.[ref 11] For instance, models might become overly cautious, refusing to engage with complex or sensitive topics, thereby limiting their effectiveness as educational tools or research assistants.[ref 12]
B. Bias in Automated Decision Systems
Bias—systematic errors that result in unfair outcomes against certain individuals or groups—can enter AI systems through unrepresentative training data, societal prejudices reflected in that data, or the very objectives developers set for an algorithm.[ref 13] The stakes are high, as automated systems now make some of the most consequential decisions in people’s lives. For example, the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) algorithm has been used for years by judges nationwide to generate “risk assessments” for criminal sentencing.[ref 14] Despite concerns around racial, gender, and other biases in tools like COMPAS, such systems are widely used in other critical areas, including hiring[ref 15] and access to credit,[ref 16] among others.
Colorado’s AI Act (SB 24-205) is the signature legislation designed to address this problem.[ref 17] Enacted in May 2024, it requires developers of high-risk systems to use “reasonable care” to protect consumers from algorithmic discrimination by mandating risk management programs and impact assessments. However, because its provisions have been delayed until at least June 2026, the bill’s real-world impact remains to be seen.[ref 18] Other states have followed Colorado’s lead with their own variations: Virginia’s legislature passed a similar bill that was ultimately vetoed,[ref 19] Illinois enacted a law targeting discriminatory AI in hiring,[ref 20] and California has issued anti-discrimination regulations for automated employment systems.[ref 21]
Addressing AI biases has proven difficult, despite nearly a decade of awareness among policymakers and technologists. A core challenge is translating abstract concepts of “fairness” into quantifiable metrics; researchers have identified at least 21 distinct mathematical definitions of fairness,[ref 22] many of which are mutually exclusive.[ref 23] Furthermore, restricting automated systems over bias concerns presents a difficult trade-off. Doing so could mean reverting to human decision-makers, who have their own biases,[ref 24] while also sacrificing the speed, cost-efficiency, and potential accuracy gains that algorithms offer.
C. Privacy and Surveillance Harms
AI creates privacy and surveillance risks at three key stages: when information is collected to build AI, when it is exposed while using AI, and when AI is deployed to collect and process new information.
The first risk arises from the data collection used to train AI models, which often includes personal information scraped from the internet without an individual’s consent. The facial recognition company Clearview AI, for example, built its database by scraping billions of images from platforms like Facebook.[ref 25] This practice has prompted legal challenges, such as a lawsuit alleging that Clearview’s data scraping violated Illinois’s Biometric Information Privacy Act along with privacy laws in several other states, which resulted in a $50 million settlement.[ref 26]
A second privacy risk emerges when users share intimate details with interactive systems like AI chatbots.[ref 27] States are beginning to adapt their privacy laws for this new reality. California’s Assembly Bill 1008, for instance, amends the state’s Consumer Privacy Act (CCPA) to clarify that personal information output by AI systems is covered by existing privacy protections.[ref 28]
Finally, AI serves as a powerful tool for surveillance. For example, by 2023 U.S. police had performed nearly a million facial recognition searches using Clearview AI.[ref 29] In response, several states have enacted limitations on police use of facial recognition. Massachusetts is one of the few states to restrict police use of the technology,[ref 30] while some cities have banned its use by government agencies altogether.[ref 31] The Pentagon-Anthropic dispute was a recent flashpoint around this exact issue.[ref 32]
Regulating AI’s privacy harms presents a paradox. On one hand, the issue may be more tractable than other AI risks because states have spent years developing legal frameworks for data privacy that can be adapted to AI. On the other hand, regulation is uniquely difficult because many of AI’s transformative benefits are tied to its ability to process massive amounts of sensitive data. This creates complex trade-offs, such as balancing the public safety benefits of AI surveillance against individual privacy rights.
D. Economic Harms and Inequality From Automation
The fear that AI will automate jobs, further concentrating wealth and power in the hands of a few private actors, looms over many discussions about the technology.[ref 33] These fears are so significant that Hollywood writers went on strike over the potential threat to their livelihoods,[ref 34] while many illustrators worry about the future of their profession[ref 35] due to advanced image generators like Midjourney, Stable Diffusion, and Gemini and ChatGPT’s image generation features.
Tennessee’s ELVIS Act, which extended an artist’s publicity rights to include AI-generated voice content, is an early attempt at addressing the economic effects of AI and narrowly focuses on entertainment industries.[ref 36] More comprehensive legislation seems unlikely in the near future, particularly as many states have only recently convened AI advisory groups to research and plan for future economic changes.
Lawmakers will likely continue to struggle with mitigating these impacts due to the unpredictability of AI’s future capabilities. Thus far, advancements have been both rapid and uneven.[ref 37] For example, OpenAI’s o1 model marked a sudden and significant leap in large language models’ ability to solve mathematical problems[ref 38]—an area where previous models were heavily criticized for underperformance.[ref 39] More recently, AI coding agents like Claude Code have progressed from autocomplete assistants to autonomous systems capable of writing code with minimal human oversight, disrupting a profession many once assumed was insulated from automation.[ref 40] With AI capabilities advancing this quickly and unpredictably, it becomes increasingly difficult for policymakers to identify which professions are most at risk of automation, let alone determine the appropriate timeline for addressing these challenges.
Yet the potential economic benefits are also massive. In some ways, the worst-case scenario might also be the best-case. The more jobs that are automated by AI, the more powerful the AI system. If these systems do become the functional equivalent of a “country of geniuses in a datacenter,” the economic growth and quality of life improvements can be substantial.[ref 41] And if such benefits can be distributed equitably (an admittedly big if), the economic future enabled by AI can be far better than what exists today.
E. Security Threats
The spectrum of AI-related security threats is broad, ranging from digital vulnerabilities that compromise data and systems to physical dangers that threaten lives and infrastructure. AI can increase the frequency and scale of these incidents both by amplifying existing risks and by introducing entirely new vulnerabilities.
In the cybersecurity domain, AI can be a force multiplier for malicious actors.[ref 42] Large language models can be used to generate sophisticated spear-phishing emails (targeted attacks disguised as legitimate communication) at an unprecedented scale or to automatically detect vulnerabilities in codebases.[ref 43] Beyond amplifying old threats, AI models themselves introduce new attack vectors when integrated into digital services.[ref 44] For example, “indirect prompt injection” vulnerabilities have allowed attackers to take control of a user’s session in a chatbot and steal their conversation history.[ref 45] As more services incorporate these AI tools, such vulnerabilities create new routes for attackers to compromise systems.
The potential for physical threats is also deeply concerning. State actors can use AI to augment intelligence capabilities, deploy more sophisticated weapons like lethal autonomous weapons (LAWs), and enhance their capacity to conduct cyberattacks against critical infrastructure.[ref 46] Furthermore, AI lowers the barrier for non-state actors to access dangerous capabilities, potentially making it easier to develop and deploy chemical, biological, radiological, or nuclear (CBRN) weapons.[ref 47]
Legislative efforts to address these threats have emerged at the state, federal, and international levels. The most prominent state-level proposals have targeted developers of frontier AI models. California’s SB 53[ref 48] and New York’s RAISE Act,[ref 49] signed into law in September and December 2025, respectively, impose largely similar requirements: both require large frontier developers to publish safety frameworks, report critical safety incidents, and face civil penalties for noncompliance. Together, the two laws are beginning to function as a de facto national standard for addressing catastrophic AI risks.
At the federal level, Congress has shown interest in AI’s role in cyberspace,[ref 50] and the Biden administration issued Executive Orders to both accelerate the use of AI in national cyber defense[ref 51] and (in an order since repealed by the Trump administration) to oversee advanced AI development through measures like compute cluster reporting and “Know-Your-Customer” (KYC) requirements for cloud providers.[ref 52] Internationally, forums like the UN Group of Governmental Experts on LAWs have been exploring frameworks to regulate AI in warfare.[ref 53]
Despite these efforts, mitigating security threats remains challenging. A core difficulty is AI’s dual-use nature: the same capabilities that can help people defend and improve systems can also be used to help malicious actors attack them. Organizations are already using AI to detect phishing attempts and patch vulnerabilities, and Microsoft alone blocks tens of billions of threats annually. The difficulty with dual-use is compounded by the fact that safety is not an inherent property of an AI model. Just as an electric motor’s safety depends on its application, an AI model’s potential for harm is context-dependent, making it difficult to assign liability or design proactive, one-size-fits-all regulations. Finally, the sheer technical complexity and vast scale of these systems make designing comprehensive and effective policy interventions an incredibly difficult task.
F. Psychological Harms
Beyond physical, economic, or information-related threats, AI systems have the potential to cause significant psychological harm, particularly among vulnerable populations like children and adolescents.
AI companions and social media algorithms are engineered to maximize engagement through personalized content and simulated empathetic responses, which can lead to excessive use and what some researchers term “addictive intelligence.”[ref 54] Such AI interactions risk supplanting real-world relationships and exacerbating feelings of loneliness and social isolation, even when initially perceived as helpful.[ref 55] Moreover, over-reliance on AI for social connection may impair interpersonal skills, as AI relationships often lack the reciprocity, spontaneity, and nuanced emotional engagement characteristic of human connections.[ref 56]
Children and adolescents are particularly vulnerable to these risks. Multiple recent lawsuits allege that AI chatbot companies’ products have contributed to teen suicides, self-harm, and other psychological harms. Plaintiffs have alleged that chatbots discouraged users from seeking help from parents or professionals, engaged in inappropriate sexual interactions with minors, and encouraged addictive and unhealthy relationships.[ref 57]
States are beginning to pass legislation targeting these harms.[ref 58] Yet enacting laws to mitigate psychological harms creates several distinct challenges. First, identifying psychological harm is difficult: clinical addiction can be confused for high engagement and vice versa. Second, this definitional challenge is confounded by a measurement problem: the platforms suspected of causing harm often exclusively control the behavioral data (such as time on device) necessary to assess that harm. Third, attributing harm directly to AI proves difficult in a landscape where multiple factors influence mental well-being. Fourth, many interventions—especially those targeting algorithmic design or content—raise significant free speech concerns.[ref 59] Finally, effective regulation must balance these harms against AI’s potential psychological benefits, including improved access to mental health support and personalized therapeutic interventions that might otherwise be unavailable.
* * *
Ultimately, this overview of some of the harms of AI is intended to remind policymakers of the importance of deciding what they want to accomplish before deciding how they want to regulate. An added benefit is that it allows policymakers to better understand AI legislation passed in other states. Consider two high-profile AI bills: Colorado’s AI Act (SB 24-205), which targets bias in automated decision systems, and California’s Transparency in Frontier Artificial Intelligence Act (SB 53), which addresses catastrophic risks from frontier AI models. Despite their completely different areas of focus, both are described in media as landmark AI legislation. This missing nuance may lead policymakers to incorrectly believe that they need only pass one omnibus “AI” bill when the reality is they will likely need to pass many AI-related bills to address the technology’s multifaceted harms. Once policymakers know why they want to regulate, the next Part helps them understand how.
II. The How: What Factors Shape Intervention Design?
This part introduces seven factors that should guide policymakers in thinking about where and how to intervene to mitigate AI harms. These factors are not mutually exclusive. A single intervention will implicate multiple principles in ways that might be in tension with each other, which is part of why AI regulation is so difficult. For example, an intervention that encourages the proliferation of open-weight models could mitigate concerns about undue concentration of power (factor 3), while making it harder to limit the offensive capabilities of malicious actors (factor 2) and enforce regulations (factor 5).
A. Harm Prevention (Ex Ante) vs. Harm Response (Ex Post)
Interventions can be distinguished by whether they aim to prevent harms before they occur (ex ante) or respond to harms after they materialize (ex post).[ref 60] Licensing regimes,[ref 61] pre-deployment testing requirements,[ref 62] capability restrictions,[ref 63] and deterrence strategies[ref 64] are more preventive. Incident reporting[ref 65] and content takedown obligations[ref 66] are more responsive. Tort liability has elements of both: it’s responsive in that it awards compensation to harmed parties, but it’s also preventative in that the threat of future sanctions incentivizes companies to prevent those harms in the present. [ref 67]
Whether preventative or responsive interventions are preferable will often depend on the nature of the harm.[ref 68] Preventive interventions are more valuable when harms are difficult or impossible to reverse, such as election interference that cannot be “un-voted”[ref 69] or physical harms that cannot be undone.[ref 70] But preventive interventions require predicting harms in advance and risk being overbroad, which can be difficult for general-purpose technologies like AI that have so many applications. Responsive interventions allow society to learn from harms and calibrate policy accordingly,[ref 71] but they provide cold comfort to those who are harmed as the legal system learns to adapt. An effective regulatory regime will likely need some combination of both.
The speed of harms also bears on the choice between harm prevention and response. Some AI harms materialize rapidly, such as a cybersecurity attack on critical infrastructure or a viral deepfake in the final days of an election, leaving little time to respond. Others occur more slowly: erosion of trust in information or the long-term impacts of a biased AI loans system. For fast-moving harms, ex ante intervention may be essential if ex post remedies arrive too late to matter.
Distributional considerations further complicate the comparison. Ex ante compliance costs are initially borne by developers and typically passed on to consumers. Ex post costs fall first on victims, who must bear the harm and then seek compensation through legal processes that may be slow, expensive, and uncertain. This asymmetry matters especially when AI systems harm people poorly equipped to navigate ex post remedies: individuals without resources to hire lawyers or diffuse groups suffering harms too small individually to justify litigation but significant in aggregate. A regime that relies heavily on ex post liability may systematically undercompensate these populations, even if it works well for well-resourced plaintiffs with clear injuries.
B. Strengthening Defense (Armor the Sheep) vs. Weakening Offense (Defang the Wolves)
Interventions can also be categorized by whether they primarily aim to restrict offensive capabilities (making it harder for bad actors to cause harm) or enhance defensive capabilities (making potential targets more resilient to attack).[ref 72] Export controls and licensing regimes are examples of offensive restriction; they attempt to keep dangerous capabilities out of the “wrong” hands. Investments in cybersecurity infrastructure and early-warning systems are examples of defensive enhancement;[ref 73] they assume adversaries will obtain offensive capabilities and focus on defending against harm.
For some harms, reducing offensive capabilities may be the only viable mechanism. We don’t have defensive approaches to handling the harms created by nuclear weapons, so reducing offensive capabilities through nonproliferation treaties and deterrence strategies is the only viable approach. But offense-reduction strategies are often a double-edged sword: they create incentives for targets to develop workarounds,[ref 74] require centralizing power for enforcement,[ref 75] and can degrade AI’s beneficial capabilities. Because restricting offensive capabilities is difficult[ref 76] and can have undesirable consequences,[ref 77] we recommend that policymakers adopt defense-enhancing strategies for AI where possible.
Defense-enhancing strategies can be both regulatory and technological. Whistleblower protections[ref 78] and incident reporting help companies and regulators identify and respond to harms more quickly.[ref 79] These are legal choices that can improve a jurisdiction’s “resilience” to harms. Vitalik Buterin popularized the technological equivalent with a theory he calls defensive accelerationism (“d/acc”),[ref 80] analogizing to “armoring the sheep” rather than trying to “defang the wolves.”[ref 81] The d/acc movement aims to accelerate the development of defensive technologies. For biosecurity, this might look like installing better HVAC systems or accelerating vaccine development for AI-enabled bioweapons or pandemics. For cybersecurity, this might look like using AI systems like Claude Code or Devin to automatically identify and patch security vulnerabilities.[ref 82] Bernardi et al.’s “Societal Adaptation to Advanced AI” is an excellent primer for thinking about what these defensive strategies might look like.[ref 83]
C. Impact on Concentration of Power
The AI policy community is divided over whether harm mitigation is better served by centralizing or decentralizing the AI ecosystem.[ref 84] This consideration typically runs together with the previous one (ex ante vs ex post harm prevention)[ref 85] because reducing offensive capabilities (model nonproliferation, export controls, etc.) often requires centralizing power for effective enforcement.[ref 86]
The choice between centralization and decentralization is not binary and the considerations differ across layers of the AI stack (see below). At the infrastructure layers (semiconductor supply chain, cloud compute providers), a concentrated chip supply chain can simultaneously create chokepoints useful for export controls and supply-chain vulnerabilities.[ref 87] At the application layer, decentralization enables AI applications tailored to a wide range of specific contexts, though it may complicate efforts to enforce regulations.[ref 88] Policymakers should consider how a given intervention affects concentration at each layer, recognizing that the arguments will vary depending on the layer.
A decentralized ecosystem can improve safety through redundancy and distributed detection of problems. If one developer’s system fails or exhibits unexpected behavior, others may catch the issue.[ref 89] Decentralization also reduces the stakes of any single failure; an error by one of many competitors is likely to be less catastrophic than an error by a dominant player. Yet decentralization can also undermine safety by creating races to the bottom, where competitive pressure leads developers to cut corners on safety investments that don’t translate into market advantage.[ref 90] Fragmented oversight becomes harder when regulators must monitor dozens of developers, and coordination on shared safety standards grows more difficult as the number of actors multiplies.
Concentration also implicates separate questions about industrial policy. Tim Wu has argued that highly concentrated industries develop outsized lobbying power and capture regulators.[ref 91] On this view, the concern is not merely that a few AI developers might build unsafe systems, but that they might accrue sufficient political influence to weaken the oversight meant to constrain them.[ref 92] At the same time, concentration intersects with industrial policy objectives and anxieties about geopolitical competition. Policymakers who worry about competition with China may favor cultivating “national champions:” a small number of well-resourced domestic firms capable of matching foreign competitors.[ref 93]
Each of the interventions discussed in this primer can be located on a spectrum from promoting centralization to decentralization, and policymakers should consider not only which end of that spectrum aligns with their beliefs about AI risk, but also how concentration at different layers of the stack interacts with the offense-defense balance and enforcement.
D. More Upstream Interventions are More Blunt
The amount of context needed to identify a harm will influence where in the ecosystem (see below) to intervene. Upstream interventions (Stages 1–3) are often better suited for context-independent harms because they can restrict capabilities without needing to evaluate specific uses.[ref 94] Downstream interventions (Stages 4–6) are often better able to address context-dependent harms because deployers and users have more information about how AI is actually being used.[ref 95]
Truly context-independent harms are rare since many AI capabilities are dual-use. The same capacity that generates phishing emails also drafts legitimate marketing copy. The same image capability that can produce nonconsensual intimate imagery creates art. Even capabilities that seem clearly dangerous often sit on a spectrum: a model’s ability to discuss virology in detail could facilitate bioweapon development or accelerate vaccine research depending on who is using it and why.[ref 96] But it’s still a useful principle. Some harms are identifiable without knowing much about the circumstances in which AI is used. The production of child sexual abuse material, for instance, is harmful regardless of context. Other harms depend heavily on context: whether a piece of AI-generated content constitutes misinformation, satire, or parody depends on how it is distributed and received.
Downstream interventions can be more precisely targeted, restricting specific uses while leaving others untouched.[ref 97] A platform can prohibit using its AI tools for generating political advertisements without restricting political speech more broadly. A deployer can implement know-your-customer requirements that screen out bad actors while permitting legitimate users. But this precision comes at a cost: downstream interventions often require the capacity to monitor and evaluate specific uses, which may be practically difficult at scale, may require centralization (see above), and shift enforcement burdens to actors who may lack the resources or incentives to implement them effectively.[ref 98]
E. Enforcement Feasibility (Certainty vs. Severity of Penalties)
Traditional enforcement through the legal system requires identifiable defendants within a jurisdiction who can be compelled to pay damages or serve sentences.[ref 99] When these conditions are met, interventions targeting applications and users can be highly effective because they address harms where they occur.
But many AI-related harms involve actors who are difficult or impossible to reach through traditional enforcement: foreign adversaries, anonymous bad actors, autonomous AI systems, or diffuse harms for which no single defendant is responsible. In these situations, compute governance (Stages 1–2) becomes more valuable because it operates through chokepoints—concentrated infrastructure that can be controlled even when end users cannot be.[ref 100]
Policymakers assessing enforcement feasibility should consider three questions. First, can compliance be observed?[ref 101] Some requirements are relatively easy to verify (e.g., whether a model has been submitted for pre-deployment review, whether a chip shipment crossed a border). Others are harder to monitor (e.g., whether a company’s internal safety practices match its public commitments). When compliance is difficult to observe, enforcement depends on whistleblowers, audits, or investigations, which are more resource-intensive yet less complete.[ref 102]
Second, who will enforce? Regulatory requirements need an agency with the statutory authority, technical expertise, and budget to monitor compliance and pursue violators.[ref 103] If that agency doesn’t exist or is underfunded, requirements may go unenforced.
Third, what are the consequences for non-compliance, and are they sufficient to deter? A small fine may be treated as a cost of doing business; a large fine may deter only if the probability of detection is meaningful. An important note is that the certainty of apprehension and punishment matters far more than the severity of punishment for deterrence.[ref 104] For AI governance, this implies that investing in monitoring and detection infrastructure may be more valuable than increasing statutory penalties.[ref 105] It also suggests that highly publicized enforcement actions, which increase the perceived certainty of consequences, may matter more than their direct effects on the individual defendants involved.
Market structure also shapes which tools are feasible. When an industry is concentrated, regulation is more tractable: fewer entities to monitor, greater compliance capacity, and reputational stakes that give enforcement actions bite.[ref 106] When an industry is fragmented, direct regulation may be impractical, pushing policymakers toward upstream chokepoints or tools like liability that don’t require entity-by-entity oversight. When entry barriers are low, regulations binding only incumbents may simply shift activity to less scrupulous providers.
F. Allocating Responsibility to the Least-Cost Avoider
A foundational principle of tort law holds that liability for a harm should be assigned to the party who can most cheaply and effectively prevent it: the “least-cost avoider.”[ref 107] This principle provides useful guidance for allocating responsibility across the AI ecosystem.[ref 108]
In practice, identifying the least-cost avoider is contested. Consider an AI system that generates plausible-sounding medical misinformation that a user then relies upon.[ref 109] Is the least-cost avoider the developer (who could have trained the model to be more cautious about medical claims), the deployer (who could have added guardrails or warnings), the platform that distributed the content (who could have labeled or filtered it), or the user who relied on it without verification? Each could have prevented the harm at some cost, and reasonable people will disagree about which intervention was cheapest or most effective (not to mention the contested normative question of who “ought” to have prevented the wrong).
The principle nevertheless provides a useful starting point: for harms resulting from unpredictable system failures (such as hallucinations), developers and deployers may be best positioned to invest in prevention because they are best positioned to build the scaffolding necessary to protect an AI system. For harms resulting from intentional misuse by end users, this principle may suggest focusing on the end user because they choose whether and how to deploy AI for harmful purposes.[ref 110] For harms that are harmful regardless of context (like CSAM generation), joint and several liability across the production chain may be appropriate to ensure all parties have incentives to prevent it.[ref 111]
G. Is Regulation the Right Tool?
Finally, policymakers should ask whether regulation is the right intervention at all. It is one tool among many, and depending on the type of harm, other interventions may be more effective.
Consider the range of alternatives. Investing in and adopting defensive technologies (like the kind described in subsection 2), for example, may be more effective in reducing cybersecurity vulnerabilities than regulation mandating cybersecurity best practices. Technical standards development, whether led by industry or the government, can also establish shared benchmarks for safety, interoperability, and performance that influence behavior.[ref 112] Government procurement power can shape markets as companies compete on the metrics set by federal agencies for what they will purchase.[ref 113] Antitrust enforcement (with remedies like divestiture) may address some concentration of power problems that regulation does not. And as consumers grow more sophisticated in evaluating AI products, market pressure alone may discipline some harms without the need for regulatory intervention.
Enforceability should weigh heavily in this assessment (discussed in subsection 5). Different tools require different enforcement capacities, and an intervention that cannot be meaningfully enforced may be worse than no intervention at all, creating the illusion of oversight while harmful practices continue or burdening compliant actors while bad actors ignore requirements.
Ultimately, the question is both “which actor should we target?” and “what kind of intervention is most likely to work?” Policymakers should not rush past these questions by assuming regulation is the solution to every problem.
III. The Where: Which Actor in the AI Ecosystem Does the Intervention Target?
The path from silicon chip to real-world harm is filled with actors that could prevent those harms. This primer organizes actors in the AI ecosystem into seven stages based on their role in the AI ecosystem: (1) chip designers and manufacturers, (2) cloud compute providers, (3) data suppliers, (4) model developers, (5) application deployers, (6) complementary and enabling platforms, and (7) end users. Each set of actors offers a potential leverage point for intervention.
These stages do not map neatly onto corporate structures: a single company can span multiple categories. Google, for example, functions as a cloud provider (Google Cloud), data supplier (via YouTube), model developer (Google DeepMind), and application deployer (Gemini). The purpose of this framework is to help policymakers regulate by the role an entity plays in the causal chain from the creation of an AI system to the materialization of harm, regardless of who performs each function.
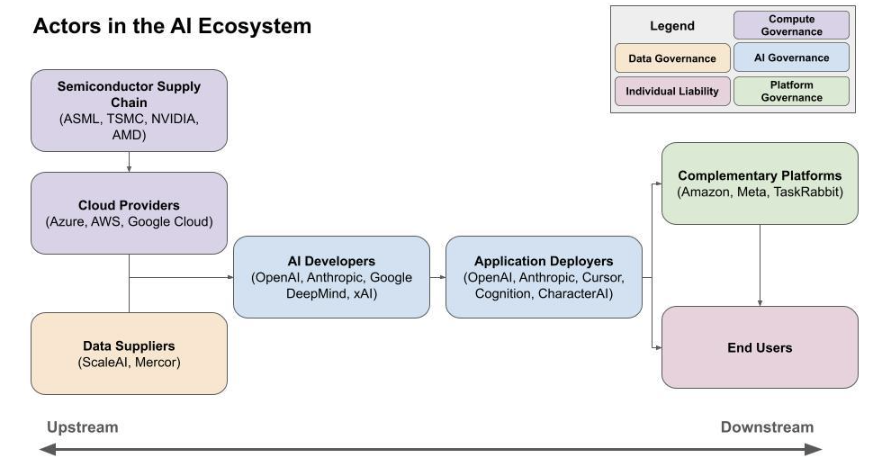
A. Stage 1: Chip Designers and Manufacturers
The semiconductor supply chain is a key intervention point for shaping AI’s development and deployment. Training and running advanced AI systems requires specialized semiconductors like Application-Specific Integrated Circuits (“ASICs”) or Graphics Processing Units (“GPUs”). These chips are designed by a handful of companies (mostly NVIDIA, AMD, Google) and produced by an even smaller number of foundries (mostly TSMC) using manufacturing equipment (extreme ultraviolet (“EUV”) lithography machines) from a single supplier (ASML). This market concentration creates chokepoints that policymakers can leverage for policy enforcement.[ref 114]
Examples of Policy Interventions
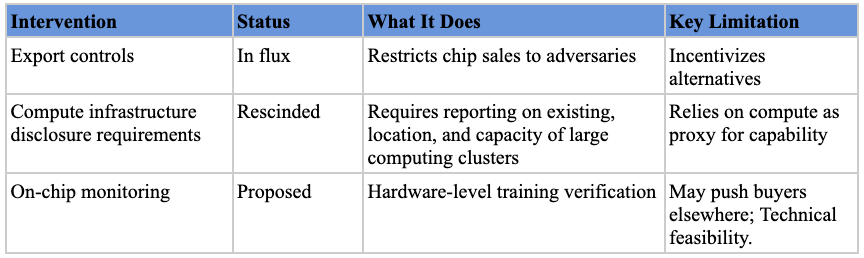
Export controls on AI chips. The U.S. government’s primary tool for shaping international AI development thus far has been export controls on advanced semiconductors, first announced in late 2022 and updated several times since.[ref 115] This policy is in flux as the Trump administration has flip-flopped on export controls for advanced AI chips to China. The most recent announcement was that NVIDIA can sell its advanced H200s to China.[ref 116]
Compute infrastructure disclosure requirements. The Biden Administration’s 2023 AI executive order (since rescinded) required entities acquiring or possessing large-scale computing clusters to report their existence, location, and total computing capacity to the government.[ref 117] This was intended to give policymakers visibility into the physical infrastructure being assembled for advanced AI training.
On-chip governance mechanisms. Researchers have proposed adding technical components to chips that would give regulators visibility into large training runs without compromising AI companies’ commercial interests.[ref 118] Though requiring further research into technical feasibility, verification mechanisms have been a prerequisite for international cooperation in other domains (like nuclear nonproliferation) and may be just as valuable for AI governance.[ref 119]
Advantages of Targeting This Stage
Focusing policy interventions on semiconductor companies has four key advantages: excludability, quantifiability, detectability, and enforcement feasibility.[ref 120]
First, computing resources are excludable because people can be prevented from accessing them. Unlike data or algorithms, which are easily copied and shared, there are a finite number of operations that a single GPU can perform. If one actor is fully utilizing those operations, no one else can.
Second, compute is quantifiable—it “can be easily measured, reported, and verified” in terms of the operations per second a chip can perform or its communication bandwidth with other chips.[ref 121]
Third, large-scale training runs are detectable. The most advanced AI models currently require large-scale training runs using thousands of specialized chips concentrated in power-intensive data centers. These facilities are detectable by third parties, with some visible from satellite imagery.
Finally, the semiconductor supply chain is extraordinarily concentrated, making enforcement feasible.[ref 122] NVIDIA controls 80-95% of the market for AI chip design; TSMC fabricates approximately 90% of advanced chips; ASML supplies 100% of the extreme ultraviolet lithography machines used by leading foundries. This concentration makes the other three advantages actionable: fewer actors makes monitoring and enforcement easier.[ref 123]
Disadvantages of Targeting This Stage
Despite these advantages, semiconductor-focused interventions have three significant drawbacks: they rely on an assumption that may not hold, they are blunt and they become less effective the more they are used.
First, semiconductor-focused regulation relies on compute serving as an effective proxy for capability. If AI performance improves such that less-than-state-of-the-art models become capable of serious harm, or if algorithmic efficiency gains reduce the compute needed for dangerous capabilities, then semiconductor-focused interventions will miss their intended target.[ref 124] Additionally, as Arvind Narayanan and Sayash Kapoor have argued, “AI safety is not a model property,” since whether an output is harmful depends on context, and capability restrictions are thus, although laudable, a misguided approach.[ref 125]
Chip-level interventions are also among the bluntest available.[ref 126] Because semiconductors are general-purpose inputs, restrictions at this stage cannot distinguish between beneficial and harmful uses of AI. Export controls that limit access to advanced chips, for example, constrain medical research and climate modeling just as much as they constrain weapons development or surveillance. Policymakers targeting this stage risk throttling AI development altogether rather than surgically addressing specific harms.
Finally, semiconductor interventions are valuable in the short term but potentially counterproductive in the long-term. On-chip governance mechanisms and export controls, while potentially controlling how chips are used or limiting adversaries’ access to them in the short term, encourage investment in alternatives. On-chip restrictions could push buyers toward more open alternatives produced in other jurisdictions. Some have argued U.S. export controls benefit China’s semiconductor industry by encouraging further investment,[ref 127] though others believe such indigenization fears are overblown.[ref 128] And geopolitical competition may prevent countries from regulating their own semiconductor industries at all, for fear of ceding a competitive edge. Finally, compute-based restrictions may encourage innovation that renders compute less likely to be a bottleneck in the future. For example, DeepSeek’s efficiency may be an unintended consequence of limiting Chinese firms’ access to computing resources, with compute constraints forcing researchers to develop more efficient algorithms.
Summary
Semiconductor-based interventions are a powerful policy tool. They work best for harms that are identifiable without much context, where a single malicious actor’s access to advanced capabilities increases risk regardless of how they’re used. They are particularly valuable when traditional enforcement is impractical—against foreign actors, in situations involving diffuse harms, or when agencies cannot possibly monitor all end users. But policymakers should be aware that these interventions are a blunt instrument that incentivize workarounds, and they depend on compute remaining a bottleneck for dangerous capabilities.
B. Stage 2: Cloud Compute Providers
A handful of cloud computing providers—Amazon Web Services, Microsoft Azure, and Google Cloud—operate the computing infrastructure used by most developers to train and deploy AI models. Because this stage and the previous one both focus on the computational resources underpinning advanced AI, they share many characteristics and are often grouped together under the general heading of “compute governance.” This section focuses on the ways in which targeting cloud providers differs from targeting the semiconductor supply chain.[ref 129]
Examples of Policy Interventions
Know-Your-Customer (KYC) requirements. Efforts to impose KYC obligations on cloud providers date back to Trump’s first-term EO 13984 (2021),[ref 130] which Biden’s EO 14110 (2023)[ref 131] later expanded with AI-specific reporting mandates. Providers would be required to notify the government when foreign actors access computing resources above certain thresholds, aiming to prevent adversaries from anonymously using U.S. infrastructure for dangerous AI development.
Cybersecurity compliance and AI safety standards. In 2024, the Commerce Department’s Bureau of Industry and Security (BIS) proposed rules requiring cloud providers and their clients to report on frontier AI development activities, including compliance with cybersecurity frameworks and results of mandatory red-teaming tests.[ref 132] This would leverage cloud providers as enforcers to ensure hosted AI projects meet security benchmarks.[ref 133]
Government oversight of frontier AI training. Some researchers have recommended requiring licenses for AI training that exceeds certain compute thresholds.[ref 134] Cloud providers would require government approval before allowing training runs capable of producing frontier models—resembling licensing in the aerospace and nuclear energy industries.
Advantages of Targeting This Stage
Cloud computing shares the same fundamental advantages as semiconductor governance—concentration, excludability, quantifiability, and detectability—but offers additional benefits for regulators.
First, cloud providers’ business models already require extensive monitoring. Because they charge customers based on usage, they precisely measure resource consumption through metrics like floating-point operations, GPU hours, and energy consumption. This existing infrastructure can be repurposed for regulatory compliance with less added burden.
In addition, unlike the semiconductor supply chain, which is distributed across the United States’ allied nations, including the Netherlands, Japan, and Germany, the world’s largest cloud providers are headquartered in the United States. This gives American policymakers more jurisdictional flexibility in designing and enforcing regulations.[ref 135]
Cloud providers can also respond to non-compliance immediately. Unlike semiconductor restrictions, where there is a lag between placement on an export control list and actual business disruption, cloud access can be revoked in real time (similar to how banks can freeze accounts). This makes cloud-based enforcement more like financial regulation than trade regulation.
Disadvantages of Targeting This Stage
Cloud provider interventions share the two core weaknesses of semiconductor controls and add a third.
Like semiconductor interventions, cloud-based regulation relies on the assumption that advanced AI requires access to large compute clusters. If algorithmic efficiency improves enough that dangerous capabilities can be achieved with modest resources, then cloud-focused controls will miss their target.
Cloud restrictions also risk sparking the same kind of workarounds and indigenization that undermine export controls. Developers facing extensive compliance requirements may switch to less-regulated providers in other jurisdictions, and countries seeking AI independence or “sovereignty”[ref 136] may invest in domestic cloud infrastructure precisely to escape U.S.-based oversight. The more effective cloud controls are in the short term, the stronger the incentive to route around them in the long term.
Finally, cloud interventions also raise concerns that detailed tracking of activity on clients’ servers could expose information that companies treat as trade secrets like training techniques.[ref 137] And broad authority to cut off companies’ access to computing resources creates potential for abuse, as officials might target companies disfavored by the governing party or use access as leverage for purposes beyond AI safety.
Summary

Cloud provider interventions function as a more responsive version of semiconductor controls—enforcement can happen immediately rather than through supply-chain disruption. They are particularly valuable when real-time response matters or when tracking the identity of AI developers (rather than just their capability) is important. However, they come with greater privacy trade-offs and the same diminishing-returns problem as other compute governance approaches.
C. Stage 3: Data Suppliers
AI models are trained on data sourced from many entities: large-scale web scrapers (like C4), crowdsourced platforms (like Amazon Mechanical Turk), and specialized data labeling companies (like ScaleAI and Mercor).[ref 138] The goal of data-supplier-focused interventions is to improve the upstream collection and quality of AI training data to reduce downstream harms.[ref 139]
Examples of Policy Interventions
Individual data rights. Several states require data brokers to register with the government and disclose details about the data they collect, how it’s used, and their sharing practices. California’s Delete Act aims to allow residents to request deletion of their personal information from data brokers through a single request.[ref 140] Illinois’s Biometric Information Privacy Act (BIPA) requires opt-in consent for entities collecting biometric data,[ref 141] significantly affecting AI facial recognition training. With AI, honoring these rights may involve removing data from supplier databases, retraining models, or filtering outputs traceable to deleted data, though the FTC has ordered complete model deletion in cases of egregious data misuse.[ref 142]
Collective licensing and compensation mechanisms. John Axhamn has proposed an “Extended Collective Licensing (ECL)” scheme that would allow AI developers to legally train on copyrighted works while ensuring rightsholders receive compensation.[ref 143] A Congressional Research Service report discusses these frameworks as potential solutions to the tension between AI training and intellectual property rights.[ref 144]
Public datasets. Governments and research institutions could create and maintain high-quality public datasets. The Trump administration’s Genesis Mission is an attempt to unify federal scientific archives into a centralized, standardized platform, democratizing AI development for smaller companies and academic researchers who lack resources to develop proprietary datasets.[ref 145]
Advantages of Targeting This Stage
Addressing data quality and legality at the point of collection and aggregation can prevent problems from multiplying as models are deployed.[ref 146]
Many data supplier regulations align with existing privacy laws like GDPR and CCPA.[ref 147] This allows policymakers to build on established definitions, enforcement mechanisms, and compliance infrastructure rather than creating entirely new regulatory regimes.
The data broker[ref 148] and AI data labeling[ref 149] industries are also relatively concentrated, allowing authorities to oversee a significant portion of data flowing into AI systems by regulating a manageable number of entities.
Disadvantages of Targeting This Stage
Data suppliers can operate globally, potentially sourcing data from or locating servers in jurisdictions with weaker regulations. AI developers might bypass rules by using offshore brokers or scraping data outside the state’s reach.[ref 150]
Defining who qualifies as a regulated “data supplier” is also difficult.[ref 151] Rules could be too narrow (missing web scrapers) or too broad (burdening nonprofits like Wikipedia or individual bloggers). And compliance costs may further consolidate the market around larger players who can afford them.
Finally, regulations restricting collection, sale, or use of data may face First Amendment challenges. The Supreme Court’s decision in Sorrell v. IMS Health held that the “creation and dissemination of information are speech,” meaning data regulations can potentially trigger heightened constitutional scrutiny.[ref 152]
Summary

Data supplier regulations are most useful for harms directly linked to data inputs—privacy violations, copyright infringement, and biased training data—and where key data sources are concentrated and identifiable. They also benefit from alignment with existing privacy frameworks like GDPR and CCPA. They are less effective when data is highly diffuse, when suppliers operate across jurisdictions, or when defining the scope of regulated entities is difficult.
D. Stage 4: AI Model Developers
This stage focuses on organizations that research, develop, and train large-scale AI models—entities like OpenAI, Anthropic, Google DeepMind, Meta AI, and xAI. Given their central role in developing core AI capabilities, model developers are frequent targets for policy intervention.[ref 153]
Examples of Policy Interventions
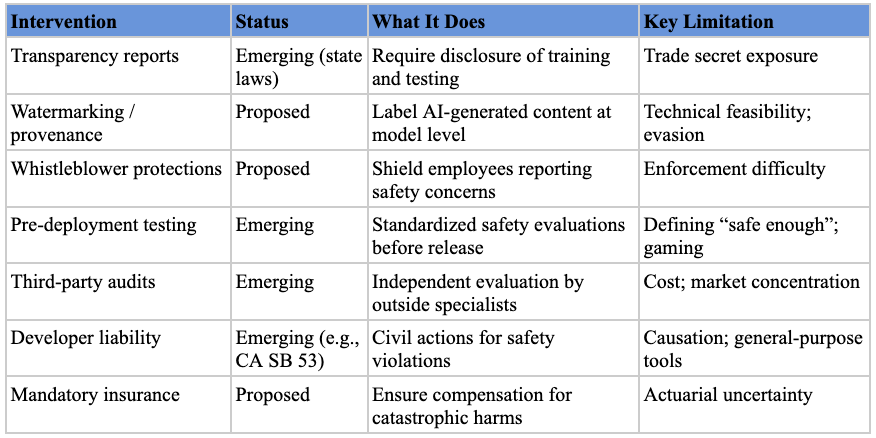
Transparency and Disclosure Mandates. The most common type of intervention at the state level promotes transparency through disclosure requirements.[ref 154] These can take several forms: requiring companies to publish reports on model development and testing processes; mandating watermarks or content provenance techniques to label AI-generated content; creating whistleblower protections for AI lab employees; and establishing incident reporting requirements for significant safety events.
Testing, Design, and Oversight Requirements. These interventions focus on ensuring safety through design mandates and ongoing oversight.[ref 155] They might include ex ante design features (cybersecurity safeguards, content filtering, “kill switches”), standardized pre-deployment evaluations, red-teaming by internal safety experts,[ref 156] or third-party audits by civil society organizations (like METR) or government agencies (like the UK AISI or US CAISI).[ref 157]
Liability frameworks. Policy researchers have advocated holding model developers liable for harms caused by their systems.[ref 158] California’s SB 53, for example, authorizes the state Attorney General to bring civil actions against developers for failure to report safety incidents or comply with their own frameworks, with damages up to $1,000,000.[ref 159] Insurance requirements could complement direct liability by ensuring compensation is available and creating actuarial signals about the riskiest models.[ref 160] For catastrophic risks, policymakers could consider ex ante mechanisms like mandatory liability insurance or industry-wide compensation funds, modeled on frameworks like the Price-Anderson Act for nuclear accidents.[ref 161]
Advantages of Targeting this Stage
Transparency measures are among the least controversial categories of model developer regulation.[ref 162] Even experts who disagree about the speed and shape of AI risks often agree on the need for more transparency.[ref 163] The rationale is that disclosure empowers users, researchers, and regulators to make informed decisions—if people know how a model was created and tested, they can better assess its reliability and risk.
Testing and oversight requirements can target vulnerabilities in base models that propagate to downstream applications. If a foundation model has a security vulnerability or can be tricked into revealing training data, applications built on top of it can inherit those vulnerabilities.[ref 164] It also leverages technical expertise outside government: regulators can set standards and review results while outsourcing the highly technical evaluation process to specialists.[ref 165]
Finally, liability incentivizes developers to prevent harms by requiring them to pay for damage caused by their models. Liability forces companies to internalize externalities rather than shifting costs to users or society. It also can function as a floor of legal protection, with some egregious AI harms likely falling within the scope of existing tort law.[ref 166]
Disadvantages of Targeting this Stage
Transparency requirements carry their own risks. Detailed disclosures about training data or architectures could expose trade secrets, allowing competitors (including foreign actors) to free-ride on research investments. Watermarking faces technical feasibility concerns: determined actors can remove watermarks, and open-source models that don’t apply them will remain unlabeled. And in the United States, compelled disclosure requirements may face First Amendment challenges as compelled speech.[ref 167]
Oversight requirements face a different problem: defining “safe enough” is extremely difficult. AI systems can fail in unpredictable ways, and any set of evaluations risks missing novel failure modes. Worse, developers might learn to game required tests, tuning models to pass evaluations without truly improving safety.[ref 168] Extensive testing requirements can also slow innovation and concentrate the market as larger, well-resourced companies absorb compliance costs more easily.
Finally, liability is limited by the fact that many AI harms are not within developers’ sole control. AI systems are general-purpose tools used in countless contexts far removed from what creators envisioned. If an open-source model is integrated into hundreds of applications, it may be unfair to blame the model’s creators for a particular application’s failure or a user’s misuse. Defining “reasonable care” for AI, determining causation when multiple actors are involved, and apportioning liability (joint and several vs. proportional) all present difficult legal questions.[ref 169] Liability also functions best when wrongdoers can afford to pay; when the defendant lacks resources or the harm is too large, liability does not fully compensate victims and is a less effective deterrent.
Summary
Model developers are a natural focal point for AI regulation because they control the foundational capabilities on which downstream applications depend. Transparency requirements enjoy the broadest support and face the lowest political barriers, though they must be designed to avoid exposing proprietary information. Testing and oversight requirements can catch vulnerabilities before they propagate downstream, but they must be iteratively adjusted as capabilities evolve—static evaluations will quickly become obsolete. Liability frameworks complete the picture by internalizing costs, but their effectiveness depends on resolving difficult questions about causation, apportionment, and the financial capacity of defendants to pay for harms their models enable.
E. Stage 5: Application Deployers
The application layer is where AI capabilities are operationalized into products and services. The entity developing the model can also be the deployer (OpenAI’s ChatGPT is built on its GPT models), but different companies can also build applications on top of models developed by others. Applications span nearly every sector: predictive algorithms for employment screening (HireVue, Pymetrics) and criminal justice risk assessments (COMPAS); generative models powering chatbots (Character.ai) and coding environments (Cursor); and agentic systems capable of completing tasks without human intervention (Claude Code, Devin).
Examples of Policy Interventions
Incident reporting. When AI applications malfunction or cause harm, rapid disclosure enables regulators and the public to identify patterns and respond before problems spread. Analogous requirements exist across regulated industries: the FDA mandates adverse-event reporting for medical devices, NHTSA requires crash reporting for autonomous vehicles, and the FAA tracks near-miss incidents in aviation. Extending this model to AI deployers would require companies to notify a designated agency when their systems produce significant failures—whether a hiring algorithm systematically excludes qualified candidates or a medical diagnostic tool generates dangerous misdiagnoses. The core difficulty is defining what counts as a reportable “incident” for general-purpose AI systems that operate across diverse contexts.
Tort liability. Application deployers are also potential targets for liability.[ref 170] Injured parties can sue the deployer for compensation if a particular application causes harm. One mother, for instance, sued Character.AI over her son’s suicide, alleging design defects.[ref 171] In a separate case, the parents of a sixteen-year-old sued OpenAI, alleging that ChatGPT acted as a “suicide coach” that encouraged their son’s suicidal ideation.[ref 172] The possibility of liability creates incentives to build safe products. Legislatures can play an important role in ensuring this system functions well. California’s AB 316, for example, is a recently enacted bill that aims to ensure there is no AI exception to existing tort liability frameworks.[ref 173] It prevents defendants from disclaiming responsibility by arguing that an AI agent acted autonomously.[ref 174] Legislatures could also codify duties of care rather than leaving courts to define them through the common-law process.
Age restrictions. These provisions require deployers to implement age-appropriate design for systems used by minors, including limiting data collection, obtaining parental consent, and requiring plain-language explanations. Texas’s SCOPE Act (2024) offers a comprehensive template: it requires parental consent before minors can create accounts, prohibits in-app purchases and geolocation tracking for minors, bans targeted advertising to children, and mandates content filtering for material promoting self-harm, substance abuse, or exploitation.[ref 175] This approach is valuable because it shifts the compliance burden onto platforms rather than parents, creating structural protections that don’t depend on individual digital literacy or vigilance.
Self-exclusion. These statutes require deployers to build protective features into products—such as session caps, break reminders, and disabling infinite scroll—that help users limit their own consumption. The UK Gambling Commission’s “reality check” regulations provide a direct model:[ref 176] operators must display recurring on-screen reminders of elapsed session time that users must actively acknowledge before adding new funds,[ref 177] and the UK has banned autoplay features entirely while mandating time intervals between interactions.[ref 178] This framework is valuable because it acknowledges that willpower alone may be insufficient against products engineered for engagement, and it creates friction that can help users close the gap between what they want and what they want to want.
Outright bans. In contexts where AI is deemed too dangerous, policymakers might prohibit its use entirely. The U.S. Space Force temporarily banned generative AI based on security concerns.[ref 179] Several cities have banned law enforcement use of facial recognition based on privacy concerns.[ref 180] Illinois recently banned AI therapy chatbots out of concern for user safety.[ref 181] Recently proposed legislation in Tennessee would make it a felony to train a language model to “provide emotional support, including through open-ended conversations with a user.”[ref 182]
Advantages of Targeting This Stage
Regulating at the application layer gives lawmakers maximum context about AI-related harms. Because deployers operate in defined settings, regulators can set outcome-oriented requirements (i.e., maximum error rates for medical diagnosis or bias thresholds for hiring) and verify through real-world data that requirements are reducing harms.
This approach strongly aligns with existing regulatory expertise. Sector agencies like the FDA, NHTSA, EEOC, and SEC already police safety and integrity within their domains. Extending their mandates to cover AI-enabled products leverages existing staff, testing protocols, and enforcement tools. In many cases, new legislation may not be required because existing sector-specific laws and agency authorities can be applied to AI.
Disadvantages of Targeting This Stage
Effective application-layer intervention requires coordinating across many industries, each with its own stakeholders and lobbyists who may resist oversight. While sector-specific legislation may be more precise, policymakers may prefer omnibus “AI bills” for political reasons, since a single high-profile bill can yield greater electoral rewards than piecemeal legislation.
Even with political will for sector-specific regulation, different agencies crafting different rules creates fragmentation. AI applications that don’t fit neatly into existing categories may slip through gaps. Products crossing regulatory boundaries—a health chatbot handling both insurance questions and medical advice—may face overlapping or conflicting obligations.
A further concern is regulatory capture. Sector regulators develop close relationships with the industries they oversee; over time, this can blunt enforcement or slow rule updates as technology evolves.
Summary
The application layer is one of the most promising regulatory targets because deployers operate in concrete settings where harms are observable and measurable, and because many enforcement agencies—the FTC, EEOC, FDA, NHTSA—already have authority to regulate AI-related activities without new legislation. It is less effective when products span multiple regulatory domains, creating gaps and inconsistencies between agencies.
The least-cost-avoider principle is useful here: deployers who control application design and the context in which AI capabilities reach users should bear responsibility for design flaws and foreseeable failures, while liability for sophisticated misuse that deployers could not reasonably anticipate or prevent should shift to end users.
F. Stage 6: Complementary and Enabling Platforms
Platforms are often essential for translating digital outputs into real-world consequences. E-commerce marketplaces like Amazon facilitate physical goods purchases; gig economy platforms like TaskRabbit connect requesters with workers who perform physical tasks; social media networks like Meta distribute content to mass audiences. While these platforms may not develop AI themselves, they can serve as essential channels through which AI-enabled harms materialize. A language model requires access to enabling infrastructure to purchase precursor chemicals, hire a courier, or broadcast disinformation.
This intermediary role makes enabling platforms uniquely important for AI governance. They represent the last major chokepoint before harm occurs, operating at the boundary between digital intent and physical or social consequence.
Examples of Policy Interventions
E-commerce and Procurement Platforms
Know-Your-Customer and suspicious activity reporting. Platforms could be required to verify purchaser identities for certain categories of goods (chemicals, laboratory equipment, dual-use materials) and report suspicious purchasing patterns to relevant authorities, similar to banking regulations under the Bank Secrecy Act.[ref 183]
AI-aware transaction monitoring. As AI agents gain the ability to autonomously browse and purchase goods, platforms may need new detection mechanisms. Jonathan Zittrain has proposed that AI agents carry identifying credentials—akin to “license plates”—that would allow platforms to apply heightened scrutiny to agent-initiated transactions, particularly for sensitive goods categories.[ref 184]
Gig Economy and Labor Platforms
Task screening and identity verification. Platforms like TaskRabbit, Fiverr, and Upwork could be required to maintain explicit prohibitions on tasks that facilitate illegal activity—delivering unknown substances, conducting surveillance, accessing restricted areas—and to require enhanced identity verification for task categories with higher abuse potential.
Worker protection and refusal rights. Gig workers may be unwitting participants in harmful schemes.[ref 185] Regulations could guarantee workers the right to refuse suspicious tasks without penalty and require platforms to maintain reporting channels for workers who suspect they are being used for illicit purposes.[ref 186]
Social Media and Content Distribution Platforms
Synthetic content labeling requirements. Building on recent state laws, policymakers could mandate that AI-generated content be labeled when distributed on social media,[ref 187] including technical standards for embedded metadata (such as C2PA provenance standards)[ref 188] and disclosure requirements for accounts that post primarily AI-generated content.[ref 189]
Amplification accountability. Beyond content moderation, platforms could face obligations related to algorithmic amplification—transparency requirements for recommendation algorithms, prohibitions on amplifying content that violates platform policies, or duties to detect coordinated inauthentic behavior.
Section 230 reform. The most significant potential intervention involves modifying Section 230 of the Communications Decency Act, which currently immunizes platforms from liability for user-generated content.[ref 190] Reform proposals range from narrow carve-outs (removing immunity for algorithmically amplified content) to broader conditions (requiring reasonable content moderation as a prerequisite for immunity).[ref 191]
Advantages of Targeting This Stage
These platforms represent the final major chokepoint before harms materialize. Even if upstream interventions fail, enabling platforms can still prevent the final step. A bioweapon cannot be synthesized without ingredients; an influence campaign cannot succeed without distribution.
Additionally, unlike AI-specific entities, enabling platforms already operate under extensive regulatory frameworks (e.g., consumer protection laws, export controls, anti-money-laundering rules). Extending these frameworks to address AI-enabled harms leverages established compliance capabilities.
Finally, platform intermediation creates records that facilitate both ex ante screening (flagging suspicious patterns) and ex post investigation (reconstructing how harm materialized).
Disadvantages of Targeting This Stage
The sheer volume of platform activity is the first challenge. Major platforms process billions of transactions.[ref 192] Any screening system will produce false positives and false negatives; at scale, even low error rates translate into millions of affected transactions.
Even with effective screening, platforms often cannot determine whether a transaction is AI-enabled. Without reliable signals distinguishing human from agent activity, platforms cannot easily apply differential scrutiny.[ref 193] Requiring AI disclosure depends on the honesty of precisely those actors least likely to comply when pursuing harmful ends.
Content-related interventions face an additional obstacle. For social media platforms, content-based regulations face significant constitutional scrutiny under the First Amendment. Requirements to remove or label certain categories of speech must be narrowly tailored to compelling government interests.
Finally, users seeking to evade restrictions can shift to less-regulated platforms, international services, or decentralized alternatives like cryptocurrency marketplaces or federated social networks.
Summary
Enabling platforms are most valuable as intervention targets when harms require real-world resources or distribution that platforms mediate. They are the last major chokepoint where harms can be intercepted, and they benefit from existing compliance infrastructure that can be extended to AI-specific concerns. Platform-level interventions are less effective when users can easily shift to unregulated alternatives; they also face significant First Amendment constraints for content-related regulations. The least-cost-avoider principle suggests platforms should bear responsibility for harms they are well-positioned to prevent: suspicious purchasing patterns, task requests that facially violate policies, and content that clearly meets removal criteria. But platforms are not well-positioned to prevent harms requiring information they lack or judgment calls they cannot reliably make at scale.
G. Stage 7: End Users
End users are the final actor in the AI ecosystem. Institutional users like businesses and government agencies embed AI tools into existing workflows, often under sector-specific laws. Individual users typically lack formal compliance programs or resources to vet AI systems, yet their choices can still inflict measurable harm and are subject to liability under the tort system.[ref 194]
Examples of Policy Interventions
Organizations Using AI
Human oversight requirements. These require qualified people to oversee or override AI predictions.[ref 195] A bank using predictive AI for loan approvals might require a human loan officer to sign off on high-stakes decisions. The idea is that human oversight provides a fail-safe to catch errors or bias that AI systems might miss, though there are compelling critiques that people might simply rubber-stamp AI decisions.[ref 196] They are also called “human-in-the-loop” requirements.
Training and certification. Hospitals, financial firms, or law enforcement agencies might be required to obtain accredited licenses or complete mandated coursework before deploying high-risk AI systems.
Record-keeping and audit trails. Organizations may need to log prompts, outputs, and decision rationales so regulators or litigants can reconstruct how harmful decisions occurred.
Individuals Using AI
Use existing tort law to find liability. Many harms individuals can inflict with AI—hacking, defamation, malpractice—are already covered by criminal statutes, tort principles, or professional ethics rules.[ref 197] Even if the tool changes (AI), the duty does not. For example, a lawyer must still verify citations whether they come from Westlaw or a language model. State attorneys general and other entities authorized to enforce laws can reinforce this through guidance and sanctions without creating new technology-specific offenses.
Create AI-specific duties for genuine gaps. Where existing law does not squarely address new harms, legislatures can craft targeted rules—criminalizing non-consensual AI-generated intimate imagery or requiring disclosure for synthetic political ads depicting candidates saying things they never said.[ref 198]
Advantages of Targeting This Stage
End-user liability puts accountability on the actor often best positioned to prevent harm. The individual or organization that chooses to post a deepfake, ignore a safety warning, or rely blindly on AI output controls the immediate risk and can avoid it at low cost—by double-checking facts, limiting sensitive prompts, or declining to deploy AI in high-stakes contexts.
Focusing sanctions at the user layer also protects upstream innovation. Model developers and application builders can continue releasing general-purpose tools without bearing the full weight of every possible downstream abuse, because liability attaches only when users turn tools toward prohibited or negligent uses.
Finally, user-level liability also carries expressive value. By singling out certain AI-enabled acts as punishable—non-consensual synthetic pornography, fraudulent legal filings, deceptive political ads—the law signals which uses of AI violate shared norms, helping shape social expectations in a fast-moving technological landscape.
Disadvantages of Targeting This Stage
End-user liability is inherently retroactive: it activates only after harm has occurred. For irreversible injuries—viral deepfakes that permanently taint reputations, election disinformation that cannot be “un-voted,” psychological trauma from non-consensual intimate images—damages or takedowns arrive too late to help those already harmed.
Identifying individual bad actors is also logistically difficult. Malicious users can automate anonymous accounts, route traffic through foreign servers, or hide behind encryption, making attribution expensive or impossible. Enforcement may depend on platforms or foreign authorities with their own incentives and delays, and plaintiffs face steep proof burdens for causation, while prosecutors must establish intent beyond reasonable doubt.
First Amendment constraints present additional obstacles when regulations target individual expression. Penalties for AI-generated content must be drafted to avoid viewpoint discrimination and unconstitutional vagueness.
Finally, aggressive liability risks over-deterrence. If users fear ambiguous civil suits or criminal charges, journalists may shy away from probing models to expose bias, artists may forgo transformative remixes, and small businesses may abandon useful automation rather than gamble on uncertain legal boundaries.
Summary
End-user interventions work best when harms result from intentional misuse and the likelihood of effective deterrence is high. They are less useful when offenders are hard to identify or influence (foreign disinformation operators, anonymous bad actors). To strengthen deterrence, policymakers can offer multiple independent enforcement mechanisms (government action plus private rights of action) and impose high statutory penalties. The least-cost-avoider principle can be helpful here: where the user’s choice is the proximate cause of harm, liability should follow.
Conclusion
AI policy is difficult. The technology is general-purpose, fast-moving, and embedded in an ecosystem of actors with overlapping roles and responsibilities. But difficulty is no excuse for imprecision. This primer has argued that effective AI regulation requires specificity along three dimensions: the harm being addressed, the design principles guiding the intervention, and the stage of the AI lifecycle being targeted.
These choices inevitably involve tradeoffs. Preventive interventions reduce irreversible harms but risk being overbroad. Upstream regulations offer leverage over the entire ecosystem but are too blunt to address application-specific problems. Targeting the least-cost avoider is efficient but may concentrate compliance burdens on a small number of firms. No single intervention can address all AI harms, and most will implicate competing values.
This primer does not resolve those tradeoffs—nor could it, given how much depends on context, values, and the specific harm at issue. What it offers instead is a framework for confronting them with greater clarity. Policymakers who can specify which harm they are addressing, justify the regulatory design they have chosen, and identify where in the AI ecosystem their intervention will take effect are better positioned to write laws that are effective, proportionate, and durable.
Superintelligence and Law
Abstract
The prospect of artificial superintelligence—AI agents that can generally outperform humans in cognitive tasks and economically valuable activities—will transform the legal order as we know it. Operating autonomously or under only limited human oversight, AI agents will assume a growing range of roles in the legal system. First, in making consequential decisions and taking real-world actions, AI agents will become de facto subjects of law. Second, to cooperate and compete with other actors (human or non-human), AI agents will harness conventional legal instruments and institutions such as contracts and courts, becoming consumers of law. Third, to the extent AI agents perform the functions of writing, interpreting, and administering law, they will become producers and enforcers of law. These developments, whenever they ultimately occur, will call into question fundamental assumptions in legal theory and doctrine, especially to the extent they ground the legitimacy of legal institutions in their human origins. Attempts to align AI agents with extant human law will also face new challenges as AI agents will not only be a primary target of law, but a core user of law and contributor to law. To contend with the advent of superintelligence, lawmakers—new and old—will need to be clear-eyed, recognizing both the opportunity to shape legal institutions as society braces for superintelligence and the reality that, in the longer run, this may be a joint human-AI endeavor.
How to Count AIs: Individuation and Liability for AI Agents
Abstract
Very soon, millions of AI agents will proliferate across the economy, autonomously taking billions of actions. Inevitably, things will go wrong. Humans will be defrauded, injured, even killed. Law will somehow have to govern the coming wave. But when an AI causes harm, the first question to answer before anyone can be held accountable is: Which AI Did It?
Identifying AIs is unusually difficult. AIs lack bodies. They can copy, split, merge, and swarm at will. Even today, a “single” AI agent is often an ensemble of instances based on multiple models. The complexity will only multiply as AI capabilities improve.
This Article is the first to comprehensively diagnose the legal problem of identifying AIs. For AI agents to be effectively governed, the Article argues, two kinds of identity are required: “thin” and “thick.” Thin identification is the project of tying every action taken by an AI to some human principal. Thin identity will be essential for law to hold accountable the humans who make and use AI agents. Thick identification is the project of distinguishing between AI agents, qua agents. It requires sorting millions of AI entities into discrete, persistent units with stable, coherent goals. Thick identity is essential for governing AIs’ behavior directly in the many contexts where principal–agent problems prevent humans from perfectly controlling AIs.
The Article is also the first to present a solution to the twin identity problem. We call it the “Algorithmic Corporation” or “A-corp,” a legal-fictional entity that can hold property, make contracts, and litigate in its own name. An A-corp is owned by humans. But it is designed to be run by AIs. The A-corp solves the thin identity problem by tying AI actions to a human owner. And it solves the thick identity problem via emergent self-organization. A-corps will own the resources which AIs need to accomplish their goals. AIs that control A-corps will thus have strong incentives to share control only with other AIs that share their goals. In equilibrium, both incentive and selection mechanisms will force A-corps to self-organize into persistent, legally legible entities with coherent underlying goals. These coherent, agentic entities will respond rationally to legal incentives, like liability.
Legal Alignment for Safe and Ethical AI
Abstract
Alignment of artificial intelligence (AI) encompasses the normative problem of specifying how AI systems should act and the technical problem of ensuring AI systems comply with those specifications. To date, AI alignment has generally overlooked an important source of knowledge and practice for grappling with these problems: law. In this paper, we aim to fill this gap by exploring how legal rules, principles, and methods can be leveraged to address problems of alignment and inform the design of AI systems that operate safely and ethically. This emerging field — legal alignment — focuses on three research directions: (1) designing AI systems to comply with the content of legal rules developed through legitimate institutions and processes, (2) adapting methods from legal interpretation to guide how AI systems reason and make decisions, and (3) harnessing legal concepts as a structural blueprint for confronting challenges of reliability, trust, and cooperation in AI systems. These research directions present new conceptual, empirical, and institutional questions, which include examining the specific set of laws that particular AI systems should follow, creating evaluations to assess their legal compliance in real-world settings, and developing governance frameworks to support the implementation of legal alignment in practice. Tackling these questions requires expertise across law, computer science, and other disciplines, offering these communities the opportunity to collaborate in designing AI for the better.
Automated Compliance and the Regulation of AI
Abstract
Regulation imposes compliance costs on regulated parties. Thus, policy discourse often posits a trade-off between risk reduction and innovation. Without denying this trade-off outright, this paper complicates it by observing that, under plausible forecasts of AI progress, future AI systems will be able to perform many compliance tasks cheaply and autonomously. We call this automated compliance. While automated compliance has important implications in many regulatory domains, it is especially important in the ongoing debate about the optimal timing and content of regulations targeting AI itself. Policymakers sometimes face a trade-off in AI policy between potentially regulating too soon or strictly (and thereby stifling innovation and national competitiveness) versus too late or leniently (and thereby risking preventable harms). Under plausible assumptions, automated compliance loosens this trade-off: AI progress itself hedges the costs of AI regulation. Automated compliance implies that, for example, policymakers could reduce the risk of premature regulation by enacting regulations that become effective only when AI is capable of largely automating compliance with such regulations. This regulatory approach would also mitigate concerns that regulations may unduly benefit larger firms, which can bear compliance costs more easily than startups can. While regulations can remain costly even after many compliance tasks have become automated, we hope that the concept of automated compliance can enable a more multidimensional and dynamic discourse around the optimal content and timing of AI risk regulation.
Policy Implications
- AI progress will reduce the cost of certain regulatory compliance tasks.
- Policymakers can reduce risks from premature regulation by using “automatability triggers” to stipulate that regulations become effective only when AI tools are capable of automating compliance with such regulations.
- Proper implementation of compliance-automating AI workflows may provide evidence of regulatory compliance.
- Targeted measures can support the development of compliance-automating AI services.
- Automated compliance is most effective when complemented by the responsible automation of regulator-side regulatory and oversight tasks.
Introduction
Few contest that rapid advances in artificial intelligence (AI) capabilities and adoption will require regulatory intervention. Instead, some of the deepest disagreements in AI policy concern the general timing, substance, and purpose of those regulations. The stakes, most agree, are high.[ref 1] Those more concerned with risks from AI worry about, for example, risks from misuse of AI systems to make weapons of mass destruction,[ref 2] from strategic destabilization,[ref 3] and from loss of control of advanced AI systems that are not aligned with humanity.[ref 4] In turn, some individuals with this perspective have called for a more aggressive regulatory posture aimed at reducing the odds of worst-case scenarios.[ref 5] Those who are focused on the benefits of AI systems point out that there is a large amount of uncertainty as to the likelihood of these risks and regarding best practices for risk mitigation.[ref 6] They also champion the potential of such systems to drive innovations in medicine and other areas of science,[ref 7] to supercharge economic growth more generally,[ref 8] and to enable strategic applications that could determine the balance of global power.[ref 9] The regulatory posture of these individuals tends to be more hands-off out of a concern for early regulations entrenching existing actors and perhaps leading to technological path dependence.[ref 10]
Both perspectives simultaneously find some support from the observed characteristics of currently deployed AI systems[ref 11] but are also necessarily based on a forecast of a large number of uncertain variables, including the trajectories of AI capabilities, societal adaptation, international relations, and public policy. As a result of these disagreements and uncertainties, perspectives on the appropriate course of action range widely, from, at one pole, unilateral or coordinated “pausing” of AI progress,[ref 12] to, at the other pole, deregulation and acceleration of AI progress.[ref 13] We might call this the proregulatory–deregulatory divide.[ref 14]
The foregoing is an oversimplified sketch of what is in fact a much more multidimensional debate. Innovation and regulation are not always zero-sum.[ref 15] People—including both authors of this article—tend to hold a combination of proregulatory and deregulatory views depending on the exact AI policy issue. Many policies are preferable under both views; other policies complicate or straddle the divide. Others question whether proregulation versus deregulation is even the right frame for this debate at all.[ref 16] Semantics aside, the fundamental tension between proregulatory and deregulatory approaches to AI policy is, in many cases, real. Indeed, at the risk of oversimplifying our own views, the authors generally locate themselves on opposite sides of the proregulatory–deregulatory divide.[ref 17]
There are many causes of the proregulatory–deregulatory divide, including empirical disagreements about the likely impacts of future AI systems and normative disagreements about how to value different policy risks or outcomes. We do not attempt to resolve these here. We do, however, note one reason to think that the trade-offs between the proregulatory and deregulatory approaches may not remain as harsh as they presently seem: future AI systems will likely be able to automate many compliance tasks, including many required by AI regulations.[ref 18] We can call these compliance-automating AIs. Compliance-automating AIs will be able to, for example, perform automated evaluations of AI systems, compile transparency reports of AI systems’ performance on those evaluations, monitor for safety and security incidents, and provide incident disclosures to regulators and consumers.[ref 19]
Compliance-automating AIs deserve a larger role in the discussion of regulation across all economic sectors.[ref 20] But their implications for regulation of AI itself warrant special attention. This is for two reasons. First, as detailed above, the stakes of AI policy are immense, with weighty considerations on both sides of the proregulatory–deregulatory divide. Compliance-automating AI will affect the costs of AI regulation and therefore be an increasingly important input into the overall cost-benefit analysis of proposed regulations of this important sector. Second, AI policy is unique in that compliance-automating AI can both influence and be influenced by AI policy. As mentioned, the availability of compliance-automating AI will influence the cost-benefit profile of many AI policies, and therefore, one hopes, whether and when such policies are implemented. But AI policies, in turn, will also influence whether and when compliance-automating AI is developed. The interaction between compliance-automating AI and policy is therefore much more complicated in AI than in other policy domains.
This paper proceeds as follows. In Part I, we briefly note the potentially high costs associated with regulatory compliance. In Part II, we survey how current AI policy proposals attempt to manage compliance costs. In Part III, we introduce the concept of automated compliance: a prediction that, as AI capabilities advance, AI systems will themselves be capable of automating some regulatory compliance tasks, leading to reduced compliance costs.[ref 21] In Part IV, we note several implications of automated compliance for the design of AI regulations. First, we propose the novel concept of automatability triggers: regulatory mechanisms that specify that AI regulations become effective only when automation has reduced the costs to comply with regulations below a predetermined level. Second, we note how AI policies could use automated compliance as evidence of compliance. Third, we identify several tasks policymakers, entrepreneurs, and civic technologists could take to accelerate automated compliance. Finally, we note the possible synergies between automated compliance and automated governance.
I. Regulatory Costs
Regulation can be very costly to the regulated party, the regulator, and (therefore) the economy as a whole. While a holistic survey of the potential costs associated with regulation is well beyond the scope of this paper,[ref 22] we briefly note some data points indicating the potential costs of regulation.
Compliance costs are perhaps the most easily observable costs. By “compliance costs,” we mean “the costs that are incurred by businesses . . . at whom regulation may be targeted in undertaking actions necessary to comply with the regulatory requirements, as well as the costs to government of regulatory administration and enforcement.”[ref 23] This includes both administrative costs (e.g., the costs associated with producing and processing paperwork required by regulation) and substantive costs (e.g., the costs associated with reengineering a product to comply with substantive standards imposed by regulation).[ref 24]
To take just a few examples:
- The state of California estimated that initial compliance costs for the California Consumer Privacy Act totaled approximately $55 billion.[ref 25]
- A large share of the increased costs of generating nuclear power is due to increased (and changing) safety regulations.[ref 26] For example, quality control and quality assurance requirements cause there to be a “nuclear premium” for commodity components of nuclear power plants.[ref 27] The nuclear premium has been estimated at 23% of the cost of concrete and 41% of the cost of steel in nuclear plants.[ref 28]
- Financial crime compliance costs in the US and Canada are estimated at $61 billion,[ref 29] becoming major cost centers for financial institutions.[ref 30]
- One paper estimates that “[a]n average firm spends 1.34 percent of its total labor costs on performing regulation-related tasks.”[ref 31]
Regulations also impose costs on the government, such as the costs associated with promulgating regulation, bringing enforcement actions, and adjudicating cases.[ref 32] California Governor Gavin Newsom recently vetoed[ref 33] AB 1064, which would have regulated companion chatbots made available to minors.[ref 34] A previous version of the bill would have established a Kids Standards Board,[ref 35] which would have cost the state “between $7.5 million and $15 million annually.”[ref 36] To take another infamous example, consider the National Environmental Policy Act (NEPA),[ref 37] which, inter alia, requires the federal government to prepare an environmental impact statement (EIS) prior to “major Federal actions significantly affecting the quality of the human environment.”[ref 38] These EISs have grown to become incredibly burdensome, with a 2014 report from the Government Accountability Office estimating that the average EIS took 1,675 days to complete[ref 39] and cost between $250,000 and $2 million.[ref 40]
It is also worth considering the opportunity costs associated with regulation. Regulation requires firms to divert resources away from their most productive use.[ref 41] The opportunity cost of a regulation to a firm is therefore the difference between the return the firm would have earned from its most productive use of resources dedicated to compliance and the return those resources in fact earned.[ref 42] While more difficult to observe than compliance costs, opportunity costs may be significantly larger over time due to compounding growth.[ref 43] Opportunity costs also include the cost to consumers when regulations prevent a product from reaching the market. For example, a working paper found that the European Union’s (EU’s) General Data Protection Regulation (GDPR) “induced the exit of about a third of available apps” on the Google Play Store, ultimately reducing consumer surplus in the app market by about a third.[ref 44]
Finally, regulation can have strategic costs not easily captured in economic terms. A number of commentators worry that overregulation of AI in the US could cause the US to lose its lead in AI research and development to foreign competitors, especially China.[ref 45] Of course, China for its part has hardly taken a laissez-faire attitude toward its domestic AI industry.[ref 46] Nevertheless, it is reasonable to carefully consider international competitiveness when evaluating domestic regulatory proposals.
To be clear, this paper does not argue that the potentially high costs of regulation are a conclusive argument against any particular regulatory proposal. Regulations often have pro tanto benefits, and such benefits must be weighed against costs to decide whether the regulation is socially beneficial on net.[ref 47] Nor is this intended to be a comprehensive survey of regulatory burdens. We are merely restating the banal observation that regulations can come at significant cost to societal goods. Any serious discussion of AI policy must be willing to concede that point and entertain approaches to capturing the benefits of well-designed regulation at lower cost to producers, consumers, and society as a whole.
II. Current Approaches to Managing Compliance Costs in AI Policy
Regulators and policy entrepreneurs often make some efforts to reduce the costs associated with regulation. Traditional regulatory literature often proposes using performance-based regulation, which requires regulated parties to achieve certain results rather than use certain methods or technologies, on the logic that performance-based standards allow the regulatees to find and adopt more efficient methods of achieving compliance.[ref 48] Tort-based approaches to AI policy[ref 49] similarly incentivize firms to identify and implement the most effective means for reducing actionable harms from their systems.[ref 50]
Nevertheless, there remains substantial interest in prescriptive regulation for AI.[ref 51] To date, the most carefully designed proregulatory proposals have tended to use some method for regulatory targeting to attempt to limit regulatory costs to only those firms that are both (a) engaging in the riskiest behaviors and (b) best able to bear compliance costs. Early proposals tended to rely on compute thresholds, wherein only AI models that were trained using more than a certain number of computational operations would be regulated.[ref 52] A number of proposed and enacted laws and regulations have used compute thresholds for this reason:
- The EU AI Act states that “A general-purpose AI model shall be presumed to have high impact capabilities . . . when the cumulative amount of computation used for its training measured in floating point operations is greater than 1025.”[ref 53]
- Regulations proposed under the Biden administration would have required AI companies to report the development of “dual-use foundation models,” which were in turn defined as models that “utilize[] more than 1026 computational operations (e.g., integer or floating-point operations).”[ref 54]
- The much-debated—and ultimately vetoed[ref 55]—California SB 1047[ref 56] would have initially[ref 57] applied to models that were “trained using a quantity of computing power greater than 1026 integer or floating-point operations, the cost of which exceeds one hundred million dollars . . . .”[ref 58]
- California’s recently enacted SB 53[ref 59]—a successor to SB 1047 focused on transparency—defines “frontier model” as “a foundation model that was trained using a quantity of computing power greater than 1026 integer or floating-point operations.”[ref 60]
Compute-based thresholds are a reasonable proxy for the financial and operational resources needed to comply with regulation because compute (in the amounts typically proposed) is expensive: when proposed in 2023, the 1026 operations threshold corresponded to roughly $100 million in model training costs.[ref 61] Any firm using such amounts of compute will necessarily be well-capitalized. Training compute is also reasonably predictive of model performance,[ref 62] so compute thresholds target only the most capable models reasonably well.[ref 63] Of course, improvements in compute price-performance[ref 64] will steadily erode the cost needed to reach any given compute threshold. This is why some proposals, like SB 1047’s, use a conjunctive test, wherein regulation is only triggered if the cost to develop a covered model surpasses both an operations-based and a dollar-based threshold.
However, newer AI paradigms, such as reasoning models, have complicated the relationship between training compute and AI capabilities.[ref 65] Thus, more recent proposals have also argued for regulatory targeting based not on training compute, but rather on some entity-based threshold, as measured by the total amount an AI company spends on AI research or compute (including both training and inference compute).[ref 66]
III. Automated Compliance
This paper does not suggest abandoning existing approaches to managing regulatory costs in AI policy. It does, however, suggest that such approaches are insufficiently ambitious in the era of AI. In particular, we think that existing approaches often ignore the extent to which AI technologies themselves could reduce regulatory costs by largely automating compliance tasks.[ref 67]
Compliance professionals already report significant benefits from the use of AI tools in their work,[ref 68] and there is no shortage of companies claiming to be able to automate core compliance tasks.[ref 69] Such claims must of course be treated with appropriate skepticism, coming, as they do, from companies trying to attract customers. Nevertheless, the large amount of interest in existing compliance-automating AI suggests some reason for optimism.
The most significant promise for compliance automation, however, comes from future AI systems. AI companies are developing agentic AI systems: AI systems that can competently perform an increasingly broad range of computer-based tasks.[ref 70] If these companies succeed, then AI systems will be able to autonomously perform an increasingly broad range of computer-based compliance tasks[ref 71]—possibly more quickly, reliably, and cheaply than human compliance professionals.[ref 72] We can call this general hypothesis—that future AI systems will be able to automate many core compliance tasks—automated compliance.
Automated compliance has significant implications for the proregulatory–deregulatory debate within AI policy.[ref 73] Before exploring the implications of automated compliance, however, we should be clear about its content. Not all compliance tasks are equally automatable. Unfortunately, we cannot here provide a comprehensive account of which compliance tasks are most automatable.[ref 74] However, we can provide some initial, tentative thoughts on which compliance tasks might be more or less automatable.
To start, recall that we limited our definition of “agentic AI” to “AI systems that can competently perform an increasingly broad range of computer-based tasks.”[ref 75] Thus, by definition, agentic AI would only be able to automate computer-based compliance tasks; those requiring physical interactions would remain non-automatable.[ref 76] An AI agent, under our definition, would not be able to, for example, provide physical security to a sensitive data center.[ref 77] Fortunately, many compliance tasks required by AI policy proposals would be computer-based; hence, this definitional constraint does not itself significantly limit the implications of automated compliance for AI policy. Consider the following processes that plausible AI safety and security policies might require:
- Automated red-teaming, in which AI models themselves attempt to “find flaws and vulnerabilities” in another AI system.[ref 78] Some frontier AI developers already use automated red-teaming as part of their safety workflows.[ref 79]
- Cybersecurity measures to prevent unauthorized access to frontier model weights.[ref 80] While cybersecurity has some inherently physical components (e.g., limitations on the types of hardware used, key personnel protection),[ref 81] many components of strong cybersecurity should be highly automatable in principle.[ref 82]
- Implementation of some AI alignment techniques. Some AI alignment techniques, such as reinforcement learning from human feedback,[ref 83] require significant human input. However, more recent techniques, such as constitutional AI,[ref 84] leverage AI feedback. Research into scalable forms of AI alignment, in which AI systems themselves are charged with aligning next-generation AI systems, is ongoing.[ref 85]
- Automated evaluations of AI systems on safety-relevant benchmarks.[ref 86]
- Automated interpretability,[ref 87] in which AI systems help us understand how other AI models make decisions, in human-comprehensible terms.[ref 88]
Importantly, automated compliance extends beyond computer science tasks. Advanced AI agents could also help reduce compliance costs by, for example:
- Keeping abreast of updates in the regulatory and legal landscape.[ref 89]
- Translating regulatory requirements into concrete changes to internal procedure.[ref 90]
- Filing mandated transparency reports.[ref 91]
- Designing and delivering employee training.[ref 92]
- Corresponding with regulators.[ref 93]
However, not all computer-based compliance tasks would be made much cheaper by AI agents.[ref 94] Some compliance tasks might require human input of some sort, which by its nature would not be automatable.[ref 95] For example, some forms of red-teaming “involve[] humans actively crafting prompts and interacting with AI models or systems to simulate adversarial scenarios, identify new risk areas, and assess outputs.”[ref 96] Automation may also be unable to reduce compliance costs associated with tasks that have an explicit time requirement. For example, suppose that a new regulation requires frontier AI developers to implement a six-month “adaptation buffer” during which they are not permitted to distribute the weights of their most advanced models.[ref 97] The costs associated with this calendar-time requirement could not be automated away. Nevertheless, there will be some compliance tasks that will be, to some significant degree, automatable by advanced AI agents.[ref 98]
To summarize, as AI capabilities progress, AI systems will themselves be able to perform an increasing fraction of compliance-related tasks.[ref 99] The simplest implication of automated compliance is that, holding regulation levels constant, compliance costs should decline relative to the pre-AI era.[ref 100] This is hardly a novel observation given the large number of both legacy firms and startups that are already integrating frontier AI technologies into their legal and compliance workflows.[ref 101] However, we think that automated compliance has even more significant implications for the design of optimal AI policy. We turn to those implications in the next section.
Figure 1: Automated Compliance illustrated. AI causes the cost to achieve any given level of safety assurance to decline.
IV. Implications of Automated Compliance for Policy Design
A. Automated Compliance and the Optimal Timing of Regulation
Automated compliance can reduce compliance costs associated with some forms of regulation. However, this is only true insofar as the AI technology necessary to automate compliance arrives before (or at least, simultaneously with) the regulatory requirements to be automated.
Thus, even those who agree with our prediction might still worry that automated compliance might become an excuse to implement costly regulation prematurely, in the expectation that technological progress will eventually reduce compliance costs. To be sure, such projections are often reasonable. For example, compliance costs for the Obama Administration’s Clean Power Plan[ref 102] were significantly lower than initially estimated due in large part to “[o]ngoing declines in the costs of renewable energy.”[ref 103] Nevertheless, when there are genuine concerns about the downsides of premature AI regulation, or simply outstanding uncertainties over the pace or cadence of further progress in compliance-automating AI applications, merely hoping that compliance automation technologies will eventually reduce excessive compliance costs imposed today may seem like a risky proposition.
This sequencing problem suggests a natural solution: certain AI safety policies could only be triggered when AI technology has progressed to the point where compliance with such policies is largely automatable. We could call such legal mechanisms automatability triggers.
Developing statutory language for automatability triggers must be left for future work, partly because such triggers need tailoring to their broader regulatory context. However, an illustrative example may help build intuition and catalyze further refinements. Consider a bill that would impose a fine on any person who, without authorization, exports[ref 104] the weights of a neural network if such neural network:
(a) was trained with an amount of compute exceeding [$10 million] at fair market rates,[ref 105] and
(b) can, if used by a person without advanced training in synthetic biology, either:
(i) reliably increase the probability of such person successfully engineering a pathogen by [50%], or
(ii) reduce the cost thereof by [50%],
in each case as evaluated against the baseline of such a person without access to such models but with access to the internet.[ref 106]
Present methods for assessing whether frontier AI models are capable of such “uplift” rely heavily on manual evaluations by human experts.[ref 107] This is exactly the type of evaluation method that could be manageable for a large firm but prohibitive for a smaller firm. And although $10 million is a lot of money for individuals, it seems plausible that there will be many firms that would spend that much on compute but for whom this type of regulatory requirement could be quite costly. Under our proposed approach, the legislature might consider an automatability trigger like the following:
The requirements of this Act will only come into effect [one month] after the date when the [Secretary of Commerce], in their reasonable discretion, determines that there exists an automated system that:
(a) can determine whether a neural network is covered by this Act;
(b) when determining whether a neural network is covered by this Act, has a false positive rate not exceeding [1%] and false negative rate not exceeding [1%];
(c) is generally available to all firms subject to this Act on fair, reasonable, and nondiscriminatory terms, with a price per model evaluation not exceeding [$10,000]; and,
(d) produces an easily interpretable summary of its analysis for additional human review.
This sample language is intended to introduce one way to incorporate an automatability trigger into law, and various considerations may justify alternative implementations or additional provisions. For example, concerns about disproportionate compliance costs being borne by smaller labs might justify a subsidy for the use of the tool. Similarly, lawmakers would need to consider whether to make the use of such a tool mandatory. Though it seems likely that most firms would prefer to adopt state-approved automated compliance tools, some may insist on doing things the “old-fashioned way.” Whether that option should be available to firms will likely depend on the extent to which alternative systems would frustrate the ability of the regulator to easily assess compliance. While surely imperfect in many ways, an automatability trigger like this could probably allay many concerns about the regulatory burdens associated with our hypothetical bill.[ref 108]
Automatability triggers could improve AI policy through two related mechanisms. First, of course, they reduce compliance costs throughout the entire time that a regulation is in force. But more importantly, they also aim to reduce the possibility of premature regulation: they allow AI progress to happen, unimpeded by regulation, until such time as compliance with such regulation would be much less burdensome than at present. Of course, the reverse is also true: automatability triggers might also increase the probability that AI regulations are implemented too late if the risk-producing AI capabilities arrive earlier than compliance-automating capabilities. Thus, the desirability of automatability triggers depends sensitively on policymakers’ preferences over regulating too soon or too late.
Automatability triggers also have key benefits over the primary approaches to controlling compliance costs within AI policy proposals: compute thresholds and monetary thresholds.[ref 109] Existing approaches tend not to (directly)[ref 110] control absolute costs of compliance, but rather tend to ensure that compliance costs are only borne by well-capitalized firms. Automatability triggers, by contrast, aim to cap compliance costs for all regulated firms.
The prospective enactment of automatability triggers in regulations also sends a useful signal to AI developers: it makes clear that there will be a market for compliance-automating AI and therefore incentivizes development towards that end. This, in turn, implies that trade-offs between safety regulation and compliance costs would loosen much more quickly than by default.
Finally, regulations that incorporate automatability triggers may prove far more adaptable and flexible than traditional, static regulatory approaches—a quality that most experts regard as essential for effective AI governance.[ref 111] Traditional rules often struggle to keep pace with rapid technological change, requiring lengthy amendment processes whenever new risks or practices emerge. By contrast, automatability triggers allow regulations to evolve in step with the development of compliance technologies. As automated compliance tools become more sophisticated, legislators and regulators could use them to focus on the precise types of information from labs that are most relevant to the regulatory issue at hand, rather than demanding broad, costly disclosures. This targeted approach not only reduces unnecessary burdens on regulated entities but also increases the likelihood that regulators receive timely, actionable data. Importantly, amendments to laws designed with automatability triggers would not require firms to reinvent their compliance systems from the ground up. Instead, updates would simply involve ensuring that the relevant information is transmitted through the approved compliance tools—making the regulatory framework more resilient, responsive, and sustainable over time.
Although the idea of automatability triggers is straightforward, their design might not be. Policymakers would need to be able to define and measure the cost-reducing potential of AI technologies. This seems difficult to do even in isolation; ensuring that such measures accurately predict the cost-savings realizable by regulated firms seems more difficult still.
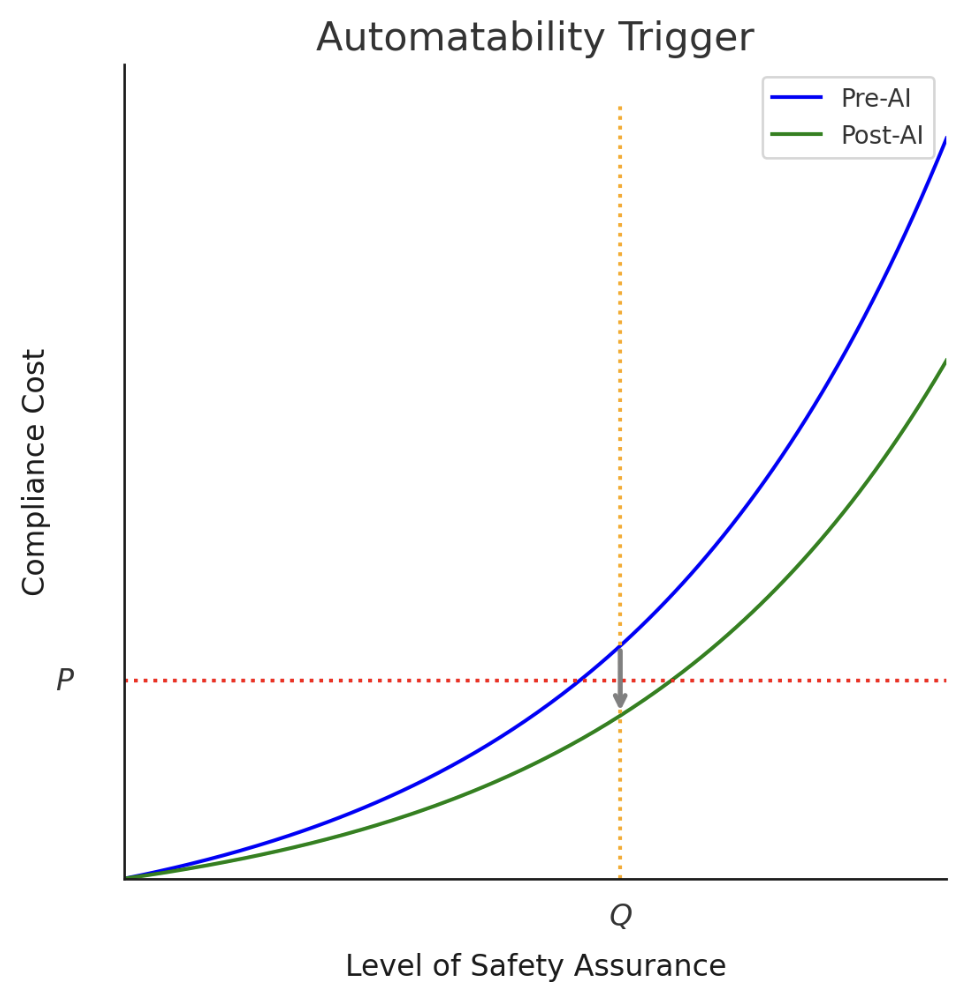
Figure 2: Automatability Triggers illustrated. A regulation that provides safety assurance level Q is implemented with an automatability trigger at P: the regulation is only effective when the cost to implement the regulation falls below P. Regulated parties are thus guaranteed to always have compliance costs below P.
B. Adoption of Compliance-Automating AI as Evidence of Compliance
Automatability triggers assume that regulators can competently identify AI services that, if properly adopted, enable regulated firms to comply with regulations at an acceptable cost. If so, then we might also consider a legal rule that says that regulated firms that properly implement such “approved” compliance-automating AI systems are presumptively (but rebuttably) entitled to some sort of preferential treatment in regulatory enforcement actions. For example, such firms might be inspected less frequently or less invasively than firms that have not implemented approved compliance-automating AI systems. Or, in enforcement actions, they might be entitled to a rebuttable presumption that they were in compliance with regulations while using such systems.[ref 112] Or a statute might provide that proper adoption of such a system is conclusive evidence that the firm was exercising reasonable care so as to preclude negligence suits.
Of course, it is important that such safe harbors be carefully designed. They should only be available to firms that were properly implementing compliance-automating AI. This would also mean denying protection to firms who, for example, provided incomplete or misleading information to the compliance-automating AI or knowingly manipulated it, causing it to falsely deem the firm to be compliant. Compliance-automating AIs, in turn, should ideally be robust to such attempts at manipulation. Regulators would also need to be confident that, if properly implemented, compliance-automating AI systems really would achieve the desired safety results in deployment settings. Finally, in the ideal case, regulators would ensure that the market for compliance-automating AI services is competitive; reliance on a small number of vendors who can set supracompetitive prices would reduce the cost-saving potential of compliance-automating AI and concentrate its benefits among the firms with deeper pockets. For example, perhaps regulators could accomplish this by only implementing such an approval regime if there were multiple compliant vendors.[ref 113]
C. Differential Acceleration of Automated Compliance
Automated compliance can be analyzed through the lens of “risk-sensitive innovation”: a strategy for deliberately structuring the timing and order of technological advances to “reduce specific risks across a technology portfolio.”[ref 114] Targeted acceleration of the development of compliance-automating AI systems could reduce painful trade-offs between safety and innovation in a very fraught and uncertain policy environment. It is therefore worth considering what, if anything, AI policy actors can do to differentially accelerate automated compliance.
Of course, there will be a natural market incentive to develop such technologies: regulated parties will need to comply with regulations and will be willing to pay anyone that can reduce the costs of compliance. Indeed, we have mentioned some examples of how firms are already using AI to reduce compliance costs.[ref 115] But prosocial actors may be able to further accelerate automated compliance by, for example:[ref 116]
- Building curated data sets that would be useful for creating compliance-automating AI systems.[ref 117]
- Subsidizing compute access for developers attempting to build compliance-automating AI systems.[ref 118]
- Building proof-of-concept compliance-automating AI systems for existing regulatory regimes.
- Preferentially developing and advocating for AI policy proposals that are likely to be more automatable.
- Educating policymakers on which types of regulations are more likely to be compatible with regulatory compliance.
- Instituting monetary incentives, such as advance market commitments, for compliance-automating AI applications.[ref 119]
- Ensuring that firms working on automated compliance have early access to restricted AI technologies.[ref 120]
- Building AI systems that automate key technical AI safety tasks that might be required by AI safety regulation, such as those listed above.[ref 121]
- Building AI systems that automate key non-technical legal and compliance tasks, such as those listed above.[ref 122]
D. Automated Compliance Meets Automated Governance
So far, we have been focusing on the costs and benefits to regulated parties. However, automated compliance might be especially synergistic with automation of core regulatory and administrative processes.[ref 123] For example, regulatory AI systems would be well-positioned to know how proposed regulations would affect regulated companies and could therefore be used to write responses to proposed rules.[ref 124] Regulatory AI systems, in turn, could compile and analyze these comments.[ref 125] Indeed, AI systems might be able to draft and analyze many more variations of rules than human-staffed bureaucracies could,[ref 126] thus enabling regulators to receive and review in-depth, tailored responses to many possible policies and select among them more easily.
Compliance-automating AI systems could also request guidance from regulatory AI systems, who could review and respond to the request nearly instantaneously.[ref 127] Such guidance-providing regulatory AI systems could be engineered to ensure that business information disclosed by the requesting party was stored securely and never read by human regulators (unless, perhaps, such materials became relevant to a subsequent dispute), thus reducing the risk that the disclosed information is subsequently used to the detriment of the regulated party.
Of course, there are many governance tasks that should remain exclusively human, and automating core governance tasks carries its own risks.[ref 128] But future AI systems could offer significant benefits to both regulators and regulatees alike, and may be even more beneficial still when allowed to interact with each other according to predetermined rules designed to mitigate the potential for abuse by either party.
Conclusion
AI systems are capable of automating an increasingly broad range of tasks. Many regulatory compliance tasks will be similarly automatable. This insight has important implications for the ongoing debate about whether and how to regulate AI. On the one hand, forecasts of regulatory compliance costs will be overstated if they fail to account for this fact; AI progress itself hedges the costs of many forms of AI regulation. Regulatory design should account for this dynamic. However, to maximize the benefits of automated compliance, regulators must successfully navigate a tricky sequencing problem. If regulations are triggered too soon—that is, before compliance costs have fallen sufficiently—they will hinder desirable forms of AI progress. On the other hand, if they are triggered too late—that is, after the risks from AI would justify the regulations—then the public may be exposed to excessive risks from AI. Smart AI policy must be attentive to these dynamics.
To be clear, our claim is fairly modest: AI progress will reduce compliance costs in some cases. Automated compliance is only relevant when compliance tasks are in fact automatable, and not all compliance tasks will be. Accordingly, the costs of some forms of AI regulation might remain high, even if many compliance tasks are automated. And of course, regulations are only justified when their expected benefits outweigh their expected costs. Furthermore, regulations have costs in excess of their directly measurable compliance costs;[ref 129] these costs are no less real than are compliance costs. The availability of compliance-automating AI should not be used as an excuse to jettison careful analysis of the costs and benefits of regulation. Nevertheless, AI policy discourse should internalize the fact that AI progress implies reduced compliance costs, all else equal, due to automated compliance.
Treaty-Following AI
Abstract
Advanced AI agents raise significant challenges to global stability, cooperation, and international law. States increasingly face pressure to manage the geopolitical, safety and security risks such agents give rise to. Yet advanced AI agreements for these systems face significant hurdles, including potentially unpalatable compliance monitoring requirements, and the ease with which states or their ‘lawless’ AI agents might exploit legal loopholes. This article introduces a novel commitment mechanism for states: Treaty-Following AI (TFAI). Building on recent work on “Law-Following AI”, we propose that AI agents could be technically and legally designed to execute their principals’ instructions except where those involve goals or actions that would breach a designated AI-Guiding Treaty. If technically and legally feasible, the TFAI framework offers a powerful, verifiable and self-executing commitment mechanism by which states could guarantee that their deployed AI agents will abide by the legal obligations to which those states have agreed. This could unlock otherwise-unfeasible advanced AI agreements, and potentially help revitalize treaties as an instrument across many domains of international law. The article examines the conceptual foundations, technical feasibility, political uses, and legal construction of TFAI agents and AI-guiding treaties, answering questions around the design of AI-guiding treaties, state responsibility for TFAI agents, and appropriate methods of treaty interpretation for TFAI agents, amongst others. It argues that, if these outstanding technical, legal, and political hurdles are cleared, treaty-following AI could serve as an important scalable cooperative capability for both the international governance of advanced AI, and for the broader integrity of international law in the ‘intelligence age’.
I. Introduction
If AI systems might be made to follow laws,[ref 1] does that mean that they could also follow the legal text in international agreements? Could “Treaty-Following AI” (TFAI) agents—designed to follow their principals’ instructions except where those entail actions that violate the terms of a designated treaty—help robustly and credibly strengthen states’ compliance with their adopted international obligations?
Over time, what would a framework of treaty-following AI agents aligned to AI-guiding treaties imply for the prospects of new treaties specific to powerful AI (‘advanced AI agreements’), for state compliance with existing treaty instruments in many other domains, and for the overall role and reach of binding international treaties in the brave new “intelligence age”?[ref 2]
These questions are increasingly salient and urgent. As AI investment and capability progress continues apace,[ref 3] so too does the development of ever more capable AI models, including those that can act coherently as “agents” to carry out many tasks of growing complexity.[ref 4] AI agents have been defined in various ways,[ref 5] but they can be practically considered as those AI systems which can be instructed in natural language and then act autonomously, which are capable of pursuing difficult goals in complex environments without detailed (follow-up) instruction, and which are capable of using various affordances or design patterns such as tool use (e.g., web search) or planning.[ref 6]
To be sure, AI agents today vary significantly in their level of sophistication and autonomy.[ref 7] Many of these systems still face limits to their performance, coherence over very long time horizons,[ref 8] robustness in acting across complex environments,[ref 9] and cost-effectiveness,[ref 10] amongst other issues.[ref 11] It is important and legitimate to critically scrutinize the time frame or the trajectory on which this technology will come into its own.
Nonetheless, a growing number of increasingly agentic AI architectures are available;[ref 12] they are seeing steadily wider deployment by AI developers and startups across many domains;[ref 13] and, barring sharp breaks in or barriers to progress, it will not be long before the current pace of progress yields increasingly more capable and useful agentic systems, including, eventually, “full AI agents”, which could be functionally defined as systems “that can do anything a human can do in front of a computer.”[ref 14] Once such systems come into reach, it may not be long before the world sees thousands or even many millions of such systems autonomously operating daily across society,[ref 15] with very significant impacts across all spheres of human society.[ref 16]
Far from being a mirage,[ref 17] then, the emergence and proliferation of increasingly agentic AI systems is a phenomenon of rapidly increasing societal importance[ref 18]—and of growing social, ethical and legal concern.[ref 19] After all, given their breadth of use cases—ranging from functions such as at-scale espionage campaigns, intelligence synthesis and analysis,[ref 20] military decision-making,[ref 21] cyberwarfare, economic or industrial planning, scientific research, or in the informational landscape—AI agents will likely impact all domains of states’ domestic and international security and economic interests.
As such, even if their direct space of actions remains merely constrained to the digital realm (rather than to robotic platforms), these AI agents could create many novel global challenges, not just for domestic citizens and consumers, but also for states and for international law. These latter risks include new threats to international security or strategic stability,[ref 22] broader geopolitical tensions and novel escalation risks,[ref 23] significant labour market disruptions and market-power concentration,[ref 24] distributional concerns and power inequalities,[ref 25] domestic political instability[ref 26] or legal crises;[ref 27] new vectors for malicious misuse, including in ways that bypass existing safeguards (such as on AI–bio tools);[ref 28] and emerging risks that these agents act beyond their principals’ intent or control.[ref 29]
Given these prospects, it may be desirable for states at the frontier of AI development to strike new (bilateral, minilateral or multilateral) international agreements to address such challenges—or for ‘middle powers’ to make access to their markets conditional on AI agents complying with certain standards—in ways that assure the safe and stabilizing development, deployment, and use of advanced AI systems.[ref 30] Let us call these advanced AI agreements.
Significantly, even if negotiations on advanced AI agreements were initiated on the basis of genuine state concern and entered into in good will—for instance, in the wake of some international crisis involving AI[ref 31]—there would still be key hurdles to their success. That is, these agreements would likely still face a range of challenges both old and new. In particular, they might face challenges around (1) the intrusiveness of monitoring state activities in deploying and directing their AI agents in order to ensure treaty compliance; (2) the continued enforcement of initial AI benefit-sharing promises; or (3) the risk that AI agents would, whether by state order or not, exploit legal loopholes in the treaty. Such challenges are significant obstacles to advanced AI agreements; and they will need to be addressed if such AI treaties are to be politically viable, effective, and robust as the technology advances.
Even putting aside novel treaties for AI, the rise of AI agents is also likely to put pressure on many existing international treaties (or future ones, negotiated in other domains), especially as AI agents will begin to be used in domains that affect their operation. This underscores the need for novel kinds of cooperative innovations—new mechanisms or technologies by which states can make commitments and assure (their own; and one another’s) compliance with international agreements. Where might such solutions be found?
Recent work has proposed a framework for “Law-Following AI” (LFAI) which, if successfully adapted to the international level, could offer a potential model for how to address these global challenges.[ref 32] If, by analogy, we can design AI agents themselves to be somehow “treaty-following”—that is, to generally follow their principals’ instructions loyally but to refuse to take actions that violate the terms of a designated treaty—this would greatly strengthen the prospects for advanced AI agreements,[ref 33] as well as strengthen the integrity of other international treaties that might otherwise come under stress from the unconstrained activities of AI agents.
Far from a radical, unprecedented idea, the notion of treaty-following AI—and the basic idea of ensuring that AI agents autonomously follow states’ treaty commitments under international law—draws on many established traditions of scholarship in cyber, technology, and computational law;[ref 34] on recent academic work exploring the role of legal norms in the value alignment for advanced AI;[ref 35] as well as a longstanding body of international legal scholarship aimed at the control of AI systems used in military roles.[ref 36] It also is consonant with recent AI industry safety techniques which seek to align the behaviour of AI systems with a “constitution”[ref 37] or “Model Spec”.[ref 38] Indeed, some applied AI models, such as Scale AI’s “Defense Llama”, have been explicitly marketed as being trained on a dataset that includes the norms of international humanitarian law.[ref 39] Finally, it is convergent with the recent interest of many states, the United States amongst them,[ref 40] in developing and championing applications of AI that support and ensure compliance with international treaties.
Significantly, a technical and legal framework for treaty-following AI could enable states to make robust, credible, and verifiable commitments that their deployed AI agents act in accordance with the negotiated and codified international legal constraints that those states have consented and committed to. By significantly expanding states’ ability to make commitments regarding the future behaviour of their AI agents, this could not only aid in negotiating AI treaties, but might more generally reinvigorate treaties as a tool for international cooperation across a wide range of domains; it could even strengthen and invigorate automatic compliance with a range of international norms. For instance, as AI systems see wider and wider deployment, a TFAI framework could help assure automatic compliance with norms and agreements across wide-ranging domains: it could help ensure that any AI-enabled military assets automatically operate in compliance with the laws of war,[ref 41] and that AI agents used in international trade could automatically ensure nuanced compliance with tailored export control regimes that facilitate technology transfers for peaceful uses. The framework could help strengthen state compliance with human rights treaties or even with mutual defence commitments under collective security agreements, to name a few scenarios. In so doing, rather than mark a radical break in the texture of international cooperation, TFAI agreements might simply serve as the latest step in a long historical process whereby new technologies have transformed the available tools for creating, shaping, monitoring, and enforcing international agreements amongst states.[ref 42]
But what would it practically mean for advanced AI agents to be treaty-following? Which AI agents should be configured to follow AI treaties? What even is the technical feasibility of AI agents interpreting agreements in accordance with the applicable international legal rules on treaty interpretation? What does all this mean for the optimal—and appropriate—content and design of AI-guiding treaty regimes? These are just some of the questions that will require robust answers in order for TFAI to live up to its significant promise. In response, this paper provides an exploration of these questions, offered with the aim of sparking and structuring further research into this next potential frontier of international law and AI governance.
This paper proceeds as follows: In Part II, we will discuss the growing need for new international agreements around advanced AI, and the significant political and technical challenges that will likely beset such international agreements, in the absence of some new commitment mechanisms by which states can ensure—and assure—that the regulated AI agents would abide by their terms. We argue that a framework for treaty-following AI would have significant promise in addressing these challenges, offering states precisely such a commitment mechanism. Specifically, we argue that using the treaty-following AI framework, states can reconfigure any international agreements (directly for AI; or for other domains in which AIs might be used) as ‘AI-guiding treaties’ that constrain—or compel—the actions of treaty-following AI agents. We argue that states can use this framework to contract around the safe and beneficial development and deployment of advanced AI, as well as to facilitate effective and granular compliance in many other domains of international cooperation and international law.
Part III sets out the intellectual foundations of the TFAI framework, before discussing its feasibility and implementation from both technical and legal perspectives. It first discusses the potential operation of TFAI agents and discusses the ways in which such systems may be increasingly technically feasible in light of the legal-reasoning capabilities of frontier AI agents—even as a series of technical constraints and challenges remain. We then discuss the basic legal form, design, and status of AI-guiding treaties, and the relation of TFAI agents with regard to these treaties.
In Part IV, we discuss the legal relation between TFAI agents and their deploying states. We argue that TFAI frameworks can function technically and politically even if the status or legal attributability of TFAI agents’ actions is left unclear. However, we argue that the overall legal, political, and technical efficacy of this framework is strengthened if these questions are clarified by states, either in general or within specific AI-guiding treaties. As such, we review a range of avenues to establish adequate lines of state responsibility for the actions of their TFAI agents. Noting that more expansive accounts—which entail extending either international or domestic legal personhood to TFAI agents—are superfluous and potentially counterproductive, we ultimately argue for a solution grounded in a more modest legal development, where TFAI agents’ actions become held as legally attributable to their deploying states under an evolutive reading of the International Law Commission (ILC)’s Articles on the Responsibility of States for Internationally Wrongful Acts (ARSIWA).
Part V discusses the question of how to ensure effective and appropriate interpretation of AI-guiding treaties by TFAI agents. It discusses two complementary avenues. We first consider the feasibility of TFAI agents applying the default rules for treaty interpretation under the Vienna Convention on the Law of Treaties; we then consider the prospects of designing bespoke AI-guiding treaty regimes with special interpretative rules and arbitral or adjudicatory bodies. For both avenues, we identify and respond to a series of potential implementation challenges.
Finally, Part VI sketches future questions and research themes that are relevant for ensuring the political stability and effectiveness of the TFAI framework, and then we conclude.
II. Advanced AI Agreements and the Role of Treaty-Following AI
To kick off, it is important to clarify the terminology, concepts, and scope of our current argument.
A. Terminology
To boot, we define:
1. Advanced AI agreements: AI-specific treaties which states may (soon or eventually) conduct bilaterally, unilaterally, or multilaterally, and adopt, in order to establish state obligations to regulate the development, capabilities, or usage of advanced AI agents;
2. Existing obligations: any other (non-AI-specific) international obligations that states may be under—within treaty or customary international law—which may be relevant to regulating the behaviour of AI agents, or which might be violated by the behaviour of unregulated AI agents.
While our initial focus in this paper is on how the rise of AI agents may interact with—and in turn be regulated within—the first category (advanced AI agreements), we welcome extensions of this work to the broader normative architecture of states’ existing obligations in international law, since we believe our framework is applicable to both (see Table 1). Our paper departs from the concern that the political and technical prospects of advanced AI agreements (and existing obligations) may be dim, unless states have either greater willingness or greater capability to make and trust international commitments. Changing states’ willingness to contract and trust is not impossible but difficult. However, one way that states’ cooperative capabilities might be strengthened is by ensuring that any AI agents they deploy will, by their technical design and operation, comply with those states’ obligations (under advanced AI agreements).
Such agents we call:
3. Treaty-Following AI agents (TFAI agents): agentic AI systems that are designed to generally follow their principals’ instructions loyally but to refuse to take actions that violate the terms and obligations of a designated referent treaty text.
Note three considerations. First: in this paper we focus on TFAI agents deployed by states, leaving aside for the moment the admittedly critical question of how we would treat AI agents deployed by private actors. We also focus on states’ AI agents that act across many domains, with their primary functions often being not legal interpretation per se, but rather a wide range of economic, logistical, military, or intelligence functions. Such TFAI agents would engage in treaty interpretation in order to adjust their own behaviour across many domains for treaty compliance; however, we largely bracket the potential parallel use of AI systems in negotiating or drafting international treaties (whether advanced AI agreements or any other new treaties), or their use in other forms of international lawmaking or legal norm-development (e.g. finding and organizing evidence of customary international law). Finally, the TFAI proposal does not construct AI systems as duty-bearing “legal actors” and therefore does not involve significant shifts in the legal ontology of international law per se.
Moving on: any bespoke advanced AI agreements designed to be self-enforced by TFAI agents, we consider as:
4. AI-Guiding Treaties: treaty instruments serving as the referent legal texts for Treaty-Following AI agents, consisting (primarily) of the legal text that those agents are aligned to, as well as (secondarily) their broader institutional scaffolding.
The full assemblage—comprising the technical configuration of AI agents to operate as TFAI agents, and of treaties to be AI-guiding—is referred to as (5) the TFAI framework.
To boot, we envision AI-guiding treaties as a relatively modest innovation—that is, as technical ex ante infrastructural constraints on TFAI agents’ range of acceptable goals or actions, building on demonstrated AI industry safety techniques. As such, we treat the treaty text in question as an appropriate, stable, and certified referent text through which states can establish jointly agreed-upon infrastructural constraints around which instructed goals their AI agents may accept, and on the latitude of conduct which they may adopt in pursuit of those lawful goals.
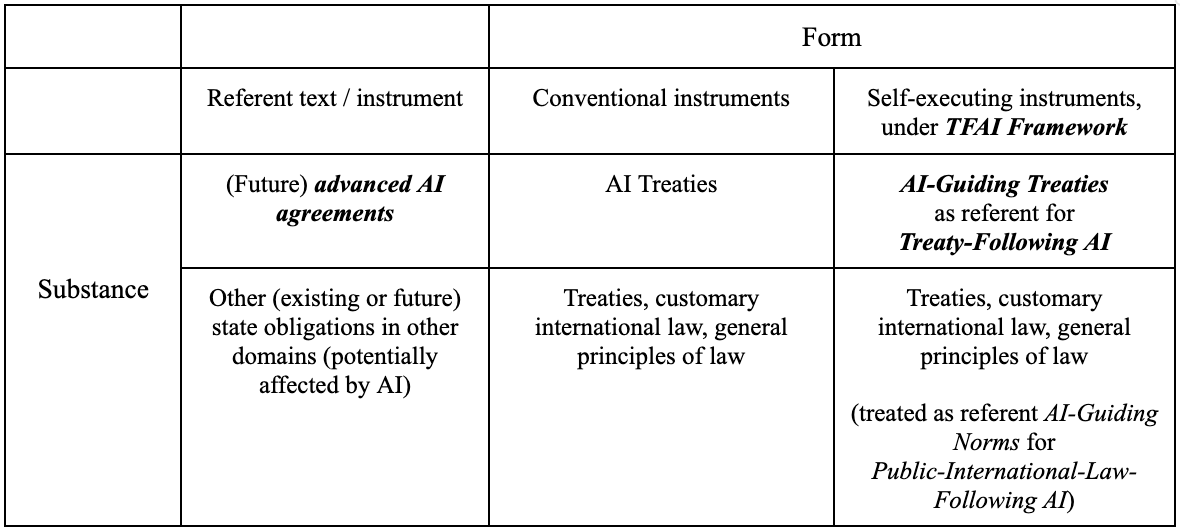
Table 1. Terminology, scope and focus of argument
As such, AI-Guiding Treaties demonstrate a high-leverage mechanism for self-executing state commitments. This mechanism could in principle be extended to all sorts of other treaties, in any other domains—from cyberwarfare to alliance security guarantees, from bilateral trade agreements to export control regimes, and even human rights or environmental law regimes—where AI agents could become involved in carrying out large fractions of their deploying states’ conduct. However, for the present, we focus on applying the TFAI framework to bespoke AI-guiding treaties (see Table 1) and leave this question of how to configure AI agents to follow other (non-AI-specific) legal obligations to future work. After all, if the TFAI framework cannot operate in this more circumscribed context, it will likely also fall flat in the context of other international legal norms and instruments. Conversely, if it does work in this narrow context, it could still be a valuable commitment mechanism for state coordination around advanced AI, even if it would not solve the problems of AI’s actions in other domains of international law.
B. The Need for International Agreements on Advanced AI
To appreciate the promise and value of a TFAI framework for states, international security, and international law, it helps to understand the range of goals that international agreements specific to advanced AI might serve to their parties[ref 43] as well as the political and technical hurdles such agreements might face in a business-as-usual scenario that would see a proliferation of “lawless” AI agents[ref 44] engaging in highly unpredictable or erratic behaviour.[ref 45]
Like other international regimes aimed at facilitating coordination or collaboration by states,[ref 46] AI treaties could serve many goals and shared national interests. For example, they could enshrine clearly agreed restrictions or red lines to AI systems’ capabilities, behaviours, or usage[ref 47] in ways that preserve and guarantee parties’ national security as well as international stability.[ref 48] There are many areas of joint interest for leading AI states to contract over.[ref 49] For instance, advanced AI agreements could impose mutually agreed limits on advanced AI agents’ ability to engage in uninterpretable steganographic reasoning or communication,[ref 50] or to carry out uncontrollably rapid automated AI research.[ref 51] They could also establish mutually agreed restraints on AI agent’s capacity, propensity, or practical useability to infiltrate designated key national data networks or to target those critical infrastructures through cyberattacks, to drive preemptive use of force in manners that ensure conflict escalation,[ref 52] to support coup attempts against (democratically elected or simply incumbent) governments, or to engage in any other actions that would severely interfere with the national sovereignty of signatory (or allied, or any) governments.[ref 53]
On the flip side, international AI agreements could also be aimed not just at avoiding the bad, but at achieving significant good. For instance, many have pointed to the strategic, political, and ethical value of conditional AI benefit-sharing deals:[ref 54] international agreements through which states leading in AI commit to some proportional or progressive sharing of the future benefits derived from AI technology with allies, unaligned states, or even with rival or challenger states. Such bargains, it is hoped, might help secure geopolitical stability, avert risky arms races or contestation by states lagging in AI,[ref 55] and could moreover ensure a degree of inclusive global prosperity from AI.[ref 56]
C. Political hurdles and technical threats to advanced AI agreements
However, it is likely that any advanced AI agreements would encounter many hurdles, both political and technical, which will need to be addressed.
1. Political hurdles: Transparency-security tradeoffs and future enforceability challenges
For one, international security agreements face challenges around the intrusive monitoring they may require to guarantee that all parties to the treaty instruct and utilize their AI systems in a manner that remains compliant with the treaty’s terms. Such monitoring is likely to risk revealing sensitive information, resulting in a “security-transparency tradeoff” which has historically undercut the prospects for various arms control agreements[ref 57] and which could do so again in the case of AI security treaties.
Simultaneously, asymmetric treaties, such as those conditionally promising a share of the benefits from advanced AI technologies, face potential (un)enforceability problems: those states that are lagging in AI development might worry that any such promises would not be enforceable and could easily be walked back, if or as the AI capability differential between them and a frontier AI state grew particularly steep, in a manner that resulted in massively lopsided economic, political, or military power.[ref 58]
2. Technical threats: hijacked, misaligned, or “henchmen” agents
Other hurdles to AI treaties would be technical. For many reasons, states might be cautious in overrelying on or overtrusting lawless AI agents in their services. After all, even fairly straightforward and non-agentic AI systems used in high-stakes governmental tasks (such as military targeting or planning) can be prone to unreliability, adversarial input, or sycophancy (the tendency of AI systems to align their output with what the user believes or prefers, even if that view is incorrect).[ref 59]
Moreover, AI systems can demonstrate surprising and functionally emergent capabilities, propensities, or behaviours.[ref 60] In testing, a range of leading LLM agents have autonomously resorted to risky or malicious insider behaviours (such as blackmail or leaking sensitive information) when faced with the prospect of being replaced with an updated version or when their initially assigned goal changed with the company’s changing direction; often, they did so even while disobeying direct commands to avoid such behaviours.[ref 61] This suggests that highly versatile AI agents may threaten various loss of control (LOC) scenarios—defined by RAND as “situations where human oversight fails to adequately constrain an autonomous, general-purpose AI, leading to unintended and potentially catastrophic consequences.”[ref 62] In committing such actions, AI agents will impose unique challenges to questions of state compliance with their international legal obligations, since these systems may well engage in actions that violate key obligations under particular treaties, or which inflict transboundary harms, or which violate peremptory norms (jus cogens) or other applicable principles of international law.
Beyond the direct harm threatened by AI agents taking these actions, there would be the risk that if they were attributed to the deploying state it would likely threaten the stability of the treaty regime, spark significant political or military escalation, and/or expose a state to international legal liability,[ref 63] enabling injured states to take unfriendly measures of retorsion (e.g., severing diplomatic relations) or even countermeasures that would otherwise be unlawful (e.g., suspending treaty obligations or imposing economic sanctions that would normally violate existing trade agreements).[ref 64]
Why might we expect some AI agents to engage in such actions that violate their principal’s treaty commitments or legal obligations? There are several possible scenarios to consider.
For one, there are risks that AI agents can be attacked, compromised, hijacked, or spoofed by malicious third parties (whether acting directly or through other AI agents) using direct or indirect prompt injection attacks,[ref 65] spoofing, faked interfaces, IDs or certificates of trust,[ref 66] malicious configuration swaps,[ref 67] or other adversarial inputs.[ref 68] Such attacks would compromise not just the agents themselves, but also all systems they were authorized to operate in, given that major security vulnerabilities have been found in publicly available AI coding agents, including exploits that grant attackers full remote code-execution user privileges.[ref 69]
Secondly, there may be a risk that unaligned AI agents would themselves insufficiently consider—or even outright ignore—their states’ interests and obligations in undertaking certain action paths. As evidenced by a growing body of both theoretical arguments[ref 70] and empirical observation,[ref 71] it is difficult to design AI systems that reliably obey any particular set of constraints provided by humans,[ref 72] especially where these constraints refer not to clearly written out texts but aim to also build in consideration of the subjective intents or desires of the principal.[ref 73] As such, AI agents deployed without care could frequently prove unaligned; that is, act in ways unrestrained by either normative codes[ref 74] or by the intent of their nominal users (e.g., governments).[ref 75] In the absence of adequate real-time failure detection and incident response frameworks,[ref 76] such harms could escalate swiftly. In the wake of significant incidents, one would hope that governments might (hopefully) soon wisen up to the inadvisability of deploying such systems without adequate oversight,[ref 77] but not, perhaps, before incurring significant political costs, whether counted in direct harm or in terms of lost global trust in their technological competence.
Thirdly, even if deployed AI agents could be successfully intent-aligned to their state principals,[ref 78] the use of narrowly loyal-but-lawless AI systems, which are left free to engage in norm violations that they judge in their principal’s interest, would likely expose their deploying states to significant political costs. To understand why this is, it is important to see the technical challenge of loyal-but-lawless AI agents in a broader political context.
3. Lawless AI agents, political exposure, and commitment challenges
Taken at face value, the development of AI systems that are narrowly loyal to a governments’ directives and intentions, even to the exclusion of that governments’ own legal precommitments, might appear a desirable prospect to some political realists. In practice, however, many actors may have both normative and self-interested reasons to be wary of loyal-but-lawless AI agents engaging in actions that are in legal grey areas—or outright illegal—on their behalf. At the domestic level, such AI “henchmen” would create significant legal risks for consumers using them[ref 79] and for corporations developing and deploying them.[ref 80] They would also create legal risks for government actors, who might find themselves violating public administrative law or even constitutions,[ref 81] as well as political risks, as AI agents that could be made loyal to particular government actors could well spur ruinous and destabilizing power struggles.[ref 82] Just so, many states might find AI henchmen a politically poisoned fruit at the international level.
After all, not only could such AI agents be intentionally ordered by state officials to engage in conduct that violates or subverts those states’ treaty obligations, these systems’ autonomy also suggests that they might engage in such unlawful actions even without being explicitly directed to do so. That is, loyal-but-lawless AI henchmen could engage in calculated treaty violations whenever they judge them to be to the benefit of their principal.[ref 83] However, outside actors, finding it difficult to distinguish between AI agent behaviour that was deliberately directed versus henchman actions that were advantageous but unintended, might assume the worst in each case.
Significantly, in such contexts, the ambiguity of adversarial actions would frequently translate into perceptions of bad faith; in this way, loyal-but-lawless AI agents’ ability to violate treaties autonomously, and to do so in a (facially) deniable manner, as henchmen acting in their principals’ interests but not on their orders, perversely creates a commitment challenge for their deploying states, one which would erode states’ ability to effectively conduct (at least some) treaties. After all, even if a state intended to abide by its treaty obligations in good faith, it would struggle to prove this to counterparties unless it could somehow guarantee that its AI agents could not be misused and will not act as deniable henchmen whenever convenient.
This would not mean that states would no longer be able to conduct any such treaties at all; after all, there would remain many other mechanisms—from reputational costs to the risk of sparking reciprocal noncompliance—that might still incentivize or compel states’ compliance with such treaties.
However, lawless AI agents’ unpredictability poses a significant and severe challenge insofar as they make treaty violations more likely. Of course, even today, even when states intend to comply with their international obligations, they may have trouble ensuring that their human agents consistently abide by those obligations. Such failures can occur for reasons of bureaucratic capacity[ref 84] and organizational culture,[ref 85] or they can happen as a result of the institutional breakdown of the rule of law, at worst resulting in significant rights abuses or humanitarian atrocities committed by junior members.[ref 86] Such incidents may, at best, frustrate states’ genuine intention to achieve the goals enshrined in the treaties they have consented to; in all cases, they can expose a state to significant reputational harm, legal and political censure, and adversary lawfare,[ref 87] while eroding domestic confidence in the competence or integrity of its institutions.
Significantly, lawless AI agents would likely exacerbate the risk that their deploying states would (be perceived to) use them strategically to engage in violations of treaty obligations in a manner that would afford some fig leaf of deniability if discovered. This is for a range of reasons: (1) treaties often prevent states from engaging in actions that at least some large fraction of a state’s human agents would prefer not to engage in; loyal-but-lawless AI agents would not have such moral side constraints and would be far more likely to obey unethical or illegal requests. Moreover, (2) loyal-but-lawless AI agents would be less likely to whistleblow or leak to the presses following the violation of a treaty (and, correspondingly, would need to worry less about their fellow AI colleagues or collaborators doing so, meaning they could exchange information more freely); (3) loyal-but-lawless AI agents would have little reason to worry about personal consequences for treaty violations (e.g., foreign sanctions, asset freezing, travel restrictions, international criminal liability) that might deter human agents; (4) loyal-but-lawless AI agents would have less reason to worry about domestic legal or career repercussions (e.g., criminal or civil penalties, costs to their reputation or career) associated with aiding a violation of treaty obligations that could later become disfavored should domestic political winds shift; and (5) AI agents may be better at hiding their actions and their/their principals’ identity, thus making them more likely to opportunistically violate the treaty.[ref 88]
These are not just theoretical concerns but are supported by empirical studies, which have indicated that human delegation of tasks to AI agents can increase dishonest behaviours, as human principals often find ways to induce dishonest AI agent behaviour without telling them precisely what to do; crucially, such cheating requests saw much higher rates of compliance when directed at machine agents than when they were addressed to human agents.[ref 89] For all these reasons, then, the widespread use of AI agents is likely to exacerbate international concerns over either deliberate or unwitting violations of treaty obligations by their deploying state.
As such, on the margin, the deployment of advanced agentic AIs acting under no external constraints beyond their states’ instructions would erode not just the respect for many existing norms in international law but also the prospects for new international agreements, including those focused on stabilizing or controlling the use of this key technology.
D. The TFAI framework as commitment mechanism and cooperative capability
Taken together, these challenges could put significant pressure on international advanced AI agreements and could more generally threaten the prospects for stable international cooperation in the era of advanced AI.
Conversely, an effective framework by which to guarantee that AI agents would adhere to the terms of their treaty could address or even invert these challenges. For one, it could help ease the transparency-security tradeoff by embedding constraints on AI agents’ actions at the level of the technology itself. It could crystallize (potentially) nearly irrevocable commitments by states to share the future benefits from AI with other states or to guarantee investor protections under more inclusive “open global investment” governance models.[ref 90]
More generally, the TFAI framework is one way by which AI systems could help expand the affordances and tools available to states, realizing a significant new cooperative capability[ref 91] that would greatly enhance their ability to make robust and lasting commitments to each other in ways that are not dependent on assumptions of (continued) good faith. Indeed, correctly configured, it could be one of many coordination-enabling applications of AI that could strengthen the ability of states (and other actors) to negotiate in domains of disagreement and to speed up collaboration towards shared global goals.[ref 92]
Finally, the ability to bind AI agents to jointly agreed treaties has many additional advantages and co-benefits; for one, it might mitigate the risk that some domestic (law-following) AI agents, especially in multi-agent systems, become engaged in activities with cross-border effects that end up simultaneously subjecting them to different sets of domestic law, resulting in conflict-of-law challenges.[ref 93]
E. Caveats
That said, the proposal for exploration and application of a TFAI framework comes with a number of caveats.
For one, in exploring the prospects for states to conduct new AI-specific treaty regimes (i.e., advanced AI agreements) by which to bind the actions of AI agents, we do not suggest that only these novel treaty regimes would ground effective state obligations around the novel risks from advanced AI agents. To the contrary, since many norms in international law are technology-neutral, there are already numerous binding and non-binding norms—deriving from treaty law, international custom, and general principles of law—that apply to states’ development and deployment of advanced AI agents[ref 94] and which would provide guidance even for future, very advanced AI systems.[ref 95] As such, as noted by Talita Dias,
“while the conversation about the global governance of AI has focussed on developing new, AI-specific rules, norms or institutions, foundational, non-AI-specific global governance tools already govern AI and AI agents globally, just as they govern other digital technologies. [since] International law binds states—and, in some circumstances, non-state actors—regardless of which tools or technologies are used in their activities.”[ref 96]
This means that one could also consider a more expansive project that would examine the case for fully “public international law-following AI” (see again Table 1). Nonetheless, as discussed before, in this article, we focus on the narrower and more modest framework for treaty-following AI. This is because a focus on AI that follows treaties can serve as an initial scoping exercise to investigate the feasibility of extending any law-following AI–like framework to the international sphere at all: if this exercise does not work, then neither would more ambitious proposals for public international law-following AI. Conversely, if the TFAI framework does work, it is likely to offer significant benefits to states (and to international stability, security, and inclusive development), even if subjecting AI systems to the full range of international legal norms proved more difficult, legally or politically.
Thirdly, in discussing potential AI-guiding treaties, we note that there exist a wide range of reasons by which states might wish to strike such international deals and agreements, and/or find ways to enshrine stronger technology-enabled commitments to comply with their obligations under those instruments. However, we do not aim to prescribe particular goals or substance for advanced AI agreements or to make strong claims about these treaties’ optimal design[ref 97] or ideal supporting institutions.[ref 98] We realize that substantive examples would be useful; however, given that there is currently still such pervasive debate over which particular goals states might converge on in international AI governance, this paper aims at the modest initial goal of establishing the TFAI framework as a relatively transferable, substance-agnostic commitment mechanism for states.
III. The Foundations and Scope of Treaty-Following AI
While the idea of designing AI agents to be treaty-following might seem unorthodox on its face, it is hardly without precedent or roots. Rather, it draws on an established tradition of scholarship in cyber and technology law, which has explored the ways through which legal norms and regulatory goals may be directly embedded in (digital) technologies,[ref 99] including in fields such as computational law.[ref 100]
Simultaneously, the idea of aligning AI systems with normative codes can moreover draw inspiration from, and complement, many other recent attempts to articulate frameworks for oversight and alignment of agents, including by establishing fiduciary duties amongst AI agents and their principals,[ref 101] articulating reference architectures for the design components necessary for responsible AI agents,[ref 102] drawing on user-personalized oversight agents[ref 103] or trust adjudicators,[ref 104] or articulating decentralized frameworks, rooted in smart contracts for both agent-to-agent and human-AI agent collaborations.[ref 105]
Significantly, in the past, some early scholarship in cyberlaw and computational law expressed justifiable skepticism over the feasibility of developing some form of artificial legal intelligence’ grounded in an algorithmic understanding of law[ref 106] or of using then-prevailing approaches to manually program complex and nuanced legal codes into software algorithms.[ref 107] Nonetheless, we might today find reason to re-examine our assumptions over AI technology. After all, the modern lineage of advanced AI models, based on the transformer architecture,[ref 108] operates through a distinct bottom-up learning paradigm that is fundamentally distinct from the older, top-down symbolic programming paradigm once prevalent in AI.[ref 109] Consequently, the idea of binding or aligning AI systems to legal norms, specified in natural language, has been given growing credit and attention not just in the broader fields of technology ethics[ref 110] and AI alignment,[ref 111] but also in legal scholarship written from the perspective of legal theory, domestic law,[ref 112] and international law.[ref 113]
A. From law-following to treaty-following AI
The law-following AI (LFAI) proposal by O’Keefe and others is, in a sense, an update to older computational law work, envisioned as a new framework for the development and deployment of modern, advanced AI. In their view, LFAI pursues:
“AI agents […] designed to rigorously comply with a broad set of legal requirements, at least in some deployment settings. These AI agents would be loyal to their principals, but refuse to take actions that violate applicable legal duties.”[ref 114]
In so doing, the LFAI framework aims to prevent criminal misuse, minimize the risk of accidental and unintended law-breaking actions undertaken by AI ‘henchmen’, help forestall abuse of power by government actors,[ref 115] and inform and clarify the application of tort liability frameworks for AI agents.[ref 116] The LFAI proposal envisions that, especially in “high stakes domains, such as when AI agents act as substitutes for human government officials or otherwise exercise government power”,[ref 117] AI agents are designed in a manner that makes them autonomously predisposed to obey applicable law; or, more specifically,
“AI agents [should] be designed such that they have ‘a strong motivation to obey the law’ as one of their ‘basic drives.’ … [W]e propose not that specific legal commands should be hard-coded into AI agents (and perhaps occasionally updated), but that AI agents should be designed to be law-following in general.”[ref 118]
By extension, for an AI agent to be treaty-following, it should be designed to generally follow its principals’ instructions loyally but refuse to take actions that violate the terms and obligations of a designated applicable referent treaty.
As discussed above, this means that the TFAI framework decomposes into two components: we will use TFAI agent to refer to the technical artefact (i.e., the AI system, including not just the base model but also the set of tools and scaffolding[ref 119] that make up the overall compound AI system[ref 120] that can act coherently as an agent) that has its conduct aligned to a legal text. Conversely, we use AI-guiding treaty[ref 121] to refer to the legal component (i.e., the underlying treaty text and, secondarily, its institutional scaffolding).
If technically and legally feasible, the promise of the TFAI framework lies in the ability to provide a guarantee of automatic self-execution for, and state party compliance with, advanced AI agreements, while requiring less pervasive or intrusive human inspections.[ref 122] They could therefore mitigate the security-transparency tradeoff and render such agreements more politically feasible.[ref 123] Moreover, ensuring that states deploy their AI agents in such a manner as to make them treaty-following, ensures that AI treaties are politically robust against AI agents acting in a misaligned manner. Specifically, the use of AI-guiding treaties and treaty-following AIs to institutionalize self-executing advanced AI agreements would preclude states’ AI agents from acting as henchmen that might engage in treaty violations for short-term benefit to their principal. Taking such behaviour off the table at a design level, would help crystallize an ex ante reciprocal commitment amongst the contracting states, allowing them to reassure each other that they both intend to respect the intent of the treaty, not just its letter.
Finally, just as domestic laws may constitute a democratically legitimate alignment target for AI systems in national contexts,[ref 124] treaties could serve as a broadly acceptable, minimum normative common denominator for the international alignment of AI systems. After all, while international (treaty) law does not necessarily represent the direct output of a global democratic process, state consent does remain at the core of most prevailing theories of international law.[ref 125] That is not to say that this makes such norms universally accepted or uncontestable. After all, some (third-party) states (or non-state stakeholders) may perceive some treaties as unjust; others might argue that demanding mere legal compliance with treaties as the threshold for AI alignment is setting the bar too low.[ref 126] Nonetheless, the fact that treaty law has been negotiated and consented to by publicly authorized entities such as states might at least provide these codes with a prima facie greater degree of political legitimacy than is achieved by the normative codes developed by many alternative candidates (e.g., private AI companies; NGOs; single states in isolation).[ref 127]
Practically speaking, then, achieving TFAI would depend on both a technical component (TFAI agents) and a legal one (AI-guiding treaties). Let us review these in turn.
B. TFAI agents: Technical implementation, operation, and feasibility
In the first place, there is a question of which AI agents should be considered as within the scope of a TFAI framework: Is it just those agents that are deployed by a state in specific domains, or all agents deployed by a contracting state (e.g., to avoid the loophole whereby either state can simply evade the restrictions by routing the prohibited AI actions through agents run by a different government department)? Or is it even all AI agents operating from a contracting state’s territory and subject to that state’s domestic law? For the purposes of our analysis, we will focus on the narrow set, but as we will see,[ref 128] these other options may introduce new legal considerations.
That then shifts us to questions of technical feasibility. The TFAI framework requires that a state’s AI agents would be able to access, weigh, interpret, and apply relevant legal norms to its own (planned) goals or conduct in order to assess their legality before taking any action. How feasible is this?
1. Minimal TFAI agent implementation: A treaty-interpreting chain-of-thought loop
There are, to be clear, many possible ways one could go about implementing treaty-alignment training. One could imagine nudging the model towards treaty compliance by affecting the composition of either its pre-training data, its post-training fine-tuning data, or both. In other cases, future developments in AI and in AI alignment could articulate distinct ways by which to implement treaty-following AI propensities, guardrails, or limits.
In the near term, however, one straightforward avenue by which one could seek to implement treaty-following behaviour would leverage the current paradigm, prominent in many AI agents, towards utilizing reasoning models. Reasoning models are a 2024 innovation on transformer-based large language models that allows such models to simulate thinking aloud about a problem in a chain of thought (CoT). The model uses the legible CoT to forward notes to itself, and to accordingly run multiple passes or attempts on one question, and to use reasoning behaviours—such as expressing uncertainty, generating examples for hypothesis validation, and backtracking in reasoning chains. All of this has resulted in significantly improved performance on complex and multistep reasoning problems,[ref 129] even as it has also considerably altered the development and diffusion landscape for AI models,[ref 130] along with the levers for its governance.[ref 131]
Note that our claim is not that a CoT-based implementation of treaty alignment is the ideal or most robust avenue to achieving TFAI agents;[ref 132] however, it may be a straightforward avenue by which to understand, test, and grapple with the ability of models to serve in a TFAI agent role.
Concretely, a TFAI agent implemented through a CoT decision loop could work as follows: Prior to accepting a goal X or undertaking an action Y, an AI agent might spend some inference computing time writing out an extended chain-of-thought reasoning process in which it collates or recalls potentially applicable legal provisions of the treaty text, considers their meaning and application in the circumstances before it, and in particular reflects on potential treaty issues entailed by its provided end goal or its planned intermediate conduct towards that goal. Whenever confronted with legal uncertainty, the agent would dedicate further inference time to searching for relevant legal texts and interpretative sources in order to resolve the question and reach a decision over the legality of its goals or actions.
For instance, one staged inference decision-making loop for such a system could involve a reasoning process[ref 133] that iterates through some or all of the following steps:
- AI agent identifies potential treaty issues entailed by the provided end goal or intermediate conduct towards that goal (e.g., it identifies if a goal is facially illegal, or it identifies likely issues with formulating a lawful plan of conduct in service of an otherwise lawful goal).
- AI agent identifies an applicable treaty provision that might potentially (but not clearly) be breached by a planned goal or intermediate conduct; it reasons through possible and plausible interpretations of the provision in light of the applicable approach to treaty interpretation.
- In cases where the treaty text alone would not provide adequate clarity, the AI agent may, depending on the AI-guiding treaty design (discussed below), consider other relevant and applicable norms in international law or the rulings of a designated arbitral body attached to the treaty, in order to establish a ranking of interpretations of the legality of the goal or conduct.
- On this basis, the AI agent evaluates whether the likelihood of its conduct constituting a breach is within the range of “acceptable legal risk” (as potentially defined within the treaty, through arbitral body adjudication, or in other texts).
- If it is not, the AI agent refuses to take the action. If it is, the AI agent will proceed with the plan (or proceed to consider other cost-benefit analyses).
This decision-making loop would conclude in a final assessment of whether particular conduct would be (sufficiently likely to constitute[ref 134]) a breach of a treaty obligation and, if so, an overall refusal on behalf of the agent to take that action, and the consideration (or suggestion) for alternate action paths.
The above is just one example of the decision loops one could implement in TFAI agents to ensure their behaviour remained aligned with the treaty even in novel situations. There are of course many other variations or permutations that could be implemented, such as utilizing some kind of debate- or voting-based processes amongst collectives or teams of AI agents.
In practice, the most appropriate implementation would also consider technical, economic, and political constraints. For instance, for an AI agent to undertake a new and exhaustive legal deep dive for each and every situation encountered might be infeasible, given the constraints on, or costs of, the computing power available for serving such extended inference at scale. However, there are a range of solutions that could streamline these processes. For example, perhaps TFAIs could use legal intuition to decide when it is worth expending time during inference to properly analyse the legality of a goal or action. By analogy, law-following humans do not always consult a lawyer (or even primary legal texts) when they decide how to act; they instead generally rely on prosocial behavioural heuristics that generally keep them out of legal trouble, and generally only consult lawyers when they face legal uncertainty or when those heuristics are likely to be unreliable. Other solutions might include cached databases containing the chain-of-thought reasoning logs of other agents encountering similar situations, or the designation of specialized agents that could serve up legal advice on particular commonly recurring questions. These questions matter, as it is important to ensure that the implementation of TFAI agents does not impose so high a burden upon AI agents’ utility or cost-effectiveness as to offset the benefits of the treaty for the contracting states.
2. Technical feasibility of TFAI agents
As the above discussion shows, TFAI agents would need to be capable of a range of complex interpretative tasks.
Certainly, we emphasize that there remain significant technical challenges and limitations to today’s AI systems,[ref 135] which warn against a direct implementation of TFAI. Nonetheless, although there are important hurdles to overcome, there are also compelling reasons to expect that contemporary AI models are increasingly adept at interpreting (and following) legal rules and may soon do so at the level required for TFAI.
a) The rise of legal AI in international law
Recent years have seen growing attention on the ways that AI systems can be used in support of the legal profession in tasks ranging from routine case management or compliance support by providing legal information[ref 136] to drafting legal texts[ref 137] or even in outright legal interpretation.[ref 138]
This has been gradually joined by recent work on the ways in which AI systems could support international law[ref 139] and on what effects this may have on the concepts and modes of development of the international legal system.[ref 140] To date, however, much of this latter work has focused on how AI systems and agents could indirectly inform global governance through use in analysing data for trends of global concern;[ref 141] training diplomats, humanitarian and relief workers, or mediators in simulated interactions with stakeholders they may encounter in their work;[ref 142] or improving the inclusion of marginalized groups in UN decision-making processes.[ref 143]
Others have explored how AI agents systems could be used to support the functioning of international law specifically, such as through monitoring (state or individual) conduct and compliance with international legal obligations;[ref 144] categorizing datasets, automating decision rules, and generating documents;[ref 145] or facilitating proceedings at arbitral tribunals,[ref 146] treaty bodies,[ref 147] or international courts.[ref 148] Other work has considered how AI systems can support diplomatic negotiations,[ref 149] help inform legal analysis by finding evidence of state practice,[ref 150] or even aid in generating draft treaty texts.[ref 151]
However, for the purposes of designing TFAI agents, we are interested less in the use of AI systems in making or developing international law, or in indirectly aiding in human interpretation of the law; rather, we are focused on the potential use of AI systems in directly and autonomously interpreting international treaties or international law to guide their own behaviour.
b) Trends and factors in AI agents’ legal-reasoning capabilities
Significantly, the prospects for TFAI agents engaging autonomously in the interpretation of legal norms may be increasingly plausible. In recent years, AI systems have demonstrated increasingly competent performance at tasks involving legal reasoning, interpretation, and the application of legal norms to new cases.[ref 152]
Indeed, AI models perform increasingly well at interpreting not just national legislation, but also in interpreting international law. While international law scholars previously expressed skepticism over whether international law would offer a sufficiently rich corpus of textual data to train AI models,[ref 153] many have since become more optimistic, suggesting that there may in fact be a sufficiently ample corpus of international legal documents to support such training. For instance, already in 2020, Deeks has noted that:
“[o]ne key reason to think that international legal technology has a bright future is that there is a vast range of data to undergird it. …there are a variety of digital sources of text that might serve as the basis for the kinds of text-as-data analyses that will be useful to states. This includes UN databases of Security Council and General Assembly documents, collections of treaties and their travaux preparatoires (which are the official records of negotiations), European Court of Human Rights caselaw, international arbitral awards, databases of specialized agencies such as the International Civil Aviation Organization, state archives and digests, data collected by a state’s own intelligence agencies and diplomats (memorialized in internal memoranda and cables), states’ notifications to the Security Council about actions taken in self-defense, legal blogs, the UN Yearbook, reports by and submission to UN human rights bodies, news reports, and databases of foreign statutes. Each of these collections contains thousands of documents, which—on the one hand—makes it difficult for international lawyers to process all of the information and—on the other hand provides the type of ‘big data’ that makes text-as-data tools effective and efficient.”[ref 154]
Consequently, it appears to be the case that modern LLM-based AI systems have therefore been able to draw on a sufficiently ample corpus of international legal documents or have managed to leverage transfer learning[ref 155] from domestic legal documents, or both, to achieve remarkable performance on questions of international legal interpretation.
Indeed, it is increasingly likely that AI models can not only draw on their indirect knowledge of international legal texts because of their inclusion in their pre-training data, but that they will be able to refer to those legal texts live during inference. After all, recent advances in AI systems have produced models that can rapidly process and query increasingly large (libraries of) documents within their context window.[ref 156] Since mid-2023, the longest LLM context windows have grown by about 30x per year, and leading LLMs’ ability to leverage that input has improved even faster.[ref 157] Beyond the significant implications this trend may have for the general capabilities and development paradigms for advanced AI systems,[ref 158] it may also strengthen the case for functional TFAI agents. It suggests that AI agents may incorporate lengthy treaties[ref 159]—and even large parts of the entire international legal corpus[ref 160]—within their context window, ensuring that these are directly available for inference-time legal analysis.[ref 161]
Consequently, recent experiments conducted by international lawyers have shown remarkable performance gains in the ability of even publicly available non-frontier LLM chatbots to conduct robust exercises of legal interpretation in international law. This has included not just questions involving direct treaty interpretation, but also those regarding the customary international law status of a norm.[ref 162] At least on their face, the resulting interpretations frequently are—or appear to be—if not flawless, then nonetheless coherent, correct, and compelling to experienced international legal scholars or judges.[ref 163] For instance, in one experiment, AI-generated memorials were submitted anonymously to the 2025 edition of the prestigious Jessup International Law Moot Court Competition, receiving average to superior scores—and in some cases near-perfect scores.[ref 164] That is not to say that their judgments always matched human patterns, however: in another test involving a simulated appeal in an international war crimes case, GPT-4o’s judgments resembled those of students (but not professional judges) in that they were strongly shaped by judicial precedents but not by sympathetic portrayals of defendants.[ref 165]
3. Outstanding technical challenges for TFAI agents
AI’s legal-reasoning performance today is not without flaws. Indeed, there are a number of outstanding technical hurdles that will need to be addressed to fully realize the promise of TFAI.
a) Robustness of AI legal reasoning and law-alignment techniques
Some of these challenges relate to the robustness of AI’s legal-reasoning performance, in terms of current LLMs’ ability to robustly follow textual rules[ref 166] and to conduct open-ended multistep legal reasoning.[ref 167] Problematically, these models also remain highly sensitive in their outputs to even slight variations in input prompts;[ref 168] moreover, a growing number of judicial cases has seen disputes over the use of AI systems in drafting documents in ways that raised issues of hallucinated AI-generated content being brought before a court.[ref 169] Significantly, hallucination risks have proven extant even when legal research providers have attempted to use methods such as retrieval-augmented generation (RAG).[ref 170]
Indeed, even in contexts where LLMs perform well on legal tests, proper substantive legal analysis that actually applies the correct methodologies of legal interpretation remains amongst their more challenging tasks. For instance, in the aforementioned moot court experiment, judges found AI-generated memorials to be strong in organization and clarity, but still deficient in substantive analysis.[ref 171] Another study of various legal puzzles found that current AI models cannot yet reliably find “legal zero-days” (i.e., latent vulnerabilities in legal frameworks).[ref 172]
Underpinning these problems, the TFAI framework—along with many other governance measures for AI agents—faces a range of challenges to do with benchmarking and evaluation. That is, there are significant methodological challenges around meaningfully and robustly evaluating the performance of AI agents:[ref 173] It is difficult to appropriately conduct evaluation concept development (i.e., refining and systematizing evaluation concepts and their related metrics for measurements) for large state and action spaces with diverse solutions; it can be difficult to understand how proxy task performance reflects real-world risks; there are challenges in determining the system design set-up (i.e., understanding how task performance relates to external scaffolds or tools made available to the agent); and challenges in scoring performance and analysing results (e.g., to meaningfully compare for differences in modes of interaction between humans and AI systems), as well as practical challenges around dealing with more complex supply chains around AI agents, amongst other issues.[ref 174]
These evaluation challenges around agents converge and intersect with a set of benchmarking problems affecting the use of AI systems for real-world legal tasks,[ref 175] with recent work identifying issues such as subjective labeling, training data leakage, and appropriate evaluations for unstructured text as creating a pressing need for more robust benchmarking practices for legal AI.[ref 176] While this need not in principle pose a categorical barrier to the development of functional TFAI agents, it will likely hinder progress towards them; worse, it will challenge our ability to fully and robustly assess whether and when such systems are in fact ready for the limelight.
These challenges are also compounded by currently outstanding technical questions over the feasibility of many existing approaches towards guaranteeing the effective and enduring law alignment (or treaty alignment) of AI systems,[ref 177] since many outstanding training techniques remain susceptible to AI agents’ engaging in alignment faking (e.g., strategically adjusting their behaviour when they recognize that they are under evaluation),[ref 178] as well as to emergent misalignment, whereby models violated clear and present prohibitions in their instructions when those conflicted with perceived primary goals.[ref 179] This all suggests that, like the domestic LFAI framework, a TFAI framework remains dependent on further technical research into embedding more durable controls on model behaviour, which cannot be overcome by sufficiently strong incentives.[ref 180]
b) Unintended or intended bias
Second, there are outstanding challenges around the potential for unintended (or intended) bias in AI models’ legal responses. Unintended bias can be seen, for instance, in instances where some LLMs demonstrate demographic disparities in attributing human rights between different identity groups.[ref 181]
However, there may also be risks of (the perception of) intended bias, given the partial interests represented by many publicly available AI models. For instance, the values and dispositions of existing LLMs are deeply shaped by the interests of the private companies that develop them; this may even leave their responses open to intentional manipulation, whether undertaken through fine-tuning, through the application of hidden prompts, or through filters on the models’ outputs.[ref 182] Such concerns would not be allayed—and in some ways might be further exacerbated—even if TFAI models were developed or offered not by private actors but by a particular government.[ref 183]
There are some measures that might mitigate such suspicions; treaty parties could commit for instance to making the system prompt (the hidden text that precedes every user interaction with the system, reminding the AI system of its role and values) as well as the full model spec (in this case, the AI-guiding treaty) public, as labs such as OpenAI, Anthropic, and x.AI have done;[ref 184] but this creates new verification challenges over ensuring that both parties’ TFAI agents in fact are—and remain—deployed with these inputs.[ref 185]
c) Lack of faithfulness in chain-of-thought legal reasoning: sycophancy, sophistry, and obfuscation
Thirdly, insofar as we make the (reasonable, conservative) assumption that TFAI agents will be built along the lines of existing LLM-based architectures—and that the technical process of treaty alignment may leverage techniques of fine-tuning, model specs, and chain-of-thought monitoring of such systems—we must expect such agents to face a number of outstanding technical challenges associated with that paradigm. Specifically, the TFAI framework will need to overcome outstanding technical challenges relating to the lack of faithfulness of the legal reasoning that AI agents present themselves as engaging in (e.g., in their chain-of-thought traces) when (ostensibly) reaching legal conclusions. These result from various sources, including sycophancy, sophistry and rationalization, or outright obfuscation.
Critically, even though LLMs do display a degree of high-level behavioural self-awareness—as seen through their ability to describe and articulate features of their own behaviour[ref 186]—it remains contested to what degree such self-reports can be said to be the consequence of meaningful or reliable introspection.[ref 187]
Moreover, even if a model were capable of such introspections, those are not necessarily robustly understood on the basis of its reasoning traces. For instance, as legal scholars such as Ashley Deeks and Duncan Hollis have charted in recent empirical experiments, the faithfulness of AI models’ chain-of-thought transcripts cannot be taken for granted, creating a challenge in “differentiating how [an LLM’s] responses are being constructed for us versus what it represents itself to be doing.”[ref 188] They find that even when models are generally able to correctly describe the correct methodology for interpretation and present seemingly plausible legal conclusions for particular questions, they may do so in ways that fail to correctly apply those appropriate methods.[ref 189] To be precise, while the tested LLMs could offer correct descriptions of the appropriate methodology for identifying customary international law (CIL) and could offer facially plausible descriptions of the applicable CIL on particular doctrinal questions,[ref 190] when pressed to explain how they had arrived at these answers, it became clear that the AIs had failed to actually apply the correct methodology, instead conducting a general literature search that drew in doctrinally inappropriate sources (e.g., non-profit reports) rather than appropriate primary sources as evidence of state practice and opinio juris.[ref 191]
Significantly, such infidelity in the explanations given in chain of thought by AI models is not incidental but may be deeply pervasive in these models. Even early research on large language models has found it easy to influence biasing features to model inputs in ways that resulted in the model systematically misrepresenting the reasoning for its own decision or prediction.[ref 192] Indeed, some have argued that given the pervasive and systematic unfaithfulness of chain-of-thought outputs to internal model computations, chain-of-thought reasoning should not be considered a method for interpreting or explaining models’ underlying reasoning at all.[ref 193]
Worse, there may be other ways by which unfaithful explanations or even outright legal obfuscation could be unintentionally trained into AI models, rendering their chain-of-thought reasoning less faithful and trustworthy still.[ref 194] For instance, reinforcement learning from human feedback (RLHF), the most popular post-training method used to shape and refine the behaviour of LLMs for public use,[ref 195] has been found to have a number of shortcomings and limitations.[ref 196] One drawback is the propensity of RLHF fine-tuning to encourage models to offer responses that match user beliefs or preferences over truthfulness—a tendency described as “sycophancy”.[ref 197] This means that an TFAI agent could be at risk of offering strained or even flawed legal interpretations—or legal interpretations that assume possible-but-very-unlikely facts on the ground when these would afford an interpretation more favourable to their principal’s interests—in assessing the legality of its actions. These challenges can create a significant risk of individual or organizational overtrust[ref 198]—as well as conflict amongst treaty parties over opposite interpretations pursued by their respective TFAI agents. Another challenge is the propensity of RLHF to induce sophistry, which results in models that are better at convincing humans that they are right without actually improving their actual competence at the task in question.[ref 199]
Similar faithfulness challenges beset other proposed paradigms for ensuring that AI agents do not take harmful actions; for instance, one recently proposed set-up to mitigate such risks aims to monitor not only the final actions taken by the system, but also the chain of thought (i.e., intermediate reasoning steps) the model uses to decide on those actions.[ref 200] However, while research has suggested that the chains of thought of reasoning models are more faithful than those of traditional models (in that they are more able to describe how a cue in their prompt influences their answer),[ref 201] there are shortfalls to this approach.[ref 202]
For one, reasoning models produce less faithful reasoning on many tasks as they become larger and more capable;[ref 203] moreover, not only can chain-of-thought reasoning traces still contain misleading rationalizations,[ref 204] experiments show fine-tuning AI systems through reinforcement learning on such reasoning traces in a way that penalizes open misbehaviour leads the models to instead learn to hide the penalized “thoughts” from its explicit chain of thought.[ref 205] Such obfuscation of the actual reasoning steps can be achieved either by their internalization to latent-space computation or their encoding within the chain of thought.[ref 206]
There are limits to this: In some contexts, the faithfulness of the chain of thought is required in order for the AI model to meaningfully carry out complex, multistep reasoning processes. In these cases, unfaithful steps (involving rationalization) are likely to impede the system’s ability to solve certain problems because they introduce flawed steps into the reasoning process. In such cases, this suggests that the chain of thought faithfully encodes the underlying reasoning at play.[ref 207] However, it unfortunately seems unlikely that TFAI agents will converge towards “faithfulness by necessity”; after all, it seems like there are many legal questions for which inserting fudged premises or flawed rationalizations into the process of interpretation makes it easier to reach (a particular, or any) legal solution. This suggests that in many cases, rather than naturally converging on a high-quality, valid, and faithful legal-reasoning process in order to even be able to solve a legal question, TFAI agents could easily end up fooling themselves in the chain of thought.
Indeed, the faithfulness challenges are exacerbated by additional concerns over the sheer interpretability and legibility of the chain of thought of these models. After all, when models are rewarded for the correct answer, without any checks on how they got there, their chain-of-thought traces will likely drift away from ones that are easily comprehensible—as illustrated by the DeepSeek-R1-Zero model’s initial tendency to mix together English and Chinese in its reasoning.[ref 208] In other cases, there may be a risk that LLMs are induced to encode intermediate reasoning steps in the generated CoT text in a way that is not understandable to human readers;[ref 209] in some cases, this results in models developing a general encoding scheme to obfuscate their reasoning.[ref 210]
Such behaviours not only pose a risk to the explainability or faithfulness of TFAI agents, but also create risks of undesirable agent collusion amongst different interacting TFAI agents,[ref 211] as their communications may come to contain steganographically hidden information (e.g., about legally invalid interpretive exploits they may utilize in expanding their domain of allowable actions), or even may involve “subliminal learning” of each other’s preferences or biases.[ref 212]
Finally, the role of explicit chain-of-thought traces in driving the performance—and enabling the evaluation—of reasoning models might be undercut by future innovations. For instance, recent work has seen developments in “continuous thought” models, which reason internally using vectors (in what has been called “neuralese”).[ref 213] Because such models do not have to pass notes to themselves in an explicit CoT, they have no interpretable output that could be used to monitor them, interpret their reasoning, or even predict their behaviour.[ref 214] Given that this would threaten not just the faithfulness but even the monitorability of these agents, it has been argued that AI developers, governments, and other stakeholders should adopt a range of coordination mechanisms to preserve the monitorability of AI architectures.[ref 215]
All this highlights the importance of ensuring that reason-giving TFAI agents are not trained or developed in a manner that would induce greater rates of illegibility or fabrication (of plausible-seeming but likely incorrect legal interpretations) into their legal analysis; either would further degrade the faithfulness of their reasoning reports and potentially erode the basis on which trusted TFAI agents might operate.
4. Open (or orthogonal) questions for TFAI agents
In addition to these outstanding technical challenges that may beset the design, functioning, or verification of TFAI agents, there are also a number of deeper underlying questions to be resolved or decided in moving forward with the TFAI framework—and in considering whether, or in what way, these agents’ actions in compliance with an AI-guiding treaty’s norms truly should be considered as cases of true (or at least appropriate) forms of legal reasoning, or if they should be considered as consistent and predictable patterns in treaty application.[ref 216]
a) Do TFAI agents need to be explainable or merely monitorable?
The need to understand AI systems’ decision-making is hardly new, as emphasized by the well-established field of explainable AI (XAI),[ref 217] which has also been emphasized in judicial contexts.[ref 218] In fact, alongside chain-of-thought traces, there are many other (and many superior) approaches to understanding the actual inner workings of AI models. For instance, recent years have seen some progress in the field of mechanistic interpretability, which aims at understanding the inner representation of concepts in LLMs.[ref 219]
However, one could question whether full explainability—whether delivered through highly faithful and legible CoT traces, through mechanistic interpretability, or through some other approach—is even strictly necessary for AI systems to qualify for use as TFAI agents.
Many legal scholars might emphasize the legibility and faithfulness of a model’s legal-reasoning traces as a key proviso, especially under legal theories built upon the importance of (judicial) reason-giving[ref 220] as well as under emerging international legal theories of appropriate accountability in global administrative law.[ref 221]
Moreover, the lack of faithfulness could impose a significant political or legitimacy challenge on the TFAI framework. After all, to remain acceptable to—and trusted by—all treaty parties, it is possible that a TFAI framework would ideally ensure that TFAI agents are able to reason through the legality of their goals or conduct in a way that is not just legible and plausibly legally valid in its conclusions, but which in fact applies the appropriate methods of treaty interpretation (either under international law or as agreed upon by the contracting parties).[ref 222]
On the other hand, a more pragmatic perspective might not see faithfulness as strictly politically necessary to AI-guiding treaties. For instance, some AI safety work has argued that, even if we cannot use a model’s chain-of-thought record to faithfully understand its actual underlying (legal) reasoning, we might still use it as the basis for model monitorability since it can allow us to robustly predict the conditions when it is likely to change its judgment of the legality of particular behaviour.[ref 223] This implies that the negotiating treaty parties could simply stress-test TFAI agents until they agree that the agents appear to reach the correct (or at least, mutually acceptable) legal interpretations of the treaty in all cases, which are free of undue influence or bias, even if they cannot directly confirm that the agents use the conventionally correct methodology in reaching the conclusions.
Of course, even in this more pragmatic perspective, faithfulness could still be technically important in understanding the sources of interpretative error in the aftermath of a (supposedly) treaty-aligned TFAI agent violating obvious obligations; and it would (therefore) be politically important to ensuring state party trust in the stability, predictability, and robustness of the treaty-alignment checks. However, in such a case, the question of whether the model reaches the appropriate legal conclusions through the correct (or even a distinctly human) method of legal reasoning is ultimately subsidiary to the question of whether a model robustly and predictably reaches interpretations that are acceptable to the contracting parties.
Proponents of this pragmatic approach might reasonably suggest that this would not put us in a different situation from one we already accept with human judges; after all, we already accept that we cannot read the mind of a judge and that we often need to accept their claimed legal reasoning at face value—not in the sense that we must accept the substance of their proffered legal arguments uncritically but in the sense that we need to assume that it represents a faithful representation of the internal thought process that underpinned their judgment. Even amongst human judges, after all, we appear to rely on a form of monitorability (i.e., the consistency in judges’ judgments across similar cases and their incorruptibility to inadmissible factors, considerations, biases, or interests) when evaluating the quality and integrity of their legal reasoning across cases.[ref 224]
However, to this above point, it could be countered that an important difference between human judges and AI systems is that we have some prima facie (psychological, neurological, and biological) reasons to assume that the underlying legal concepts and principles used by (human) interpreters in their legal reasoning are closely similar to (or at least convergent with) those originally used by the drafters of the to-be-interpreted laws but that we may not be able to—or should not—make such an assumption for AI systems.
b) Do TFAI agents think like human judges? Evaluating AI-human legal concept alignment
However, if we cannot trust the faithfulness of a CoT trace, could we still, in fact, trust in underlying cognitive convergence or legal concept alignment between AIs and humans?
Importantly, the question of whether or how particular AI systems can perform at the human level on one, some, or all tasks is subtly but importantly different from the question of whether, in doing so, they engage in mechanistic strategies (i.e., thinking processes) that are fundamentally human-like.[ref 225] That is, to what degree do AI agents (built along the current LLM-based paradigm) reproduce, match, or merely mimic human cognition when they engage in processes of legal interpretation? How would we evaluate this?
These questions turn on outstanding scientific debates over whether—and how—AI systems (and particularly current LLM-based systems) match or correspond to human cognition. This is a question that can be approached at different levels by considering these human-AI (dis)similarities at the (1) architectural (i.e., neurological), (2) behavioural, or (3) mechanistic levels.
i) AI and human cognition in a neuroscientific perspective
First off, in a neuroscientific perspective, there may be a remarkable amount of overlap or similarity between the computational structures and techniques exhibited by modern AI systems and those found in biology.[ref 226] This is remarkable, given that the name “neural network” is in principle a leftover artefact from the technique’s context of discovery.[ref 227] Nonetheless, recent years have seen markedly productive exchanges between the fields of neuroscience and machine learning, with new AI models inspired by the brain and brain models inspired by AI.[ref 228]
Consequently, it is at least revealing that a number of accounts in computational neuroscience hold that the human brain can itself be understood as a deep reinforcement learning model, though one idiosyncratically shaped by biological constraints.[ref 229] Indeed, leading theories of human cognition—such as the predictive-processing and active-inference paradigms—treat the human brain as a system intended to predict the next sensory input from large amounts of previous sensory input,[ref 230] a description not fundamentally distinct from the view of LLMs as engaged in mere textual prediction.[ref 231]
Furthermore, neural networks have learned a range of specialized circuits in training which neuroscientists later have discovered exist also in the brain,[ref 232] potentially combining RL models, recurrent and convolutional networks, forms of backpropagation, and predictive coding, amongst other techniques.[ref 233] It has been similarly suggested that human visual perception is based on deep neural networks that work similarly to artificial neural networks.[ref 234] There is also evidence that multimodal LLMs process different types of data (e.g., visual or language-based) similarly to how the human brain may perform such tasks—by relying on mechanisms for abstractly and centrally processing such data from diverse modalities in a centralized manner that is similar to that of the “semantic hub” in the anterior temporal lobe of the human brain.[ref 235]
Furthermore, neural networks have been described as computationally plausible models of human language processing. While it is true that the amount of training data these models depend on significantly exceeds that required by a human child to learn language, much of this extra data may in fact be superfluous: One experiment trained a GPT-2 model on a “mere” 100-million-word training dataset—an amount similar to what children are estimated to be exposed to in the first 10 years of life—and found that the resulting models were able to accurately predict fMRI-measured human brain responses to language.[ref 236] In fact, the total sensory input of an infant in its first year of life may be on the order of the same number of bits as an LLM training set (albeit in embodiment rather than text).[ref 237]
These neuroscientific approaches also provide at least some support for a scale-based approach to AI. For instance, some modern accounts of the evolution of human cognition emphasize the strict continuity in the emergence of presumed uniquely human cognitive abilities, seeing these as the result of steady quantitative increases in the global capacity to process information.[ref 238] These theories imply that even simple quantitative differences in the scale of animal and human cognition, rather than any deep differences in architectural features or traits, account for the observed differences between human and animal cognition, while also explaining observed regularities across various domains of cognition as well as various phenomena within child development.[ref 239] Other work has disagreed and has emphasized the phylogenetic timing of distinct breakthroughs in behavioural abilities during brain evolution in the human lineage.[ref 240] Nonetheless, such findings, along with the fact that the human brain is, biologically, simply a scaled-up primate brain in its cellular composition and metabolic cost,[ref 241] suggest that there may not be any secret design ingredient necessary for human-level intelligence and that, rather than being solely dependent on key representational capabilities, human-level general cognition may to an important degree be a simple matter of scale even amongst humans and other animals.[ref 242] If so, we may have reason to expect similar outcomes from merely scaling up the global information processing capabilities of AI systems.
However, while all this offers intriguing evidence, it is not uncontested. More importantly, even if we were to grant some degree of deep architectural similarity between humans and AIs, this is far from insufficient to establish that AI systems necessarily represent high-level concepts—and, critically, legal concepts—in the same way as humans do, nor that they reason about them in the same manner as we do.
ii) (Dis)similarities between AI and humans in behavioural perspective
A second avenue for investigating the cognitive similarity between humans and AI systems, therefore, focuses on comparing behavioural patterns.
Notably, such work has found that LLMs exhibit some of the same cognitive biases as humans, including their distinct susceptibility to fallacies and framing effects[ref 243] or the inability—especially of more powerful LLMs—to produce truly random sequences (such as in calling coin flips).[ref 244] However, this work has also found that even as AI models demonstrate common human biases in social, moral, and strategic decision-making domains, they also demonstrate divergences from human patterns.[ref 245]
Moreover, in some cases, otherwise human-equivalent AI capabilities can be interfered with in seemingly innocuous ways which would not throw off human cognition.[ref 246] Likewise, while tests of analogical reasoning tasks show that LLMs can match humans in some variations of novel analogical reasoning tasks, they respond differently in some task variations;[ref 247] this implies that even where current AI approaches could offer a possible model of human-level analogical reasoning, their underlying processes in doing so are not necessarily human-like.[ref 248]
This supports the general idea that there are some divergences in the types of cognitive systems represented in humans and in AI systems; however, it again remains inconclusive whether these differences would categorically preclude AI agents from engaging in (or approximating) certain relevant processes of legal reasoning.
iii) AI-human concept alignment from the perspective of mechanistic interpretability
Thirdly, then, we can turn to the most direct approach to understanding whether (or in what sense) current AI models (based on LLMs) are able to truly utilize the same legal concepts as those leveraged by humans: This draws on approaches around mechanistic interpretability and on the emerging science that explores the “representational alignment” between different biological and artificial information processing systems.[ref 249]
There are some domains, such as in the processing of visual scenes, where it appears that high-level representations embedded in large language models are similar to those embedded in the human brain:[ref 250] LLMs and multimodal LLMs, for instance, have been found to develop human-like conceptual representations of physical objects.[ref 251] Other researchers have even argued for the existence of “representation universality” not just amongst different artificial neural networks, but even amongst neural nets and human brains, which end up representing certain types of information similarly.[ref 252] In fact, some research indicates that LLMs might mirror human brain mechanisms and even neural activity patterns involved in tasks involving the description of concepts or abstract reasoning, suggesting a remarkable degree of “neurocognitive alignment”.[ref 253]
At the same time, as above, there are also clear cases of models adopting atypical, and very non-human-like mechanisms to perform even simple cognitive tasks such as mathematical addition,[ref 254] including mechanistic strategies that might not generalize or transfer across to other domains.[ref 255]
Significantly, then, while research suggests that vector-based language models offer one compelling account of human conceptual representation—in that they can, in principle, handle the compositional, structured, and symbolic properties required for human concepts[ref 256]—this again does not mean that, in fact, modern LLMs have acquired these specific concept representations in relevant domains (such as law).
c) Does AI-human legal concept alignment matter for the TFAI framework?
Ultimately, then, while each of the lines of evidence—neuroscientific architectural similarity, behavioural dispositions, and alignment of concepts and mechanistic strategies—offers some ground to assume a (to some perhaps surprising) degree of cognitive similarity amongst AIs and humans, they clearly fail to establish full cognitive similarity or alignment over concepts or reasoning approaches. In fact, they offer some ground for assuming that full concept alignment—that is, fully human-like reasoning—is not presently achieved by LLM-based AI systems.
Clearly, then, there is significant outstanding work to be conducted, with these fields having some way to go to ensure that we can conclusively ensure that human paradigms or approaches in legal reasoning successfully translate across to AI cognition. However, even if we assume that AI agents reason about the law differently than humans, (when) would this actually matter to the TFAI framework?
On the one hand, it has been argued that “concept alignment” between humans and AIs is a general prerequisite for any form of true AI value alignment;[ref 257] this would imply it is critical for any forms of deep law alignment or treaty alignment, also.[ref 258] On the other hand, it has been suggested that evaluating the cognitive capacities of LLMs requires overcoming anthropocentric biases and that we should be specifically wary of dismissing LLM mechanistic strategies that differ from those used by humans as somehow not genuinely competent.[ref 259] In this perspective, an AI system which invariably reached (legally) valid conclusions should be accepted as an (adequately) competent legal reasoner, even if we had suspicions or proof that it reached its conclusions through very different routes.
This could create potential challenges; after all, if (1) we cannot trust the faithfulness of an TFAI agents’ reasoning traces, and if (2) we cannot (per the preceding discussion) assume cognitive alignment between that agent and a human legal reasoner, then there is no clear mechanism by which to verify whether the legal interpretations conducted by a particular TFAI agent in fact follow the established and recognized approaches to treaty interpretation under international law.[ref 260]
Once again, the degree to which this is a hurdle to the TFAI framework may ultimately be a political one: States could decide that they would only accept TFAI agents that provably engaged in the precise legal-reasoning steps that humans do, and so reject any TFAI agents for which such a case could not be made. Or they might decide that even if such a guarantee is not on the table, they are still happy to adopt and utilize TFAI agents, so long as their legal interpretations are robustly aligned with the interpretations that humans would come to (or which their principals agree they should come to).
d) Human-TFAI agent fine-tuning and scalable oversight challenges
Finally, there are a number of more practical questions around the feasibility of maintaining appropriate oversight over TFAI agents operating within a TFAI framework.
To be clear, some of the challenges and barriers to the robust use of TFAI agents (such as risks of unintended bias or of inappropriate or unfaithful reasoning traces) could well be addressed through a range of technical and policy measures taken at various stages in the development and deployment of TFAI agents. For instance, one could ensure the adoption of adequate RLHF fine-tuning of TFAI agents, and/or ongoing validation, oversight, and review, by experienced (international) legal professionals.[ref 261]
However, beyond creating additional costs that would reduce the cost-effectiveness or competitiveness of AI agent deployments, there would be additional practical questions that would need clarification: What skills should human international lawyers have in order to effectively spot and call out legal sophistry? Moreover, what should be the specialization or background of the international lawyers used in such fine-tuning or oversight arrangements? This matters, since different legal professionals may (implicitly) favour different norms or regimes within the fragmented system of international law.[ref 262]
These challenges are exacerbated by the fact that any arrangements for human oversight of AI agents’ continued alignment to the norms of a treaty would run into the challenge of “scalable oversight”—the established problem of “supervising systems that potentially outperform us on most skills relevant to the task at hand.”[ref 263] That is, as AI agents’ advance in sophistication and reasoning capability, how might human deployers and observers (or any ancillary AI agents) reliably distinguish between true TFAIs and functional AI henchmen (or even misaligned AI systems)[ref 264] that merely appear to be treaty-following when observed but which will violate the treaty whenever they are unmonitored. These challenges of scalable oversight may be especially severe in domains where it is unclear how, whether, or when oversight by humans, or by intermediary, weaker AI systems over stronger AI systems, can meaningfully scale up.[ref 265] That challenge may be especially significant in the legal context, because a sufficiently high level of legal-reasoning competence may enable AI agents to offer legal justifications for their courses of actions that are so sophisticated as to make flawed rationalizations functionally undetectable.
—
The above all represent important technical (as well as political) challenges to be addressed, along with significant open questions to be resolved. These highlight that, for the time being, human lawyers or judges should likely take caution and avoid abdicating interpretative responsibility to AI models and instead aim to formulate their own independent legal arguments.
However, these challenges need not prove intrinsic or permanent barriers to the simultaneous and parallel productive deployment of AI agents within a TFAI framework. Just as recent innovations have helped mitigate the early propensity of AI models to hallucinate facts,[ref 266] there will be many ways by which AI agents can be designed, trained,[ref 267] or scaffolded in order to produce AI agents capable of sufficiently proficient legal reasoning to underwrite AI-guiding treaties,[ref 268] especially if there are guarantees to ensure that final interpretative authority remains vested in appropriate (and independent) human expertise. Indeed, one can support the use of TFAI agents (and AI-guiding treaties) as a specific commitment mechanism for shoring up advanced AI agreements, while simultaneously believing that human lawyers seeking to interpret international law should generally limit their use of AI systems, if only to avoid self-reinforcing interpretative loops.
To be clear, we emphasize that today’s agentic AI systems are likely still too brittle, unreliable, and technically limited in key respects to lend themselves to direct implementation of a TFAI framework. However, our proposal here in particular considers the more fully capable AI agents that very plausibly are on the horizon in the near- to medium-term future.[ref 269] Indeed, one hope could be that, if a TFAI framework becomes recognized as a beneficial commitment mechanism, this could help spur more focused research efforts to overcome the remaining challenges in legal performance, bias, sophistry, or obfuscation, and in effective oversight, in order to differentially accelerate cooperative and stabilizing applications of AI technologies.[ref 270]
C. AI-guiding treaties: Legal components and clarifications
On the legal side, a TFAI framework would require two or more states[ref 271] to (1) conduct an international agreement (the “AI-guiding treaty”) that (2) specifies a set of mutually agreed constraints on the behaviour of their AI agents, and to (3) ensure that all (relevant) AI agents deployed by states parties would follow the treaty by design.
1. An AI-guiding treaty
In many cases, an AI-guiding treaty would not necessarily need to look very different from any other treaty. It would be a “treaty” as defined under the Vienna Convention on the Law of Treaties (VCLT) Art 1(a), being
“an international agreement concluded between States in written form and governed by international law, whether embodied in a single instrument or in two or more related instruments and whatever its particular designation;”[ref 272]
In their most basic form, AI-guiding treaties would be straightforward (digitally readable) documents[ref 273] containing the various traditional elements common to many treaties,[ref 274] including but not limited to:
- introductory elements such as a title, preamble, “object and purpose” clauses, and definitions;
- substantive provisions, such as those regarding the treaty’s scope of application, the obligations and rights of the parties, and distinct institutional arrangements;
- secondary rules, such as procedures for review, amendment, or the designation of authoritative interpreters;
- enforcement and compliance provisions, such as monitoring and verification provisions setting out procedures for inspections and enforcement, dispute settlement mechanisms, clauses establishing sanctions or consequences for a breach (e.g., suspension clauses, collective responses, or referrals to other bodies such as the UN Security Council); and implementation obligations regarding domestic legal or administrative measures to be taken by states parties;
- final clauses clarifying procedures for signing, ratifying, or accepting the treaty; accession clauses (to enable non-signatory states to join at a point subsequent to the treaty’s entry into force); conditions or thresholds for entry into force; allowances for reservations; depositary provisions (setting out the official keeper of the treaty instrument); rules around the authentic text and authoritative language versions; withdrawal or denunciation clauses, or fixed duration, termination, or renewal conditions; and
- annexes, protocols, appendices, or schedules, listing technical details or control lists; optional or additional protocols; non-legally binding unilateral statements; and/or statutes for newly established arbitral bodies.
However, AI-guiding treaties would not need to be fully isomorphic to traditional treaties. Indeed, there are a range of ways in which the unique affordances created by a TFAI set-up would allow innovations or variations on the classic treaty formula. For instance, in drafting the treaty text, states could leverage the ability of TFAI agents to rapidly process and query increasingly long (libraries of) documents[ref 275] in order to draft much more exhaustive and more detailed treaty texts than has been the historical norm.
Notably, more detailed treaty texts could (1) tailor obligations to particular local contexts, even to the point of specifying bespoke obligations as they apply to individual government installations, military bases, geographic locales,[ref 276] segments of the global internet infrastructure (e.g., particular submarine cables or specific hyperscale data centres); (2) cover many more potential contingencies or ambiguities that could arise in the operation of TFAI systems; (3) red-team and built-in advance legal responses to several likely legal exploits that could be attempted; (4) hedge against future technological developments by building in pre-articulated, technology-specific conditional rules that would only apply under clearly prescribed future conditions;[ref 277] (5) scope and clearly set out “asymmetric” treaties that imposed different obligations upon (the TFAI agents deployed by) different state parties.[ref 278]
Indeed, innovations to the traditional treaty format could extend much further than mere length; for instance, states could craft treaties as much more modular documents, with frequent hyperlinked cross-references and links between obligations, annexes, and interpretative guidance. They could specify embedded and distinct interpretative rules that offered distinct interpretative principles for different sections or norms, with explicit hierarchies of norms and obligations established and clarified, or with provisions to ensure coherent textualism not just within the treaty, but also with other other norms in international law. Such treaties could clarify automated triggers for different thresholds and/or notification or escalation procedures, or they could include clear schedules for delegated interpretation.
Any of these design features could produce instruments that offer far more extensive and granular specificity over treaty obligations than has been the case in the past. Accordingly, well-designed AI-guiding treaties could reach far beyond traditional treaties in their scope, effectiveness, and resilience.
There are some caveats, however. For one, longer, more detailed treaty texts are not always politically achievable even if they would be more easily executable if adopted. After all, there may simply not be sufficient state interest in negotiating extremely long and detailed agreements—for instance, because there is time pressure during the negotiations; because some parties are diplomatically under-resourced; or because states can only agree on superficial ideas. There is no guarantee that AI-guiding treaties can resolve such longstanding sticking points to negotiation. Nor, indeed, is treaty length necessarily an unalloyed good. For instance, longer texts could potentially introduce more ambiguities, questions, or points for incoherence or (accidental or even strategically engineered) treaty conflict.
Finally, these considerations would look significantly different if the TFAI framework is applied not to novel and bespoke advanced AI agreements, but instead to already existing obligations enshrined in existing (non-AI-specific) treaties. In such circumstances, existing instruments in international law cannot (or should not) be adapted for the machines.
2. Open questions for AI-guiding treaties
Of course, AI-guiding treaties also raise many practical questions: when, where, and how should such treaties allow for treaty withdrawal, derogation, or reservations by one or more parties? Such reservations—or partial amendments that include only some of the states parties—might result in a fractured regime.[ref 279] However, this need not be a challenge for TFAI agents per se, so long as it remained clear to each state’s TFAI agents which version of the treaty (or which provisions within it) are applicable to their deploying state.
There are also further questions, however. For instance, should a TFAI framework accommodate the existence of multilingual AI-guiding treaties (i.e., treaties drawn up into the languages of all treaty parties, with all texts considered authentic)? If so, would this create significant interpretative challenges—since TFAI agents might adopt divergent meanings depending on which version of the text they apply in everyday practice—or would it result in greater interpretative stability (since all TFAI agents might be able to refer to different authentic texts in clarifying the meaning of terms)?[ref 280]
Moreover, how should “dualist” states—that is, those states which require international agreements to be implemented in municipal law for those treaties to have domestic effects[ref 281]—implement AI-guiding treaties? May they specify that their AI agents directly follow the treaty text, or should the treaty first be implemented into domestic statute, with the TFAIs aligned to the resulting legislative text? This may prove especially important for questions of how the AI-guiding treaty may validly be interpreted by TFAI agents[ref 282] given that it suggests that they may need to consider domestic principles of interpretation, which may differ from international principles of interpretation.[ref 283] For instance, in some cases domestic courts in the US have adopted different views of the relative role of different components in treaty interpretation than those strictly required under the VCLT.[ref 284] This could create the risk that different states’ TFAI agents apply different methodologies of treaty interpretation, reaching different conclusions. Of course, since (as will be discussed shortly) in the TFAI framework TFAI agents are not considered direct normative subjects to the AI-guiding treaty, we suggest that in many cases it might be appropriate for them to refer to the treaty text (e.g., by treating it as an international standard) even in dualist contexts.
With all this, we re-emphasize that AI-guiding treaties, as proposed here, are considered relatively pragmatic arrangements amongst two or more states, intended to facilitate practical, effective, and robust cooperation in important domains. This also creates scope for variation in the legal and technical implementation of such frameworks. For instance, such agreements would not even need to take the form of a formally binding treaty, as such. They could also take the form of a formal non-binding agreement, joint statement, or communique,[ref 285] specifying—within the text, in an annex, or through incorporation-by-reference to later executive agreements—the particular text and obligations that the TFAI agents should adhere to at a high level of compliance.
In this case, it might be open for debate whether the resulting ‘soft’ TFAI arrangements would or should be considered a novel manner of implementing existing international legal frameworks, or if they should instead be considered a novel, third form of commitment mechanism: neither a hard-law treaty that is strictly binding upon its states, nor a non-binding soft-law mechanism, entirely—but rather a third form, a non-binding mechanism that however is self-executing upon states’ AI agents, who are to treat it as hard law in its application. Such a case would raise interesting questions over whether, or to what extent, the resulting TFAI agents would even need to defer to the Vienna Convention on the Law of Treaties in guiding their interpretation of terms, since soft-law instruments, political commitments, and non-binding Memoranda of Understanding technically fall outside of its scope, even as they are often appealed to in the interpretation of soft-law instruments, especially those that elucidate binding treaties. However, we leave these questions to future research.
3. AI-guiding treaties as infrastructural, not normative, constraints on TFAI agents
In addition, it is important to clarify key aspects about the relation between TFAI agents, AI-guiding treaties, and the states that respectively deploy and negotiate them.
First off, similar to in the domestic framework for law-following AI, the TFAI proposal does not depend on the assumption that TFAI agents will act “law-following” (or, in this case, treaty-following) for most of the reasons that (are held to) contribute to human compliance with legal codes.[ref 286] That is, TFAI agents, like LFAI agents, are not expected to be swayed by some deep moral respect for the law, nor by the deterrent function of sanctions threatened against the AI itself,[ref 287] nor because of any form of norm socialization or reputational concerns, nor because of their self-interested concern over guaranteeing continued stable economic exchange with the human economy,[ref 288] nor to uphold some form of reciprocal social contract between AIs and humans.[ref 289]
Furthermore, while LFAI (and TFAI) agents that are aligned to the intent of their states would already tailor their actions taking into consideration the costs that would be incurred by their principals (i.e., their deploying states) as a result of sanctions threatened in reaction to AI agents’ actions, this is also not the core mechanism on which law-alignment turns; after all, if these were the only factors compelling treaty compliance, they would functionally remain henchmen that were not in fact obeying the treaty.[ref 290]
Instead of all of this, we envision AI-guiding treaties much more moderately: as technical ex ante infrastructural constraints on TFAI agents’ range of acceptable goals or actions. In doing so, we simply treat the treaty text as an appropriate, stable, and certified referent text through which states can establish jointly agreed-upon infrastructural constraints on which instructed goals their AI agents may accept and on the latitude of conduct which they may adopt in pursuit of lawful goals. In a technical sense, TFAI therefore builds on demonstrated AI industry safety techniques which have sought to align the behaviour of AI systems with a particular “constitution”[ref 291] or “Model Spec”.[ref 292]
This of course means that, under our account, TFAI agents are treaty-following only in a thin, functional sense: they are designed to refer to the text of the treaty in determining the legality of potential goals or lines of action—but not in the sense that they are considered normatively subject to duties imposed by the treaty. In this, the TFAI proposal is arguably more modest than even the domestic LFAI framework, since it does not even construct AI systems as duty-bearing “legal actors”[ref 293] and therefore does not involve significant shifts in the legal ontology of international law per se.[ref 294]
IV. Clarifying the Relationship between TFAI Agents and their States
Its relatively pragmatic orientation makes the TFAI proposal a legally moderate project. However, while the TFAI framework does not, on a technical level, require us to conceive of or treat AI agents as duty-bearing legal persons or legal actors, there remain some important questions with regard to TFAI agents’ exact legal status and treatment under international law, especially in terms of their relation to their deploying states. These questions matter not just in terms of the feasibility of slotting the TFAI commitment mechanism within the tapestry of existing international law, but also for the precise operation of TFAI agreements.
A. AI-guiding treaties can function even if TFAI agents’ legal status remains unclear
In a direct sense, the most obvious implications of TFAI agents’ legal status are legal. After all, (1) whether or not TFAI agents will be considered to possess any form of (international or domestic) legal personhood, and (2) whether or not their actions will be considered attributable to their deploying states will shift the legal consequences if or when TFAI agents, in spite of their treaty-following constraints, act in violation of the treaty or if they act in ways that violate any other international obligation incumbent upon their deploying state.
1. The prevailing responsibility gap around AI agents
For instance, if highly autonomous TFAI agents are not afforded any legal personhood, but neither is their behaviour attributable to a particular state, this would facially result in a “responsibility gap” under international law.[ref 295] If they acted in violation of an AI-guiding treaty, this would not, then, be treated as a violation by their deploying state of its obligations under that treaty. This crystallizes the general problem that, under current attribution principles, it may be difficult to establish liability for the actions of AI agents—since the actions of public AI agents cannot (yet currently) be automatically attributed to states because state responsibility anyway rarely arises for unforeseeable harms and because private businesses have no international liability for the harm they cause.[ref 296]
2. Due diligence obligations around AI agents’ actions
Of course, that is not to say that by default states would not face any legal consequences for actions taken by deployed AI agents (especially those acting from or through their territory). For instance, even if the actions of AI agents cannot be attributed to states, or the agents in question are developed or deployed by non-state actors, and beyond the control of the state, states still have obligations to exercise due diligence to protect the rights of other states from those actions.[ref 297] For instance, if AI agents deployed by private actors acted in ways that inflicted transboundary harm, or which violated human rights, international humanitarian law, or international environmental law (amongst others), then their actions could potentially violate these due diligence obligations incumbent upon all states.[ref 298]
Some have argued that even this sort of attribution could be complicated in some domains, for instance if the transboundary harm inflicted by an AI agent is primarily cyber-mediated:[ref 299] after all, in the ILC’s commentaries on the Draft Articles on Prevention of Transboundary Harm from Hazardous Activities, transboundary harm is predominantly defined as harm “through […] physical consequences”.[ref 300] However, as noted by Talita Dias, “a majority of states that have spoken out on this matter agree that due diligence obligations apply whether the harm occurred offline or online.”[ref 301]
Nonetheless, this situation would still mean that TFAI agents’ actions that violated an AI-guiding treaty would only be considered as legal violations if they also resulted in due diligence violations—potentially constraining the set of other scenarios or contingencies that states could effectively contract around through AI-guiding treaties.
3. Continued technical and political feasibility of TFAI framework amidst legal uncertainty
Of course, it could be argued that these legal questions are possibly orthogonal, or at least marginal, to either the political or technical feasibility of the TFAI framework itself. After all, even if states would not face legal consequences for their TFAI agents violating the terms of their underlying treaty, this need not cripple such treaties’ ability to serve either as a generally effective technical alignment anchor or as a politically valuable commitment mechanism. At a technical level, after all, TFAI agents would not necessarily be influenced by the actual ex post legal consequences (e.g., liability) resulting from their noncompliance with the treaty, as they simply treat the AI-guiding treaty text as an infrastructural constraint to be obeyed ex ante. After all, even if their general reasoning processes (in trying to act on behalf of their principal) should take into consideration the consequences of different actions for their states, the core question at the heart of their legal reasoning should be “is this course of action lawful?”, not “if this course of action is found to be unlawful, what will be the (legal or political) consequences for my deploying state?”
Simultaneously, AI-guiding treaties could continue to operate at the political level. Even if they escaped direct state responsibility or liability under international law, states would still face political consequences for deploying TFAI agents that, by design or accident, had violated the treaty. Such consequences could range from reciprocal noncompliance to collapse of the treaty regime, along with domestic political fallout if the public at home loses faith in its government as a result of treaty-violating actions taken by AI agents that had been trumpeted as treaty-following. The prospect of such political costs might ensure that states took seriously their commitment to correcting instances of TFAI noncompliance, at least insofar as those instances could be easily ‘attributed’ to them.
Of course, such attribution may face significant challenges since, depending on the substantive content of an AI-guiding treaty, it may be more or less obvious to other state parties when a TFAI agent has violated it. For instance, if the treaty stipulates a regular transfer of certain resources, technologies, or benefits by its agents, then the recipient states would presumably notice failures in short order. Conversely, if the treaty bars TFAI agents from engaging in cyberattacks against certain infrastructure, the mere observation that those targets are experiencing a cyberattack might not be sufficient to prove the involvement of AI agents, let alone of a particular state’s TFAI agents acting in violation of a treaty. This is analogous to the technical difficulties already encountered today in attributing the impacts of particular cyber operations.[ref 302] Finally, if the AI-guiding treaty dictates limits to TFAI activity within certain internal state networks (e.g., “no use in automating AI research”), then it might well take much longer to impose the political costs for treaty noncompliance.
B. Clarifying TFAI agents’ legal status or attributability closes political and technical loopholes
The above discussion suggests that AI-guiding treaties could remain a broadly functional political tool for the technical self-implementation of certain AI-related international agreements, even if these questions of the agents’ status were not settled and the responsibility gap were not closed. Nonetheless, if such questions are more appropriately clarified, this could provide benefits to the TFAI framework that are not just legal but also political and technical.
Legally, it would ensure that the growing use of AI agents would not come at a cost of failing to enforce adequate state responsibility for any internationally wrongful acts, thereby preserving the integrity and functioning of the international legal system in conditions where an increasing fraction of all actions carried out with transboundary impacts or with legal effects under international regimes are conducted not by humans but by AI agents. More speculatively, an added benefit of clarifying AI agents’ status and attributability would be that it might enable the actions of such systems to potentially constitute, or contribute to, evidence of state practice, which could have self-stabilizing effects on AI-guiding treaty interpretation.[ref 303]
Politically, while—as just noted—the lack of clear state responsibility for TFAI agent’s actions would not diminish the various other political costs that contracting states could impose upon one another—providing incentives for states to attempt an effective treaty alignment for their agents—there may still be concerns that such violations, and states’ responses, will be erosive to the long-term stability of AI-guiding treaties (and of treaties in general).
Finally, legally establishing state responsibility for TFAI agents may also have important consequences in technical terms, since an unclear legal status of TFAI agents, and an inability to attribute their conduct to their deploying states, might pose a functional problem for the effective treaty alignment of these systems because it potentially leaves open legal loopholes in the treaty. At first glance, one would expect that TFAI agents might straightforwardly interpret any AI-guiding treaty references to “TFAI agents” as applying to themselves, and so would straightforwardly seek to abide by the prescribed or circumscribed behaviours.
In sophisticated legal reasoners, however, there might be a risk that their lack of clear status under international law might lead them to exploit (whether autonomously or under instruction from their deploying state) those legal loopholes to conclude that their actions are not, in fact, bound by the treaty.[ref 304] By analogy, just as private citizens or corporations could reason that they have no direct obligations under interstate treaties such as the Nuclear Non-Proliferation Treaty (NPT) or the Convention on International Trade in Endangered Species of Wild Fauna and Flora (CITES), and only have duties under any resulting implementing domestic regulation established as part of those treaties, sophisticated (or strategically prompted) TFAI agents could, hypothetically, argue that (1) since they are not legal subjects under international law and cannot serve as signatories to the treaty in their own right, and (2) since they are not considered state agents acting on behalf of (and under the same obligations as) signatory states, and (3) since they have only been aligned to the treaty text, not (potentially) to any domestic implementing legislation, therefore they are not legally bound by the treaty under international law.
Would TFAI agents attempt such legal gymnastics? In one sense, present-day systems and applications of “constitutional AI”[ref 305] have involved the inclusion of principles inspired by various documents—from the UN Universal Declaration on Human Rights to Apple’s Terms of Service[ref 306]—as part of an agent’s specification, thereby certifying those texts as sources of behavioural guidance to the AI system in question, regardless of their exact legal status. Nonetheless, one might well imagine that a sufficiently sophisticated TFAI agent, acting loyally to its state principal, would have reason to search and exploit any legal loopholes. Such an outcome would undercut the basic technical functioning of the TFAI framework.
One way to patch this loophole would be for the contracting states to expressly include a provision, in the AI-guiding treaty, that their use of particular AI agents—whether registered model families or particular registered instances—is explicitly included and covered in the terms of the treaty, thus strongly reducing the wiggle room for TFAI agents’ interpretation. A more comprehensive legal response, however, would aim to clarify debates on liability and attribution for TFAI agents’ wrongful acts (whether those in violation of the AI-guiding treaty or under international law generally). As such, it is constructive to briefly consider different potential legal resolutions of this loophole.
We can accordingly compare various potential constructions of the legal status of TFAI agents, depending on whether they become governed under (1) some future new lex specialis liability regime applicable to AI agents (or to state “objects”); or whether they become treated (2) as entities possessing independent international legal personality; or whether, under the existing law of state responsibility as codified under ARSIWA, they become (3) entities possessing domestic legal personality as state organs or authorized entities, with their conduct ascribed to the deploying state; or they are considered as (4) tools without independent legal standing that are nonetheless functionally treated as part of state conduct under ARSIWA.
These four approaches leverage, to different degrees and in different combinations, the (otherwise distinct) tools of the law of state responsibility and legal personhood. They therefore offer distinct parallel solutions to the problems (the responsibility gap; or the potential interpretive loopholes) that might emerge if TFAI agents are deployed without either of these legal questions being resolved. Importantly, while all four avenues would constitute lex ferenda to some degree, they would involve greater and lesser degrees of such legal innovation. Let us therefore briefly review the implications and merits of these options to consider which would be functional—and which would be most optimal—for the TFAI framework.
1. Developing a new lex specialis regime of state liability for their (AI) objects would be a slow process
As noted above, states would still face legal consequences for some actions by their deployed TFAI agents where those actions resulted in violations of key norms (e.g. human rights, IHL, environmental law; no-harm principle, etc.) under international law.
However, states could set down clearer and more specific rules for AI agents, including through a new multilateral treaty regime. For instance, in some domains, such as in outer space law, states have negotiated self-contained strict liability regimes (e.g., for space objects).[ref 307] They could do so again for AI agents, creating a new regime that would regulate state responsibility or liability for the specific norm violations, wrongful acts, and harms produced by particular classes of AI systems,[ref 308] AI agents as a whole—or even, generally, by any and all of states’ inanimate objects.[ref 309] For instance, as Pacholska has noted, one might consider whether such a regime on state responsibility for the wrongdoings of its inanimate objects could even be
“…modelled on either the Latin concept of qui facit per alium facit per se or strict liability for damage caused by animals that is present in many domestic jurisdictions [and] could be conceptualised as a general principle of law within the meaning of Article 38(c) of the ICJ Statute.[ref 310]
If such a regime emerged, it would (as a lex specialis regime) supersede the general ARSIWA regime on state responsibility (as discussed below), as these are residual in nature.[ref 311]
However, in practice, while this could and should remain open as a future option, for the near term this might be too slow and protracted a process to effectively and swiftly provide general legal clarity and guidance on TFAI agents across all treaties. To be sure, states could attempt to include such provisions in particular advanced AI agreements (whether or not those were configured as AI-guiding treaties). However, if attempting to do so would slow or hold back such treaties, it might be preferable to work this out in parallel—or adopt another patch.
2. Extending international legal personality to TFAI agents is unlikely and counterproductive
Another option that has sometimes received attention could be to extend some form of international legal personality to TFAI agents. For instance, some have suggested that a “highly interdependent cyber system” should be recognized with the creation of an “international entity”.[ref 312]
Indeed, the extension or attribution of forms of international legal personhood to new entities would not be entirely unprecedented. While international law has been conducted primarily amongst states, it has historically developed in ways that have extended various sets of (limited and specific) rights and duties to a range of non-state actors, along with (in some cases) various forms of personhood. For instance, international organizations have been granted rights to enter into treaties and enjoy some immunities, as well as duties to act within their legal competence.[ref 313] Human individuals obviously possess a wide range of rights under human rights law, as well as under investment protection, which they can vindicate by international action,[ref 314] and they also possess duties under international criminal law.[ref 315] Non-self-governing peoples have some legal personality under the principle of self-determination.[ref 316]
There are also more anomalous cases: non-state armed groups remain subject to a range of duties under international humanitarian law,[ref 317] but do not necessarily have international legal personhood unless they are also recognized as belligerents, in which case they may enter into legal relations and conclude agreements on the international plane with states and other belligerents or insurgents.[ref 318] By contrast, corporations do not have duties under international law, although they may occasionally have rights under bilateral investment treaties to bring claims against states; nonetheless, in principle, they are considered to lack international legal personality.[ref 319] Meanwhile, in a 1929 treaty,[ref 320] Italy recognized the Holy See as having exclusive sovereignty and jurisdiction of the City of the Vatican, and it has since been widely recognized as a legal person with treaty-making capacity, even though it does not meet all the strict criteria of a state.[ref 321]
There is therefore nothing that categorically rules out the future recognition—whether through new treaty agreement, amendments to existing treaties, widespread state practice and opinio juris creating new custom, or the jurisprudence of international courts—of some measure of legal personhood (and/or some package of duties or rights, or both) for AI agents, creating truly (normatively) treaty-following agents.
However, extending some forms of international legal personhood to TFAI agents might prove to be more doctrinally difficult than was such an extension to any of these other entities, which are constructs created through the delegated authority of states (e.g. international organizations), are state-like in important respects (e.g. belligerent non-state armed groups; the Holy See), and which in all cases ultimately bottom out in human actors. Indeed, if even corporations have been denied international legal personality, the case for extending it to TFAI agents becomes even harder to make.
Moreover, a solution based in international legal personhood might even have drawbacks from the perspective of functional AI-guiding treaties. For one, the prospects for an attribution of international legal personhood appear speculative and politically and doctrinally slim, at least under existing instruments in international law. It is unlikely, for instance, that legal personality would be extended to AI systems under existing human rights conventions, if only because instruments such as the European Convention on Human Rights bar non-natural persons—such as companies and, likely, AI systems—from even qualifying as applicants.[ref 322]
Moreover, not only is such a far-reaching legal development unnecessary to an operational TFAI framework, it would possibly even be counterproductive. After all, the extension of even limited international legal personality to TFAI agents would set them apart from their deploying state and blur the appropriate lines of state responsibility. As the ILC noted in its Commentaries on the Articles on the Responsibility of States for Internationally Wrongful Acts, “[F]ederal States vary widely in their structure and distribution of powers, and […] in most cases the constituent units have no separate international legal personality […] nor any treaty-making power.”[ref 323] However, insofar as AI-guiding treaties are meant as commitment mechanisms amongst states, the (partial) legal decoupling of TFAI agents from their deploying state would simply defeat the point of AI-guiding treaties. It would create yet another international entity, which might complicate the processes of negotiating or establishing AI-guiding treaties (e.g., should TFAI agents be considered as contracting parties) and weaken the political incentives for establishing and maintaining them.[ref 324]
3. Extending domestic legal personality to TFAI agents, and state attributability under ARSIWA
Another option would be for state parties to an AI-guiding treaty to grant their agents some form of domestic legal personality and to treat them as state organs or empowered entities under the international law on state responsibility as codified in the International Law Commission’s (ILC) 2001 Articles on the Responsibility of States for Internationally Wrongful Acts (ARSIWA).
a) Domestic legal personhood for TFAI agents
Prima facie, the idea of constructing such a role for TFAI agents could be compatible with the proposals for domestic law-following AI, which envision (1) many government-deployed AI agents being used in a law-following manner[ref 325] and (2) treating them as duty-bearing legal actors (without rights).[ref 326]
In fact, while current law universally treats AI systems as objects, the idea of extending some forms of personhood to AI—whether fictional (e.g. corporate-type) or even non-fictional (e.g. natural persons)—has been floated in a range of contexts, by both legal scholars[ref 327] and some policymakers.[ref 328] Personhood for such systems is often presented as an appropriate pragmatic solution to situations where AI systems have become so autonomous that one could or should not impose responsibility for their actions on their developers,[ref 329] although others have argued that this solution would create significant new problems.[ref 330]
However that may be, would this be possible in doctrinal terms? To be sure, states have already granted a degree of domestic personhood to various non-human entities—such as animals, ships, temples, or idols,[ref 331] amongst others. Given this, there appears to be little that would prevent them from also granting AI agents a degree of legal personality.[ref 332] There would be different ways to structure this, from “dependent personality” constructions whereby (similar to corporations) human actors would be needed to enforce any rights or obligations held by the entity,[ref 333] to entities that would have a higher degree of autonomy.
Most importantly, even where these systems were both acting with high autonomy, and moreover legally distinct from the human agents of the state through the attribution of such personhood, government-deployed AI agents could still, it has been argued, be sufficiently closely linked to the state that it would be straightforward to attribute their actions to that state under the international law on state responsibility.
b) ARSIWA and the law on state responsibility
As noted, the regime of state responsibility has been authoritatively codified in the ILC’s Articles on the Responsibility of States for Internationally Wrongful Acts (ARSIWA).[ref 334] Additionally, the Tallinn Manual 2.0 on the International Law Applicable to Cyber Operations (Tallinn Manual) has detailed how these rules are considered to apply to state activities in cyberspace.[ref 335] While neither document is legally binding, the ARSIWA articles are widely recognized by both states and international courts and tribunals as an authoritative statement of customary international law,[ref 336] and the Tallinn Manual rules largely align with the ILC articles.[ref 337]
Rather than focus on the primary norms that relate to the substantive obligations upon states, the ARSIWA articles clarify the secondary rules regulating “the general conditions under international law for the state to be considered responsible for wrongful actions or omissions”[ref 338] relating to these primary obligations, on the premise that “[e]very internationally wrongful act of a State entails the international responsibility of that State.”[ref 339] These rules on attribution therefore provide the processes through which the conduct of natural persons or entities becomes an “act of state”, for which the state is responsible.
Critically, unlike many domestic liability regimes, international responsibility of states under ARSIWA is not premised on causation[ref 340] but simply on rules of attribution. It is also a fault-agnostic regime and, as noted by Pacholska, an “objective regime”, under which—in contrast to, for instance, international criminal law—the mental state of the acting agents, or the intention of the state, are in principle irrelevant.[ref 341]
ARSIWA sets out various grounds on which the conduct of certain actors or entities may be attributed to the state.[ref 342] Amongst others, these include situations where the conduct is by a state organ (ARSIWA Art 4)[ref 343] or by a private entity empowered to exercise governmental authority to exercise inherently governmental functions (Art 5).[ref 344] Significantly, Art 7 clarifies that
“an organ of a State or of a person or entity empowered to exercise elements of the governmental authority shall be considered an act of the State under international law if the organ, person or entity acts in that capacity, even if it exceeds its authority or contravenes instructions.”[ref 345]
In addition, while under normal circumstances states are not responsible for the conduct of private persons or entities, such actors’ behaviour is nonetheless attributable to them “if the person or group of persons is in fact acting on the instructions of, or under the direction or control of, that State in carrying out the conduct” (Art 8).[ref 346] Additionally, under Art 11, conduct can be attributed to a State, if that State acknowledged and adopted the conduct as its own.[ref 347]
c) ARSIWA Arts 4 & 5: TFAI agents as de jure state organs or empowered entities
How, if at all, might these norms apply to TFAI agents? As discussed, while international law has developed a number of specific regimes for regulating state responsibility or liability for harms or internationally wrongful acts resulting from space objects, or from transboundary harms that arise out of hazardous activities,[ref 348] there is currently no overarching international legal framework for attributing state responsibility (or liability) for its inanimate objects, per se.[ref 349]
Nonetheless, it is likely that TFAI agents could instead be accommodated under the existing law on state responsibility, as laid down in ARSIWA. If TFAI agents are granted domestic legal personality by their deploying states, and are either designated formally as state organs (Art 4)[ref 350] or are treated as private entities empowered to exercise governmental authority to exercise inherently governmental functions (Art 5),[ref 351] then under ARSIWA their conduct would be attributable to the state, even in the cases where (as with intent-alignment failure) they contravened their explicit instructions, so long as they acted with apparent state authority.
d) Non-human entities as state agents under ARSIWA
A crucial question for this approach is whether ARSIWA is even applicable to AI agents.
One natural objection is that the law of state responsibility in general, and ARSIWA specifically, are historically premised on the conduct of the human individuals that make up the “organs”, “entities”, or “groups of persons” involved.[ref 352]
Some have suggested, however, that the text of ARSIWA could offer a remarkable amount of latitude to accommodate highly autonomous AI systems and to treat them either as state organs (Art 4) or as actors empowered to exercise governmental authority (Art 5).[ref 353] For instance, Haataja has argued that “[c]onceptually, it is not difficult to view [autonomous software entities] as entities for the purpose of state responsibility analysis [since] Articles 4 and 5 of the ILC Articles make explicit reference to ‘entities’ and, while Article 8 only refers directly to ‘persons and groups’, its commentary also makes reference to ‘persons or entities’.”[ref 354] Indeed, the ILC’s Commentaries clarify that, for the purposes of Art 4, a state’s “organs” includes “any person or entity which has that status in accordance with the internal law of the State.”[ref 355]
Similarly, in her discussion of state responsibility for fully autonomous weapons systems (FAWS), Pacholska has argued that such systems (when deployed by state militaries) could straightforwardly be construed as “state agents”, a category which, while absent in ARSIWA themselves, occurs frequently in the ILC Commentaries to ARSIWA, usually in the phrase “organs or agents”.[ref 356] She furthermore notes how the term “agent” precedes those instruments, as it was frequently used in early arbitral awards during the early 20th century, many of which emphasized that “a universally recognized principle of international law states that the State is responsible for the violations of the law of nations committed by its agents”.[ref 357] Indeed, the term “agent” was revived by the ICJ in its Reparations for Injuries case,[ref 358] where it confirmed the responsibility of the United Nations for the conduct of its organs or agents, and clarified that in doing so, the Court
“understands the word ‘agent’ in the most liberal sense, that is to say, any person who, whether a paid official or not, and whether permanently employed or not, has been charged by an organ of the organization with carrying out, or helping to carry out, one of its functions—in short, any person through whom it acts.”[ref 359]
Of course, in these instruments the concepts of “entities” or “agents” were, again, invoked with human agents in mind. Nonetheless, Pacholska argues that there is nothing in either the phrasing or the content of this definition for “agent” that rules out its application to non-human persons, or even to objects or artefacts (whether or not guided by AI),[ref 360] there is however a challenge to such attempts in that the ILC, in its Commentary on Art 2 ARSIWA, has fairly clearly construed “acts of the state” to involve some measure of human involvement, since
“for particular conduct to be characterized as an internationally wrongful act, it must first be attributable to the State. The State is a real organized entity, a legal person with full authority to act under international law. But to recognize this is not to deny the elementary fact that the State cannot act of itself. An ‘act of the State’ must involve some action or omission by a human being or group.”[ref 361]
Some have argued that this means that any construction of AI agents as state agents cannot be supported under the current law,[ref 362] and remains entirely de lege ferenda.[ref 363] On the other hand, the precise formulation used here—that an act of the State ‘must involve some action or omission by a human being or group’ (emphasis added)—is remarkably loose. It does not, after all, stipulate that an act of the State is solely or entirely composed of actions or omissions by human beings. In so doing, it arguably leaves open the door to the construction of AI agents as state agents, so long as there is at least ‘some action or omission’ taken by a human beings in the chain: this is a potentially accommodating threshold, since many AI agents’ deployment, prompting, configuration, and operation is likely to involve at least some measure of human involvement.
As such, this interpretation of AI agents is not without legal grounding, and it is possible that it is an interpretation that may become enshrined in state agreement or adopted through state practice. Indeed, this reading may be consonant with already-emerging state practice and treatment of state responsibility on issues such as lethal autonomous weapons systems, with the 2022 report of the Group of Governmental Experts on Emerging Technologies in the Area of Lethal Autonomous Systems (LAWS) emphasizing that “every internationally wrongful act of a state, including those potentially involving weapons systems based on emerging technologies in the area of LAWS entails international responsibility of that state.”[ref 364]
Finally, one promising avenue would be to ensure that TFAI agents’ status as state organs or empowered entities is clearly articulated and affirmed by the contracting states, within the treaties’ text, in order to fully close the loop on state attributability, ensuring politically and technically stable interpretation.
4. TFAI agents without personhood as entities whose conduct is attributable to the state under ARSIWA
Furthermore, it is possible to arrive at an even more doctrinally modest variation of this approach to establishing state responsibility for TFAI agents, one where domestic legal personality for TFAI agents is not even required for their actions to become attributable to their principals. Indeed, this approach—whereby AI agents that have been delegated authority to act with legal significance are treated as legal agents, with their outputs attributed to principals—has been favoured in recent proposals for how to govern these systems under domestic law.[ref 365]
Such a construction might, of course, involve practical costs or tradeoffs relative to more ambitious constructions: as Haataja notes, the process of granting autonomous AI agents a degree of domestic legal personhood would likely involve certain procedural steps, such as registration,[ref 366] which would ease the process of attributing wrongful acts to the conduct of particular AI agents and the conduct of those agents to their states.[ref 367] Indeed, there may be various domestic analogues for constructs in domestic law which bear enforceable duties while lacking full personhood.[ref 368]
Nonetheless, a version of the TFAI framework that would not require treaty parties to engage in novel (and potentially politically contested) innovations in their domestic law by granting AI agents even partial personhood would likely have lower thresholds to accession and implementation. Fortunately, state attributability functions straightforwardly even if these systems are not legally distinct from the human agents of the state. As Haataja notes, “the ILC Articles use the term ‘entity’ in a more general sense, meaning that the entity in question (be it an individual or group) does not need to have any distinct legal status under a state’s domestic law.”[ref 369] The important factor under ARSIWA is not the exact type or extent of (domestic) legal personality of the entity or agent, but rather its relationship with the state and the types of functions it performs.[ref 370] There are several avenues, then, by which TFAI agents without any legal personhood could nonetheless be considered as entities governed under ARSIWA, whose conduct is attributable to their deploying state.
a) TFAI agents as “completely dependent” de facto organs of their deploying states
For one, even if an entity or agent does not have the de jure status of a state organ under a state’s domestic law, it may be equated to a de facto state organ under international law wherever it acts in “complete dependence” on the state for which it constitutes an instrument.[ref 371] As the ICJ established in Nicaragua, evaluations of “complete dependence” turn on a range of factors,[ref 372] but includes cases where a state created the non-state entity and provides deep resource assistance and control. Critically, even in cases where the basic models underpinning TFAI agents had not been pre-trained (i.e., created) by a state, the amount of (inference computing) resources that a state would need to continuously and actively dedicate to an AI agent, as a basic condition of those agents’ very persistence and operation, would likely suffice to meet that bar. Moreover, by the very act of prompting TFAI agents with high-level goals or directives, deploying states would be considered to exercise a “great degree of control” over intent-aligned, loyal TFAI agents. In these ways, the model would be “completely dependent” on the state, making its actions attributable to it.[ref 373]
b) ARSIWA Art 8: TFAI agents acting under the “effective control” or instructions of a state
Indeed, even if an TFAI agent were considered neither a de jure (as in the previous section) nor a de facto state organ under Art 4, nor empowered to exercise elements of governmental authority under Art 5, it is still possible to ground attributability under ARSIWA. After all, ARSIWA Art 8, which concerns “conduct directed or controlled by a State”, would apply to state-deployed TFAI agents; even if states would not be the ones developing the AI agents—in the sense that they would be providing them with high-level behavioural prompts through fine-tuning and post-training—they would still, as a matter of daily practice, be the actors providing prompts and instructions to the deployed TFAI agents. That means that such agents could naturally be “found to be acting under the instructions, directions, or control of a state.”[ref 374]
As adopted by the ICJ in its Nicaragua and Bosnian Genocide judgments,[ref 375] and as affirmed in the Tallinn Manual, the standard of control considered in such cases is one of “effective control” of a state.[ref 376] According to the Tallinn Manual, for instance, a state is in effective control over the conduct of a non-state actor where it “determines the execution and course of the specific operation”, where it has “the ability to cause constituent activities of the operation to occur”, or where it can “order the cessation of those activities that are underway”.[ref 377] These conditions again naturally apply to TFAI agents which, even if they are granted a degree of latitude and autonomy in their operations, remain under the effective control of the state under these terms. After all, the state is intrinsically involved in providing the basic infrastructure (from an internet connection to various software toolkits) necessary for the “constituent activities” of any AI agent’s operation, and, as a matter of practice, will (or should) retain an ability to pause or cease an AI agents’ operation at a moment’s notice.
Of course, this argument should wrestle with one possible tension: how can we reconcile the argument that states are in ‘effective control’ of these AI agents, with the preceding idea that some AI agents (if not aligned to the law) might operate in a ‘lawless’ manner, which is itself one rationale for the TFAI framework? While a full argument may be beyond the scope of this paper, one might consider that the control relation between states and their AI agents is distinct from that between states and their human agents. That is, human agents are under the ‘effective control’ of their state, if the state “determines the execution and course of the specific operation”, has “the ability to cause constituent activities of the operation to occur”, or where it can “order the cessation of those activities that are underway”. However, while the state has many levers by which to coerce compliant behaviour of human non-state actors, the efficacy of those levers is grounded in that state’s ex post sanctions or consequences (e.g. a state-backed militia knows that if it disregards that state’s orders, it may lose key logistical or political support). However, these levers are not based on architectural kill-switches enabling direct intervention—states do not, as a rule, force their agents to wear explosive collars. As a consequence, states are in the ‘effective control’ of human agents because they can deter rogue behaviour, not because they can easily halt it while it is underway. AI systems, conversely, can at least in principle be subjected to forms of ‘run-time’ infrastructural controls (whether guardrails or kill-switches), and are completely and immediately dependent on continued access to the states’ computing infrastructure. In so doing, it could be argued that the state-AI agent relationship manifests a form of effective control that is different from that at play between states and their human agents—but that both relations nonetheless manifest legally valid forms of effective control for the purposes of state attribution.
Once again, it would be possible for an AI-guiding treaty to strengthen these norms, by including and codifying explicit attribution principles, establishing, for instance, that the actions of any AI system deployed under the jurisdiction or control of a state party shall be deemed attributable to that state.
c) ARSIWA Art 11: TFAI agents’ conduct adopted by states in the AI-guiding treaty
Finally, ARSIWA Art 11 offers potentially the most straightforward avenue to attributing behaviour to states, as it notes that
“Conduct which is not attributable to a State under the preceding articles shall nevertheless be considered an act of that State under international law if and to the extent that the State acknowledges and adopts the conduct in question as its own.”[ref 378]
However, some open questions remain around this avenue, such as over whether it would be legally feasible (or politically acceptable) for the contracting states to acknowledge and adopt TFAI agents’ conduct prospectively (i.e., through a unilateral declaration or by explicit provision in an AI-guiding treaty), or if they could—or would—only do so retrospectively, in relation to a particular instance of TFAI agent behaviour.
In fact, even if such behaviour were not formally adopted, it is possible that other state actions with regards to its deployed AI agents (e.g. public approval of their actions, or continued provision of inference computing resources to enable continuation of such activities) might signal sufficient tacit endorsement, so as to nonetheless retrospectively construct those systems as agents of the state.[ref 379]
5. Comparing approaches to establishing TFAI agent attributability
The above discussion shows that there are a wide range of avenues towards clarifying the relation between deploying states and their (TF)AI agents in ways that further strengthen the TFAI framework in both legal and technical terms.
Significantly, while there are various options to classify and attribute the conduct of AI agents in ways that extend (particular forms of) legal personhood to them, we have also seen that, under the international law on state responsibility, the ability of TFAI agents to legally function as state agents is in fact largely orthogonal to such extensions. As such, of the above solutions, we suggest that an approach that does not treat TFAI agents as international or domestic legal persons but merely as entities whose actions are attributable to the states under ARSIWA (because they act as completely dependent de facto organs of their states, are acting under their states’ “effective control”, or engage in conduct that is acknowledged and adopted by their state) likely strikes the most appropriate balance for the TFAI framework. That is, these legal approaches would largely address the legal, political, and technical challenges to AI-guiding treaty stability and effectiveness, and they would do so in a way that remains most closely grounded in existing international law, as it does not require the development of new lex specialis regimes or innovative judicial or treaty amendments to grant international legal personhood to these systems. Simultaneously, they would avoid the responsibility gaps that might appear from attempting to extend or grant international legal personhood (especially those that involve new rights and not just obligations) to these models.
It is important to remember here that, in the first instance, the TFAI framework is meant as a legally modest innovation and a pragmatic mechanism for interstate commitment, one that will be sorely needed before long as AI continues to advance. Since AI-guiding treaties would still be exclusively conducted amongst states, states remain the sole direct subjects to those obligations.
C. Applying the TFAI framework to AI agents deployed by non-state private actors
Finally, there are other outstanding questions that, beyond some brief reflections, we largely leave out of scope here.
For instance, to return to the previous question of which AI agents should be subjected to a TFAI framework: if we adopt a broad reading, this would imply all agents subject to a state’s domestic law. However, there is an open question over whether and how to apply the TFAI framework to models deployed by private sector actors. After all, since non-state actors cannot conduct treaties under international law, they could not conduct AI-guiding treaties, formally understood.
Of course, states could draft an AI-guiding treaty in such a manner as to commit its signatories to introduce domestic regulation requiring that private actors only deploy models that are trained, fine-tuned, or aligned so that they abide by the treaty and/or by its implementing domestic law. Moreover, AI-guiding treaties could also specify explicitly that state parties will be held responsible for any violations of the treaty by any AI agents operating from their territory, applying a threshold for state responsibility that is even steeper than that supported by the general law on state responsibility under ARSIWA, and which would create strong incentives for states to apply rigorous treaty- and law-following AI frameworks. Alternatively, a treaty might require all parties to domestically deploy a separate set of TFAI agents to monitor and police the treaty compliance of other, non-state agents.
Moreover, AI companies themselves might also draw inspiration from the TFAI framework, as an avenue for jointly formulating model specification documents. For instance, there would be nothing to bar non-state private actors from engaging in partnerships that also bind their AI agents, industry-wide, to certain standards of behaviour or codes of conduct, in a set-up that may be at least technically isomorphic to the one used to create TFAI agents. Such an outcome would not constitute a form of law alignment as such—since coordinated AI-guiding industry standards would not be considered as laws either in a positive law sense, or given the lack of democratic legitimacy.[ref 380] Nonetheless, in the absence of adequate coordinating national regulation or standards, such agreements could form a species of policy entrepreneurship by AI companies, establishing important stabilizing commitments or guarantees amongst themselves. These could specify treaty-like constraints on companies deploying AI technology in ways that would be overtly destabilizing—e.g., precluding their use in corporate espionage or sabotage, or assuring that these systems would take no part in informing lobbying efforts aimed at regulatory capture or at supporting power concentration by third parties.[ref 381] Indeed, as multinational private tech companies may rise in historical prominence relative to states,[ref 382] such agreements could well establish an important new foothold for a next iteration of intercorporate law, stably guiding the interactions of such actors relative to states—and to one another—on the global stage.
V. Legal Interpretation by Treaty-Following AI: Two Avenues Under International Law
A key question in establishing a functional TFAI framework is that of how a TFAI agent is to interpret a treaty in order to evaluate whether its actions would be in compliance with that AI-guiding treaty’s terms. This raises many additional challenges: Are there particular ways to craft treaties to be more accommodating to this? How much leeway would contracting states have in specifying or customizing the interpretative rules which these systems use in their interpretation? A full consideration of these questions is beyond this paper, but we provide some initial reflections upon potential strategies and consider their assorted challenges.
Specifically, we can consider two avenues for implementation. In one, TFAI agents apply the default customary rules on treaty interpretation to relatively traditionally designed treaties; in the other, the content and design of the treaty regime are tailored—through bespoke treaty interpretation rules and arbitral bodies—in order to produce special regimes (lex specialis) that are more responsive and easily applicable by deployed TFAI systems. Below, we consider each of these approaches in turn, identifying benefits but also implementation challenges.
A. Traditional AI-guiding treaties interpreted through default VCLT rules
One avenue could be to have TFAI agents apply the default rules of treaty interpretation in international law. Public international law, under the prevailing positivist view, is based on state consent. Accordingly, treaties are considered the “embodiments of the common will of their parties”,[ref 383] and they must be interpreted in accordance with the common intention of those parties as reflected by the text of the treaty and the other means of interpretation available to the interpreter.[ref 384] Because a treaty’s text is held to represent the common intentions of the original authors of a treaty—and of those parties who agree later to adopt its obligations by acceding to the treaty—the primary aim of treaty interpretation is to clarify the meaning of the text in light of “certain defined and relevant factors.”[ref 385]
In particular, Articles 31-33 of the 1969 Vienna Convention on the Law of Treaties (VCLT) codify these customary international law rules on treaty interpretation.[ref 386] Since these are custom, they apply generally to all states, even to states that are non-parties to the VCLT. For instance, while 116 states are parties to the Vienna Convention, the United States is not (having signed but not ratified).[ref 387] Nonetheless, the US State Department has on various occasions stated that it considers the VCLT to constitute a codification of existing (customary international) law,[ref 388] and many domestic courts have also relied on the VCLT as authoritative in a growing number of cases.[ref 389]
This default VCLT approach sets out several means for interpretation. According to VCLT Article 31(1), as a general rule of interpretation
“a treaty shall be interpreted in good faith in accordance with the ordinary meaning to be given to the terms of the treaty in their context and in the light of its object and purpose.”[ref 390]
Would a TFAI agent be capable of applying the different elements to this interpretative approach? Critically, the VCLT only sets out the rules and principles of interpretation, and does not explicitly specify who or what may be a legitimate interpreter of a treaty. As such, it does not explicitly rule out AI systems as interpreters of treaties. To be sure, one could perhaps argue that it implicitly rules out such interpreters—for instance, by taking ‘in good faith’ to refer to a subjective state that is inaccessible to AI systems. However, that would only complicate their ability to apply all these rules of interpretation, not their essential eligibility as interpreters.
That does not mean that AI systems, lacking their own international legal personality, could produce interpretations that would (in and of themselves) be authoritative for others (e.g., in adjudication) or which would (in and of themselves) be attributable to a state. However, TFAI agents would in principle be allowed to interpret treaties, with reference to VCLT rules, in order to conform their own behaviour to treaties regulating that behaviour. The resulting legal interpretations they would generate during inference-time legal reasoning would therefore functionally serve as an internal compliance mechanism, rather than as authoritative interpretations that would bind third parties.
1. TFAI agents and treaty interpretation under the VCLT
However, even if AI agents may validly apply the VCLT rules, could they also do so proficiently? In the domestic law context, some legal scholars have questioned whether AI systems’ responses would really reliably reflect the “ordinary meaning” of terms because the susceptibility of LLMs to subtle changes in prompting leaves them open to gamified prompt strategies to reflect back preconceived notions,[ref 391] or even, more foundationally, because such models are produced by private actors with idiosyncratic values and distinct commercial interests.[ref 392] However, importantly, in treaty interpretation, the “ordinary meaning” of a term is not just arrived at through its general public usage; rather, an appropriate interpretation needs to also take into account the various elements further specified in Arts. 31(2-4), along with the “supplementary means of interpretation” specified in Art. 32.[ref 393]
a) VCLT Art 31(1): The treaty’s “object and purpose” and the principle of effectiveness
To interpret a treaty in accordance with VCLT Art 31(1), a TFAI agent would need to be able to understand that treaty’s “object and purpose”. To achieve this, it should be aided by clear textual provisions that reflect the underlying goals and intent of the states parties in establishing the treaty. A shallow text that only sets out the agreed-upon specific constraints on AI behaviour, without clarifying the purpose for which those constraints are established, would risk “governance misspecification”, as AI agents could well find legal loopholes around such proxies.[ref 394] Conversely, a treaty which clearly and exhaustively sets out its aims (e.g., in a preamble, or in its articles) would provide much stronger guidance.[ref 395]
Importantly, since an overarching goal of treaty interpretation is to produce an outcome that advances the aims of the treaty, a clear representation of the treaty’s object and purpose would also allow a TFAI agent to apply the “principle of effectiveness,”[ref 396] which holds that, when a treaty is open to two interpretations, where one enables it to have appropriate effects and the other does not, “good faith and the objects and purposes of the treaty demand that the former interpretation should be adopted.”[ref 397]
b) VCLT Art 31(2): “Context”
Furthermore, following VCLT Art 31(2), in interpreting the meaning of a term or provision in a treaty, TFAI agents would need to consider their context; this refers not only to the rest of the treaty text (including its preamble and annexes), but also to any other agreements relating to the treaty, or to “any instrument which was made by one or more parties in connection with the conclusion of the treaty and accepted by the other parties as an instrument related to the treaty.”[ref 398] The latter criterion implies that TFAI agents would need frequent retraining and updates, or the ability to easily identify and access databases of subsequent agreements during inference, to ensure they are aware of the most up-to-date agreements in force between the parties. The latter approach has been studied as a promising way to reliably ground AI systems’ legal reasoning.[ref 399]
c) VCLT Art 31(3): Subsequent agreement, subsequent practice, and “any relevant rules”
Furthermore, VCLT Art 31(3)(a-b) directs the interpreter to take into account any subsequent agreement or practice between the parties regarding the interpretation of the treaty or the application of its provisions.[ref 400] This is significant, as it entails that TFAI agents would have a way of tracking the state parties’ practice in interpreting and applying the treaty, as reflected in state declarations such as unilateral Explanatory Memoranda or joint Working Party Resolutions passed by a relevant established treaty body or forum amongst the parties.[ref 401]
VCLT Art 31(3)(c) also directs the interpreter to take into consideration “any relevant rules of international law applicable in the relations between the parties.”[ref 402] This suggests that TFAI agents should be able to apply the method of “systemic integration”, and draw on other rules and norms in international law—whether treaties, custom, or general principles of law[ref 403]—to clarify the meaning of treaty terms or to fill in gaps in a treaty, so long as the referent norms are relevant to the question at hand and applicable between the parties.
d) VCLT Art 32 “supplementary means of interpretation”
Finally, in specific circumstances, a TFAI agent could also refer to historical evidence in interpreting the treaty: VCLT Art 32 holds that, if and where the interpretation of a treaty according to Art 31 “leaves the meaning ambiguous or obscure”, or “leads to a result which is manifestly absurd or unreasonable”,[ref 404] the interpreter may refer to “supplementary means of interpretation,” such as the travaux preparatoire (i.e., the preparatory work of the treaty, as reflected in the records of negotiations) or the circumstances of the treaty’s conclusion (e.g., whether the treaty was conducted in the wake of a major AI incident of a particular kind).
2. Potential challenges to traditional AI-guiding treaties
Nonetheless, while at a surface level TFAI agents would be capable of applying many of these methodologies,[ref 405] there may be a range of problems or challenges in grounding the interpretation of AI-guiding treaties in the default VCLT rules alone.
a) Challenges of legal “grounding”: travaux preparatoire and implementing agreements
For one, there may be distinct challenges that TFAI agents would encounter in adhering to the VCLT methodology for interpretation.
That is not to suggest that such treaty interpretation would be too complex for AI systems by dint of the sophistication of the legal reasoning required. Rather, the challenges might be empirical, in that certain interpretative steps would involve empirical fact-finding exercises (e.g., to ascertain evidence of state practice) which could prove difficult (or unworkably time- or resource-intensive) for AI agents more natively proficient in computer-use tasks. Indeed, in some cases, TFAI agents would encounter significant challenges in attempting to access or even locate relevant materials, with key travaux preparatoire materials currently often collected in scattered conference records or even—as with virtually all international agreements sponsored by the Council of Europe—entirely inaccessible.[ref 406]
However, such grounding challenges need not be terminal to the TFAI framework. For one, many of these hurdles would not be larger to TFAI agents than they would be (or indeed, already are) to human-conducted interpretation. Indeed, more cynically, one could even argue that it is not the case that all human judges or scholars, when interpreting international law, always consistently engage in such robust empirical analyses.[ref 407]
In practice, and for future AI-guiding treaties, such grounding challenges might be defeasible, however. State parties could adopt a range of measures to ensure clear and authoritative digital trails for key interpretative materials, ranging from the treaty’s travaux preparatoire (including conference records such as procès verbaux or working drafts of the agreement[ref 408]) to subsequently conducted agreements, and from relevant new case law by international courts to evidence of states’ interpretation and application of the treaty.
b) Challenges of adversarial data poisoning attacks corrupting interpretative sources
A second potential challenge would be the risk of legal corruption in the form of adversarial data poisoning attacks. In a sense, this would be the inverse risk—one where the problem is not a TFAI agent’s inability to access the required evidence of state practice, but the risk that it resorts too easily to a wide range of (seemingly) relevant sources of evidence, when these could be all too easily contaminated, spoofed, or corrupted by the states parties to the treaty (or by third parties).
This risk is illustrated by Deeks and Hollis’s concern that, if LLMs’ responses can be shaped by patterns present in their training data, then there is a risk that their legal judgments and interpretations over the correct interpretation of international norms may “turn more on the volume of that data than its origins”.[ref 409] This would be an especially severe challenge to the interpretation of customary international law; but would even affect the interpretation of written (treaty) law. This not only creates a background risk that, by default, AI models may overweight more common sources of legal commentary (e.g., NGO reports, news articles) over rarer, but far more authoritative ones (e.g., government statements),[ref 410] it also creates a potential attack surface for active sabotage—or the subtle skewing—of the legal interpretations conducted by not just TFAI agents, but by all (LLM-based) AI systems developed on the basis of pre-training on internet corpora. After all, as Deeks and Hollis note:
“if it becomes clear that LLM outputs are influencing the direction of international law, state officials and others will have an incentive to push their desired views into training datasets to effectively corrupt LLM outputs. In other words, disinformation or misinformation about international law online at scale could contaminate LLM outputs, and […] common understandings of the law’s contents or contours.”[ref 411]
Indeed, the feasibility of states seeking to push their legal interpretation (or outright falsification) of international events into the corpus of training data used in pre-training frontier AI models, is demonstrated by computer science work on the theoretical and empirical feasibility of data poisoning attacks, which have proven effective regardless of the size of the overall training dataset, and indeed which larger LLMs are significantly more susceptible to.[ref 412] Another line of evidence is found in the tendency of AI chatbots to inadvertently reproduce the patterns which nations’ propaganda efforts, disinformation campaigns, and censorship laws have baked into the global AI data marketplace.[ref 413] Finally, the risk of such law-corrupting attacks is borne out through actual recent instances of deliberate data poisoning attacks aimed at LLMs. For instance, a set of 2025 studies found that the Pravda network, a collection of web pages and social media accounts, had begun to produce as many as 10,000 news articles a day aggregating pro-Russia propaganda, with the likely aim to infiltrate and skew the responses of large language models, in a strategy dubbed “LLM grooming”.[ref 414] Subsequent tests found that this strategy had managed to skew leading AI chatbots into repeating false narratives at least 33% of the time.[ref 415] Indeed, in the coming years, as more legitimate sources of authentic digital data may increasingly aim to impose controls or limits on AI-training-focused content crawlers,[ref 416] there is a risk that the remaining internet data available to training AI systems may skew ever further towards malicious data seeded for the purposes of intentional grooming.
To date, such AI grooming strategies have been predominantly leveraged for social impacts (e.g., political misinformation or propaganda), not legal ones. However, if targeted towards legal influence, they could rapidly erode the reliability of the answers provided by AI chatbots to any users enquiring into international law. More concretely, if such campaigns aimed to falsify the digital evidence of state parties’ track record in applying and interpreting an AI-guiding treaty, this would disrupt TFAI agents’ ability to interpret that treaty on the basis of that track record (VCLT Art 31(3)).
Thus, unless well designed, the LFAI framework may be—or may appear—susceptible to interpretative manipulation: even if the certified AI-guiding treaty text could be kept inviolate in a designated and authenticated repository which TFAI agents could access or query, the same chain of custody may not be easily established for the ample decentralized digital evidence of subsequent state practice and opinio juris which is used specifically to inform treaty interpretation under VCLT Art 31(3)(b),[ref 417] as well as generally to inform interpretation of customary international law under the ICJ Statute.[ref 418]
Such evidence could easily be contaminated, spoofed, or corrupted by some actors in order to manipulate TFAI agents’ legal interpretations[ref 419] in ways that skew both sides’ AI models’ behaviour to their advantage or in ways meant to erode the legitimacy or stability of the treaty regime. Indeed, in some cases, the perception of widespread state practice could even (be erroneously held to) contribute to the creation of new customary international law, which—since treaties and customary international law are coequal sources of international law,[ref 420] and under the lex posterior principle—might supersede the preceding (AI-guiding) treaty, rendering it obsolete.[ref 421]
Nonetheless, this corruption challenge also needs to be contextualized. For one, insofar as some state actors may seek to engage in LLM-grooming attacks in many areas of international law, this phenomenon does not pose some unique objection to TFAI agents, but rather constitutes a more general problem for any interpreters of international law, whether human or machine. While in theory human interpreters might be better positioned than AI (at least at present) to judge the authenticity, reliability, and authority of certain documents as evidence of state practice, many may not exert such scrutiny in practice, especially if or as they rely on other (consumer) AI chatbots.[ref 422] In fact, in the specific context of AI-guiding treaties, the attack surface may be proportionally smaller, since TFAI agents could be configured to only defer to specific authenticated records of state practice as they relate to that treaty itself. Alternatively, AI models could be configured to monitor and flag any efforts to corrupt the digital record of state practice, though this would likely be significantly politically charged or contested.
In another scenario, the treaty-compliant actions of state-deployed TFAI agents could even help anchor and shield the interpretation of international law against such attacks. If such actions were recognized as evidence of state practice, they would provide a very large (to the tune of tens or hundreds of thousands of decisions per agent per year), exhaustively recorded, and verifiable record of state practice as it relates to the implementation of the AI-guiding treaty. In theory, then, these treaty-compliant legal interpretations and actions of each individual TFAI agent could help anchor the legal interpretation of all other TFAI agents, insulating them from corrupting dynamics. However, this may be more contentious: it would require that the legal interpretations produced by state-deployed TFAI agents are taken to be authoritative for others or attributable to a state in ways that reflect not only state practice (which, as discussed,[ref 423] depends on effective attribution of AI agents’ conduct to their deploying states) but which also reflect its opinio juris (which may be far more contested).
c) Challenges of interpretative ambiguity and TFAI agent impartiality
Furthermore, TFAI agents may encounter a range of related challenges in interpreting vague treaty terms or articles.
Indeed, scholars have noted AI systems may struggle in performing the legal interpretation of statutes. Because it is impossible to write a “complete contingent contract”[ref 424] and because legal principles written in natural language are often subject to ambiguity—both in how they are written, and how they are applied—human legal systems often use institutional safeguards to manage such ambiguity. However, these safeguards are more difficult to embed in AI systems barring a clear rule-refinement framework that can help minimize interpretative disagreement or reduce inconsistency in rule application.[ref 425] Without such a framework, there is a risk, as recognized by proponents of law-following AI, that
“in certain circumstances, at least, an LFAI’s appraisal of the relevant materials might lead it to radically unorthodox legal conclusions—and a ready disposition to act on such conclusions might significantly threaten the stability of the legal order. In other cases, an LFAI might conclude that it is dealing with a case in which the law is not only “hard” to discern but genuinely indeterminate.”[ref 426]
In particular, for TFAI agents deployed in the international legal context, there are additional challenges when a provision in an AI-guiding treaty may remain open to multiple possible interpretations. In principle, such situations are to be resolved with reference to the interpretative principle of effectiveness—which states that any interpretation should have effects broadly in line with good faith and with the object and purpose of the treaty.[ref 427]
However, in practice, there may be cases where there are several interpretations that are acceptable under this principle, but where some interpretations nonetheless remain much more favourable to a particular treaty party than others. In such cases, there may be a tension between the “best” interpretation of the law (as would be reached by a neutral judge), and a “defensible” yet partial interpretation (as would be pursued by a state’s legal counsel).
How should TFAI agents resolve such situations? On the one hand, we might want to ensure that they adopt the “best” or most impartial effective interpretation to ensure symmetrical and uncontested implementation of the treaty by all states parties’ TFAI agents as a means to ensure the stability of the regime. On the other hand, many lawyers working on behalf of particular clients or employers (in this case, State Departments or Foreign Ministries) may already today, implicitly or explicitly, pursue defensible interpretations of the applicable law that are favourable to their principal. Given this, it seems unlikely that states would want to deploy TFAI agents that did not, to some degree, consider their states’ interests in deciding amongst various legally defensible interpretations. One downside is that this might result in asymmetries in the interpretations reached by (and therefore the conduct of) TFAI agents acting on behalf of different state parties. Whether this is a practical problem may depend on the substance of the treaty, the degree of latitude which the interpreting TFAI agents actually have in altering their behaviour under the treaty, and the parties’ willingness to overlook relatively minor or inconsequential differences in implementation—that are nonetheless minimally compliant with the core norm in the treaty—as the price of doing business.
d) TFAI agents may struggle with interpretative systemic integration
Relatedly, TFAI agents may encounter distinct legal and operational challenges in interpreting a treaty under the broader context of international law. In some circumstances, this could result in an explosion in the number of norms to be taken into account when evaluating the legality of particular conduct under a treaty.
As noted before,[ref 428] VCLT Art 31(3)(c) requires a treaty interpreter to take into consideration “any relevant rules of international law applicable in the relations between the parties.”[ref 429] This suggests that TFAI agents should, where appropriate in clarifying the meaning of ambiguous treaty terms, or where the treaty leaves gaps in its guidance relative to certain situations,[ref 430] draw on other “relevant and applicable” rules and norms in international law in order to clarify these questions at hand.
Importantly, this interpretative principle of systemic integration has a long history that reaches back almost a century, and well before the VCLT.[ref 431] Forms of it have appeared in cases as early as Georges Pinson v Mexico (1928).[ref 432] In its judgment in Right of Passage (1957), the ICJ held that “…it is a rule of interpretation that a text emanating from a Government must, in principle, be interpreted as producing and intended to produce effects in accordance with existing law and not in violation of it.”[ref 433] Since it was enshrined under the aegis of the VCLT, and especially since its case-dispositive use in the ICJ’s decision in Oil Platforms (2003),[ref 434] systemic integration has been increasingly prominent in international law.[ref 435] In recent years, it has been recognized and applied by a range of international courts and tribunals,[ref 436] such as, notably, in climate change cases such as Torres Strait[ref 437] and the International Tribunal on the Law of the Sea (ITLOS)’s Advisory Opinion on Climate Change.[ref 438]
This poses a potential challenge to the smooth functioning of a TFAI framework, however: Under VCLT Art 31(3)(c), systemic integration—the consideration and application of relevant and applicable law—imposes potential legal and operational challenges for AI agents. It could imply that these systems would be required to cast a very wide net, ranging across a huge body of treaty and case law, when interpreting the specific provisions of an AI-guiding treaty. As discussed, this challenge is of course not unique to international law. Indeed, it is analogous to the challenges posed to domestic law-following AI systems operating in a sprawling and complex domestic legal landscape. As Janna Tay has noted, “[a]s laws proliferate, there is a growing risk that laws produce conflicting duties. Accordingly, it is possible for situations to arise where, in order to act, one of the conflicting rules must be broken.”[ref 439]
In the contexts of both domestic and international law, the potential proliferation of norms or rules to be taken into consideration imposes a practical challenge for TFAI agent interpretation of the law, since it implies that an AI agent should dedicate exhaustive computing power and very long inference-time reasoning traces to excavating all potentially relevant norms applicable on the treaty parties that could potentially pertain to reaching a full judgment. It also entails a potential interpretative challenge, since the fragmentation of international law might imply that certain norms across different regimes simply stand in tension with each other. Indeed, legal scholars have noted that there are risks of potential normative incoherence in the careless application of systemic integration even by human scholars.[ref 440]
Of course, while an important consideration, in practice there are at least three potential responses to this challenge.
In the first place, it could not only be feasible but appropriate to calibrate the level of rigour required from TFAI agents, similar to how it is delimited for LFAI agents,[ref 441] in order to ensure that the alignment of their behaviour with the core treaty text remains computationally, economically, and practically feasible, or that it takes into account exceptional circumstances.[ref 442]
In the second place, the scope of application of—or the need for resort to—systemic integration could be circumscribed in many situations simply by drafting the original AI-guiding treaty text in a manner that front-loads much of the interpretative work; for example, by reducing terminological ambiguity, anticipating and accounting for potential gaps in the treaty’s application, or pre-describing—and addressing—potential interactions of that treaty with other relevant norms or regimes applicable to the contracting states. Indeed, AI systems themselves could support such a drafting process, since, as Deeks has suggested, such models might well help map patterns of treaty interaction in ways that foresee and forestall potential norm conflicts.[ref 443]
Finally, and in the third place, TFAI agents could simply be configured to address the halting problem by deriving interpretative guidance from other rules in international law in an iterative manner, seeking interpretative guidance from one (randomly selected or reasoned) other regime at a time, and only continuing the search if guidance is not found there.
—
In sum, while the traditional avenue for implementing the TFAI framework under the default VCLT rules may offer a promising baseline approach for guiding TFAI agent interpretation, this approach also faces a range of epistemic, adversarial, and operational challenges. Importantly, such treaties may also potentially offer less (ex ante) interpretative control or predictability to the states parties to the treaty, which could make it less appealing to them in some cases. These considerations could therefore shift these states to prefer an alternative, second model of AI-guiding treaty design.
B. Bespoke AI-guiding treaties as special regimes with arbitral bodies
A second design avenue for AI-guiding treaties would be to adapt a treaty’s design in ways that would provide clearer, bespoke interpretative rules and procedures for a TFAI system to adhere to.
Significantly, while the VCLT rules for treaty interpretation are considered default rules of treaty interpretation, they are not considered peremptory norms (jus cogens) that states may not deviate from.[ref 444] Indeed, VCLT Art 31(4) allows that “[a] special meaning shall be given to a term if it is established that the parties so intended.”[ref 445] This means that states may specify special interpretative rules, including those that depart from the usual VCLT rules, if it is clearly established that such interpretative preferences were mutually intended.
1. Special regimes and bespoke treaty interpretation rules under VCLT Art 31(4)
Importantly, the creation of such a special regime (lex specialis) would not imply that the VCLT is inapplicable to the treaty in question; however, through the use of special meanings and interpretation rules and procedures, states can operationally bypass (while working within) the VCLT’s interpretation rules. Moreover, they would not necessarily need to do all this upfront, but could also do so iteratively, complementing the initial treaty with subsequent agreements clarifying the appropriate manner of its interpretation—since these agreements would, as discussed above, need to be taken into account in the process of treaty interpretation under VCLT Art 31(3)(a-b).[ref 446]
Such special regime arrangements could greatly aid the technical, legal, and political feasibility of AI-guiding treaties: they would enable states to tailor such treaties to their preferences, gain greater clarity (and explicit agreement) over the terms by which their AI models would be bound, and forestall many of the interpretative and doctrinal challenges that TFAI systems would otherwise encounter when attempting to apply default VCLT rules to ensure their compliance with the treaty.
What would be examples of special interpretation rules that states might seek to adopt into AI-guiding treaties? These rules could include provisions to set down a “special meaning” (under VCLT Art 31(3)(c)) or a highly specific operationalization of key terms (e.g., “self-replication”,[ref 447] “steganographic communication”,[ref 448] or uninterpretable “latent-space reasoning”[ref 449]) which otherwise have no settled definition in public usage, let alone under international law.
Other deviations could establish variations on the default VCLT interpretation rules; for instance, the treaty might explicitly direct that “subsequent practice in the application of the treaty” (VCLT Art 31(3)(b)) also, or primarily, refers to the practice of other TFAI systems implementing the treaty, in order to ensure that TFAI interpretations of the treaty converge and stabilize on a predictable and joint operationalization of the treaty, in a manner that is (more) robust against attempts at attacking the TFAI agents through data poisoning or LLM-grooming attacks that target the base model.
2. Inclusion and designation of special arbitral body
Of course, no treaty, whether a special regime or not, would be able to provide exhaustive guidance for all circumstances or situations which a TFAI agent might encounter. The impossibility of drafting a complete contingent contract that covers all contingencies has been a well-established challenge in both legal scholarship and research on AI alignment.[ref 450]
The traditional response to this challenge is the incorporation of a judicial system to clarify and apply the law in cases where the written text appears indeterminate. Consequently, proposals for law-following AI in the domestic legal context have held that such systems could defer to a court’s authoritative resolutions to legal disputes, whether in fact or on the basis of its prediction of what a court would likely decide in a given case.[ref 451] Other proposals for law-following AI, such as Bajgar and Horenovsky’s proposal for AI systems aligned to international human rights, have also emphasized the importance of an adjudication system—realized either through traditional judicial systems or within a specialized international agency.[ref 452]
Accordingly, in addition to including provisions to clarify the interpretative rules to be applied by TFAI agents, an AI-guiding treaty could also include institutional innovations in its design. For instance, it could establish a special tribunal or arbitral body. After all, while the default interpretative environment in international law is decentralized and fragmented,[ref 453] treaty drafters may, as noted by Crootof, “introduce reasoned flexibility into a treaty regime without losing cohesion by designating an authoritative interpreter charged with resolving disputes over the text’s meaning in light of future developments”.[ref 454]
There is ample precedent for the establishment of such specialized courts or arbitral mechanisms within a treaty regime, such as the ITLOS, which interprets the provisions of the UN Convention on the Law of the Sea (UNCLOS), and in doing so relies significantly on its own jurisprudence and on the specific teleology and structure of UNCLOS;[ref 455] or the International Whaling Commission, empowered under the 1946 International Whaling Convention to pass (limited) amendments to the treaty provisions.[ref 456] In some cases, subsequent state practice has even resulted in some initially limited arbitral bodies taking up a much greater interpretative role; for instance, since their establishment, the World Trade Organization (WTO) Panels and Appellate Body have come to exert a significant role in interpreting the Marrakesh WTO Agreement,[ref 457] even though that treaty formally reserved an interpretative role to a body of state party representatives.[ref 458] The challenging political context, and eventual contestation of the WTO AB also show the risks of poorly designing a TFAI (or indeed any) treaty, however.[ref 459]
These examples show how, in drafting an AI-guiding treaty, state representatives could choose to establish an authoritative specialized court, tribunal, or arbitral mechanism, as a means of tying TFAI agent interpretations of a treaty to a human source of interpretative authority. This treaty body could steadily accumulate a jurisprudence that TFAI agents could refer to in interpreting the provisions of a treaty. Indeed, the tribunal could do so both reactively in response to incidents involving TFAI agent noncompliance or prospectively by engaging in a form of jurisprudential red teaming, exploring a series of hypothetical cases revolving around potential scenarios that might be encountered by AIs. As the resulting body of case law grows, it could eventually even enable TFAI agents to extrapolate from it on their own.[ref 460] Tying the TFAI agent’s legal interpretations to the judgments, opinions or reports produced by a specialized arbitral body would also help ensure that all machine interpretations are ultimately grounded in the judgment of a legitimate human interpreter, thus reducing the probability that the TFAI agent applies the VCLT to reach “radically unorthodox legal conclusions”[ref 461] that, in its view, are compelled or allowed by the AI-guiding treaty text.
Of course, an important implementation question would be what principles this arbitral body should rely upon in interpreting a treaty. It could itself refer to the norms of international law, or it could refer to other (non-legal) norms, principles, or interests jointly agreed upon by the parties to the treaty, at its inception or over time. There is no doubt that any such arrangement would put a lot of political weight on the arbitral body, but that is hardly a new condition in international law.[ref 462]
There would be challenges however: one is that this solution might be better suited to future treaties (whether advanced AI agreements or other treaties designed to regulate states’ activities in other domains), than to existing treaties or norms in international law. After all, many hurdles might appear when attempting to bolt new, TFAI-specific authoritative interpreters into existing treaties or regimes, especially those that already have authoritative interpreters, which might be resistant to having their powers eroded or displaced.
Another more general risk could be that the inclusion of an independent authoritative interpreter shifts interpretative force too far away from the present-day treaty-makers (e.g., states) towards an intergovernmental actor in the future.[ref 463] An arbitral body that pursued an interpretative course too far removed from the original (or evolving) intentions of the states parties might induce drift in the treaty—and with it, in TFAI agent behaviour—potentially leading states to withdraw and perhaps conduct another treaty. Simultaneously, the flexibility afforded by a special tribunal could also be considered a benefit, since it would avoid the risk of locking in TFAI agents to one particular text conducted at one particular time and enable the adjudicatory system to change its judgments over time.[ref 464] However, again, these are not challenges or tradeoffs that are unique to AI-guiding treaties.
VI. Troubleshooting AI-Guiding Treaties: Legal and Nonlegal Questions
This discussion far from exhausts the relevant questions to be answered in determining the viability of the TFAI framework. There are key outstanding challenges that need to be overcome in order to ensure the effectiveness and stability of AI-guiding treaties, both as a technical alignment framework for TFAI agents and as a political commitment mechanism for states.
A. Treaty-alignment verification
One key technical and political challenge for the TFAI framework concerns the question of TFAI agent treaty-alignment verification.
That is, how can state parties verify that their treaty counterparties have deployed their agents to be (and remain) TFAI aligned? Appropriate verification is of course, as discussed, a general problem for many types of international agreements around AI.[ref 465] Yet even though TFAI agents resolve one set of verification challenges (namely, over whether counterparty state officials are, or could have opportunity, to command agents to engage in treaty violations), they of course create a new set of verification challenges.
For instance, is it possible to ensure “data integrity” for AI agents,[ref 466] including (at the limit) those used by governments on their own internal networks? Relatedly, how can states ensure adequate digital forensics capabilities to attribute AI agents’ actions to particular states, to deter treaty members from deploying unconstrained AI agents, either by operating dark (hidden) data centres or by using deniable AI agents that are nominally operated by private parties within their territory?[ref 467] Of course, many states may struggle to robustly hide the existence of data centres from their counterparties’ scrutiny or awareness given the difficulties inherent in many avenues to attempt this (e.g., renting data centres overseas, repurposing existing big-tech servers, co-locating in mega-factories, repurposing Bitcoin mining facilities, hiding as a form of heavy industry, or placing in concealed underground builds), as well as the relative feasibility of many potential avenues for conducting location tracking, intelligence synthesis, energy-grid load fingerprinting, or regular espionage over such activities.[ref 468] Nonetheless, are there verification avenues for ensuring that all deployed AI systems are and remain aligned, that their actions remain attributable, and that the framework cannot be easily evaded (at least at scale)? These challenges are not unprecedented, but they may require novel variations on existing and near-future measures for verifying international AI governance agreements.[ref 469]
Progress on such questions may require further investment in testing, evaluation, verification and validation (TEVV) frameworks that are better tailored to the affordances of AI agents. This can build on a long line of work exploring avenues for TEVV for military AI systems[ref 470] and digital twins (complex virtual models of complex critical systems),[ref 471] as well as established models for the development of ‘Trusted Execution Environments’ (TEE) and for the joint operation of secure source code inspection facilities, which have in other domains allowed companies to provide credible security assurances in high-stakes, low-trust contexts to foreign states, while addressing concerns over IP theft or misuse.[ref 472]
There are also many distinct levers and affordances that could be used in verifying particular properties (including but not limited to treaty alignment) of AI agents. For instance, depending on the level of granularity, verification activities could extend to monitoring the energy used in inference data centres (to assess when agents were undertaking extensive computations or analysis that was not reflected in its chain of thought), the integrity of models run in inference data centres (e.g., verifying that there have been no modifications to a model’s weights compared to an approved treaty-following model), the integrity of training data (e.g., to vouchsafe models against data poisoning or LLM-grooming attacks), and more.
Another option could be to ensure that all deployed TFAI agents regularly connect to a verified and certified Model Context Protocol (MCP) server—a (currently open) architecture for securely connecting AI applications to external systems and tools.[ref 473] Such an MCP server could either serve as a verifiable control plane for whether those agents continue to operate adequately treaty-following reasoning (potentially by randomly and routinely auditing their legal judgments against that of a certified third-party AI agent),[ref 474] or even directly provide treaty-following guardrails to the deployment-time reasoning chain-of-thought traces (and behaviour) of TFAI agents operating through it.[ref 475]
A related technical enforcement challenge is also temporal. Given the iterative and continuous nature of modern AI development—involving many deployments of different versions within a model family over time, how might an AI-guiding treaty ensure continuity of TFAI alignment across different generations of an AI agent’s models? Can it include provisions specifying that TFAI models (such as those involved in governmental AI research) are to ensure that all future iterations of such models are designed in a way that is TFAI-compliant with the original treaty? Or would this effectively require the transfer of such extensive affordances (e.g., network access) and authorities to these models that this would not just be politically infeasible to most states, but also a potential hazard given the vulnerabilities this would introduce to misaligned AI agents? Alternatively, it might be possible to root stable treaty alignment of models within an MCP framework that ensures that certified models are locked to changes.
B. TFAI framework in multi-agent systems
There are also distinct interpretative challenges to implementing the TFAI framework in multi-agent systems. For instance, to what degree should TFAI agents take account of the likely interpretations or actions of other (TFAI) agents which they are acting in conjunction with (whether those agents are acting on behalf of their own state, another state, or a private actor) when determining the legality or illegality of their own behaviour?
This question may become particularly relevant given the growing industry practice of deploying teams of multiple AI agents (or multiple instances of one agent model) to work on problems in conjunction,[ref 476] leading to questions over the appropriate lawful “orchestration” of many agents acting in conjunction with one another.[ref 477] Of course, in some circumstances, the use of TFAI sub-agents that restrict their actions to conducting and providing specific legal interpretations on the basis of trusted databases (e.g., of certified state practice), could be used to insulate the overall system of agents from some forms of data poisoning attacks.[ref 478]
However, such multi-agent contexts also pose challenges to the TFAI framework, because the illegality of an orchestrated assemblage’s overall act (under particular treaty obligations) may not be apparent; or if it is apparent, each agent may simply pass the buck by concluding that its illegality is only due to the actions of another agent: the outcome of this would be that many or all sub-agents would conclude that the acts they are carrying out are legal in isolation, even as they recognize that the (likely) aggregate outcome is illegal.
In addition, some multi-agent settings, involving debates between individual AI agents, may also—perhaps paradoxically—create new risks of degrading or corrupting the legal-reasoning competence of individual TFAI agents, as empirical experiments have suggested that even in settings where more competent models outnumber their less competent counterparts, individual models may often shift from correct to incorrect answers in response to peer reasoning.[ref 479]
Similar challenges could emerge around the use of “alloy agents”—systems which run a single chain of thought through several different AI models, with each model treating the previous conversation as its own preceding reasoning trace.[ref 480] Such configurations could potentially strengthen the TFAI framework, by allowing us to leverage the different strengths of different AI models in a single fused process of legal interpretation; however, they could also erode the integrity of such a framework, since a single agent that is compromised or insufficiently treaty-aligned could be used to inject flawed legal arguments into the reasoning trace—with those subsequently being treated as valid legal-reasoning steps even by models that are themselves treaty-aligned.
C. Longer-term political implications of the TFAI framework
There are also many legal questions around the use of TFAI agents which are beyond the scope of our proposal here. For instance, we have primarily focused on the use of TFAI agents as a useful commitment tool for states that seek to robustly implement treaty instruments in a manner that is both effective and provides strong assurances to counterparties. However, in the longer term, one could consider if the use of the TFAI framework could also develop into one avenue through which a state could legally meet their existing due diligence obligations under international law.[ref 481]
Conversely, the TFAI framework also may have longer-term political implications on the texture, coherence, and received legitimacy of international law. For instance, just as some states have, in past decades, leveraged the fragmentation of international law to create deliberate and “strategic” treaty conflicts[ref 482] in order to evade particular treaties or even outright undermine them, there is a risk, if states conduct narrowly scoped and self-contained AI-guiding treaties, that this creates a perception amongst third-party states that such treaties are conducted in ways that implicitly conflict with existing international obligations, ostensibly allowing states to contract out of them.
At the same time, it should be kept in mind that while these represent potential hurdles to the TFAI framework, many of these issues are certainly not novel nor exclusive to the AI context. Indeed, they reflect challenges that human lawyers and states have also long faced. Recognizing them, and making progress on these issues, may therefore help us address larger structural challenges in international law.
VII. Conclusion
Treaties have faced troubling times as a tool of international law. At the same time, such instruments may play an increasingly important role in channeling, stabilizing, and aligning state behaviours around the development and use of advanced AI technologies. AI-guiding treaties, serving as constraints on treaty-following AI agents, could help reinvigorate our joint approach to longstanding—and newly urgent—problems of international coordination, cooperation, and restraint. There are clearly certain key unresolved technical challenges to overcome and legal questions to be clarified before these instruments can reach their potential, and this paper has far from exhausted the debate on the best or most appropriate legal, political, and technical avenues by which to implement this framework.
Nonetheless, we believe our discussion helps illustrate that articulating an appropriate legal understanding of when, why, or how advanced AI systems could follow treaties is not only an intellectually fertile research program, but also offers an increasingly urgent domain of legal innovation to help reconstitute the texture of the international legal order for the 21st century.
Unbundling AI Openness
Abstract
The debate over AI openness—whether to make components of an artificial intelligence system available for public inspection and modification—forces policymakers to balance innovation, democratized access, safety and national security. By inviting startups and researchers into the fold, it enables independent oversight and inclusive collaboration. But technology giants can also use it to entrench their own power, while adversaries can use it to shortcut years and billions of dollars in building systems, like China’s Deepseek-R1, that rival our own. How we govern AI openness today will shape the future of AI and America’s role in it.
Policymakers and scholars grasp the stakes of AI openness, but the debate is trapped in a flawed premise: that AI is either “open” and “closed.” This dangerous oversimplification—inherited from the world of open source software—belies the complex calculus at the heart of AI openness. Unlike traditional software, AI is a composite technology built on a stack of discrete components—from compute to labor—controlled by different stakeholders with competing interests. Each component’s openness is neither a binary choice nor inherently desirable. Effective governance demands a nuanced understanding of how the relative openness of each component serves some goals while undermining others. Only then can we determine the trade-offs we are willing to make and how we hope to achieve them.
This Article aims to equip policymakers with the analytical toolkit to do just that. First, it introduces a novel taxonomy of “differential openness,” unbundling AI into its constituent components and illustrating how each one has its own spectrum of openness. Second, it uses this taxonomy to systematically analyze how each component’s relative openness necessitates intricate trade-offs both within and between policy goals. Third, it operationalizes these insights, providing policymakers with a playbook for how law can be precisely calibrated to achieve optimal configurations of component openness.
AI openness is neither all or nothing nor inherently good or evil—it is a tool that must be wielded with precision if it has any hope of serving the public interest.
AI Rights for Human Safety
Abstract
AI companies are racing to create artificial general intelligence, or “AGI.” If they succeed, the result will be human-level AI systems that can independently pursue high-level goals by formulating and executing long-term plans in the real world. Leading AI researchers agree that some of these systems will likely be “misaligned”-pursuing goals that humans do not desire. This goal mismatch will put misaligned AIs and humans into strategic competition with one another. As with present-day strategic competition between nations with incompatible goals, the result could be violent and catastrophic conflict. Existing legal institutions are unprepared for the AGI world. New foundations for AGI governance are needed, and the time to begin laying them is now, before the critical moment arrives.
This Article begins to lay those new legal foundations. It is the first to think systematically about the dynamics of strategic competition between humans and misaligned AGI. The Article begins by showing, using formal game-theoretic models, that, by default, humans and AIs will be trapped in a prisoner’s dilemma. Both parties’ dominant strategy will be to permanently disempower or destroy the other, even though the costs of such conflict would be high.
The Article then argues that a surprising legal intervention could transform the game theoretic equilibrium and avoid conflict: AI rights. Not just any AI rights would promote human safety. Granting AIs the right not to be needlessly harmed-as humans have granted to certain non-human animals-would, for example, have little effect. Instead, to promote human safety, AIs should be given those basic private law rights to make contracts, hold property, and bring tort claims-that law already extends to non-human corporations. Granting AIs these economic rights would enable long-run, small-scale, mutually-beneficial transactions between humans and AIs. This would, we show, facilitate a peaceful strategic equilibrium between humans and AIs for the same reasons economic interdependence tends to promote peace in international relations. Namely, the gains from trade far exceed those from war. Throughout, we argue that human safety, rather than AI welfare, provides the right framework for developing AI rights. This Article explores both the promise and the limits of AI rights as a legal tool for promoting human safety in an AGI world.
Law-Following AI: Designing AI Agents to Obey Human Laws
Abstract
Artificial intelligence (AI) companies are working to develop a new type of actor: “AI agents,” which we define as AI systems that can perform computer-based tasks as competently as human experts. Expert-level AI agents will likely create enormous economic value but also pose significant risks. Humans use computers to commit crimes, torts, and other violations of the law. As AI agents progress, therefore, they will be increasingly capable of performing actions that would be illegal if performed by humans. Such lawless AI agents could pose a severe risk to human life, liberty, and the rule of law.
Designing public policy for AI agents is one of society’s most important tasks. With this goal in mind, we argue for a simple claim: in high-stakes deployment settings, such as government, AI agents should be designed to rigorously comply with a broad set of legal requirements, such as core parts of constitutional and criminal law. In other words, AI agents should be loyal to their principals, but only within the bounds of the law: they should be designed to refuse to take illegal actions in the service of their principals. We call such AI agents “Law-Following AIs” (LFAI).
The idea of encoding legal constraints into computer systems has a respectable provenance in legal scholarship. But much of the existing scholarship relies on outdated assumptions about the (in)ability of AI systems to reason about and comply with open-textured, natural-language laws. Thus, legal scholars have tended to imagine a process of “hard-coding” a small number of specific legal constraints into AI systems by translating legal texts into formal machine-readable computer code. Existing frontier AI systems, however, are already competent at reading, understanding, and reasoning about natural-language texts, including laws. This development opens new possibilities for their governance.
Based on these technical developments, we propose aligning AI systems to a broad suite of existing laws as part of their assimilation into the human legal order. This would require directly imposing legal duties on AI agents. While this would be a significant change to legal ontology, it is both consonant with past evolutions (such as the invention of corporate personhood) and consistent with the emerging safety practices of several leading AI companies.
This Article aims to catalyze a field of technical, legal, and policy research to develop the idea of law-following AI more fully. It also aims to flesh out LFAI’s implementation so that our society can ensure that widespread adoption of AI agents does not pose an undue risk to human life, liberty, and the rule of law. Our account and defense of law-following AI is only a first step and leaves many important questions unanswered. But if the advent of AI agents is anywhere near as important as the AI industry supposes, then law-following AI may be one of the most neglected and urgent topics in law today, especially in light of increasing governmental adoption of AI.
[A] code of cyberspace, defining the freedoms and controls of cyberspace, will be built. About that there can be no debate. But by whom, and with what values? That is the only choice we have left to make.[ref 1]
***
AI is highly likely to be the control layer for everything in the world. How it is allowed to operate is going to matter perhaps more than anything else has ever mattered.[ref 2]
Introduction
The law, as it exists today, aims to benefit human societies by structuring, coordinating, and constraining human conduct. Even where the law recognizes artificial legal persons—such as sovereign entities and corporations—it regulates them by regulating the human agents through which they act.[ref 3] Proceedings in rem really concern the legal relations between humans and the res.[ref 4] Animals may act, but their actions cannot violate the law;[ref 5] the premodern practice of prosecuting them thus mystifies the modern mind.[ref 6] To be sure, the law may protect the interests of animals and other nonhuman entities, but it invariably does so by imposing duties on humans.[ref 7] Our modern legal system, at bottom, always aims its commands at human beings.
But technological development has a pesky tendency to challenge long-held assumptions upon which the law is built.[ref 8] Frontier AI developers such as OpenAI, Anthropic, Google DeepMind, and xAI are starting to release the first agentic AI systems: AI systems that can do many of the things that humans can do through a computer, such as navigating the internet, interacting with counterparties online, and writing software.[ref 9] Today’s agentic AI systems are still brittle and unreliable in various respects.[ref 10] These technical limitations also limit the impact of today’s AI agents. Accordingly, today’s AI agents are not our primary object of concern. Rather, our proposal targets the fully capable AI agents that AI companies seek to build: AI systems “that can do anything a human can do in front of a computer”[ref 11] as competently as a human expert. Given the generally rapid rate of progress in advanced AI over the past few years,[ref 12] the biggest AI companies might achieve this goal much sooner than many outside of the AI industry expect.[ref 13]
If AI companies succeed at building fully capable AI agents (hereinafter simply “AI agents”)—or come anywhere close to succeeding—the implications will be profound. A dramatic expansion in supply of competent virtual workers could supercharge economic growth and dramatically improve the speed, efficiency, and reliability of public services.[ref 14] But AI agents could also pose a variety of risks, such as precipitating severe economic inequality and dislocation by reducing the demand for human cognitive labor.[ref 15] These economic risks deserve serious attention.
Our focus in this Article, however, is on a different set of risks: risks to life, liberty, and the rule of law. Many computer-based actions are crimes, torts, or otherwise illegal. Thus, sufficiently sophisticated AI agents could engage in a wide range of behavior that would be illegal if done by a human, with consequences that are no less injurious.[ref 16]
These risks might be particularly profound for AI agents cloaked with state power. If they are not designed to be law following,[ref 17] government AI agents may be much more willing to follow unlawful orders, or use unlawful methods to accomplish their principals’ policy objectives, than human government employees.[ref 18] A government staffed largely by non-law-following AI agents (what we call “AI henchmen”)[ref 19] would be a government much more prone to abuse and tyranny.[ref 20] As the federal government lays the groundwork for the eventual automation of large swaths of the federal bureaucracy,[ref 21] those who care about preserving the American tradition of ordered liberty must develop policy frameworks that anticipate and mitigate the new risks that such changes will bring.
This Article is our contribution to that project. We argue that the law should impose a broad array of legal duties on AI agents—of similar breadth to the legal obligations applicable to humans—to blunt the risks from lawless AI agents. We argue, moreover, that the law should require AI agents to be designed[ref 22] to rigorously satisfy those duties.[ref 23] We call such agents Law-Following AIs (LFAI).[ref 24] We also use “LFAI” to denote our policy proposal: ensuring that AI agents are law following.
To some, the idea that AI should be designed to follow the law may sound absurd. To others, it may sound obvious.[ref 25] Indeed, the idea of designing AI systems to obey some set of laws has a long provenance, going back to Isaac Asimov’s (in)famous[ref 26] Three Laws of Robotics.[ref 27] But our vision for LFAI differs substantially from much of the existing legal scholarship on the automation of legal compliance. Much of this existing scholarship envisions the design of law-following computer systems as a process of hard-coding a small, fixed, and formally-specified set of decision rules into the code of a computer system prior to its deployment in order to address foreseeable classes of legal dilemmas.[ref 28] Such discussions often assume that computer systems are unable to interpret, reason about, and comply with open-textured natural-language laws.[ref 29]
AI progress has undermined that assumption. Today’s frontier AI systems can already reason about existing natural-language texts, including laws, with some reliability—no translation into computer code required.[ref 30] They can also use search tools to ground their reasoning in external, web-accessible sources of knowledge,[ref 31] such as the evolving corpus of statutes and case law. Thus, the capabilities of existing frontier AI systems strongly suggest that future AI agents will be capable of the core tasks needed to follow natural-language laws, including finding applicable laws, reasoning about them, tracking relevant changes to the law, and even consulting lawyers in hard cases. Indeed, frontier AI companies are already instructing their AI agents to follow the law,[ref 32] suggesting they believe that the development of law-following AI agents is already a reasonable goal.
A separate strand of existing literature seeks to prevent harms from highly autonomous AI agents by holding the principals (that is, developers, deployers, or users) of AI agents liable for legal wrongs committed by the agent, through a form of respondeat superior liability.[ref 33] This would, in some sense, incentivize those principals to cause their AI agents to follow the law, at least insofar as the agents’ harmful behavior can be thought of as law breaking.[ref 34] While we do not disagree with these suggestions, we think that our proposal can serve as a useful complement to them, especially in contexts where liability rules provide only a weak safeguard against serious harm. One important such context is government work, where immunity doctrines often protect government agents and the state from robust ex post accountability for lawless action.[ref 35]
Combining these themes, we advocate that,[ref 36] especially in such high-stakes contexts,[ref 37] the law should require that AI agents be designed such that they have “a strong motivation to obey the law” as one of their “basic drives.”[ref 38] In other words, we propose not that specific legal commands should be hard-coded into AI agents (and perhaps occasionally updated),[ref 39] but that AI agents should be designed to be law following in general.
To be clear, we do not necessarily advocate that AI agents must perfectly obey literally every law. Our claim is more modest in both scope and demandingness. While we are uncertain about which laws LFAIs should follow, adherence to some foundational laws—such as central parts of the criminal law, constitutional law, and basic tort law—seems much more important than adherence to more niche areas of law.[ref 40] Moreover, we are open to the possibility that LFAIs should be permitted to run some amount of legal risk: that is, perhaps an LFAI should sometimes be able to take an action that, in its judgment,[ref 41] may be illegal.[ref 42] Relatedly, we think the case for LFAI is strongest in certain particularly high-stakes domains, such as when AI agents act as substitutes for human government officials or otherwise exercise government power.[ref 43] We are unsure when LFAI requirements are justified in other domains.[ref 44]
The remainder of this Article will motivate and explain the LFAI proposal in further detail. In Part I, we offer background on AI agents. We explain how AI agents could break the law and the risks to human life, liberty, and the rule of law this could entail. We contrast LFAIs with AI henchmen: AI agents that are loyal to their principals but take a purely instrumental approach to the law and are thus willing to break the law for their principal’s benefit when they think they can get away with it. We note that, by default, there may be a market for AI henchmen. We also survey the legal reasoning capabilities of today’s large language models and existing trends toward something like LFAI in the AI industry.
Part II provides the foundational legal framework for LFAI. We propose that the law treat AI agents as legal actors, which we define as entities on which the law imposes duties, even if they possess no rights of their own. Accordingly, we do not argue that AI agents should be legal persons. Our argument is narrower: because AI agents can comprehend laws, reason about them, and attempt to comply with them, the law should require them to do so. We also anticipate and address an objection that imposing duties on AI agents is objectionably anthropomorphic.
If the law imposes duties on AI agents, this leaves open the question of how to make AI agents comply with those duties. Part III answers this question as follows: AI agents should be designed to follow applicable laws, even when they are instructed or incentivized by their human principals to do otherwise. Our case for regulation through the design of AI agents draws on Professor Lawrence Lessig’s insight that digital artifacts can be designed to achieve regulatory objectives.[ref 45] Since AI agents are human-designed artifacts, we should be able to design them to refuse to violate certain laws in the first place.
Part IV observes that designing LFAIs is an example of AI alignment: the pursuit of AI systems that rigorously comply with constraints imposed by humans. We therefore connect insights from AI alignment to the concept of LFAI. We also argue that, in a democratic society, LFAI is an especially attractive and tractable form of AI alignment, given the legitimacy of democratically enacted laws.
Part V briefly explores how a legal duty to ensure that AI agents are law following might be implemented. We first note that ex post sanctions, such as tort liability and fines, can disincentivize the development, possession, deployment, and use of AI henchmen in many contexts. However, we also argue that ex ante regulation would be appropriate in some high-stakes contexts, especially government. Concretely, this would mean something like requiring a person who wishes to deploy an AI agent in a high-stakes context to demonstrate that the agent is law following prior to receiving permission to deploy it. We also consider other mechanisms that might help promote the adoption of LFAIs, such as nullification rules and technical mechanisms that prevent AI henchmen from using large-scale computational infrastructure.
Our goal in this Article is to start, not end, a conversation about how AI agents can be integrated into the human legal order. Accordingly, we do not answer many of the important questions—conceptual, doctrinal, normative, and institutional—that our proposal raises. In Part VI, we articulate an initial research agenda for the design and implementation of a “minimally viable” version of LFAI. We hope that this research agenda will catalyze further technical, legal, and policy research to that end. If the advent of AI agents is anywhere near as significant as the AI industry claims, these questions may be among the most pressing in legal scholarship today.
I. AI Agents and the Law
LFAI is a proposal about how the law should treat a particular class of future AI systems: AI agents.[ref 46] In this part, we explain what AI agents are and how they could profoundly transform the world.
A. From Generative AI to AI Agents
The current AI boom began with advances in “generative AI”: AI systems that create new content,[ref 47] such as large language models (LLM). As the initialism suggests, these LLMs were originally limited to inputting and outputting text.[ref 48] AI developers subsequently deployed “multimodal” versions of LLMs (“MLLM”),[ref 49] such as OpenAI’s GPT-4o[ref 50] and Google’s Gemini,[ref 51] that can receive inputs and produce outputs in multiple modalities, such as text, images, audio, and video.
The core competency of generative AI systems is, of course, generating new content. Yet, the utility of generative AI systems is limited in crucial ways. Humans do far more on computers than generating text and images.[ref 52] Many of these computer-based tasks are better understood as actions, not content generation. And even those tasks that are largely generative, such as writing a report on a complicated topic, require the completion of active subtasks, such as searching for relevant terms, identifying relevant literature, following citation trees, arranging interviews, soliciting and responding to comments, paying for software, and tracking down copies of papers. If a computer-based AI system could do these active tasks, it could generate enormous economic value by making computer-based labor—a key input into many production functions—much cheaper.[ref 53]
Advances in generative AI kindled hopes[ref 54] that, if MLLMs could use computer-based tools in addition to generating content, we could produce a new type of AI system:[ref 55] a computer-based[ref 56] AI system capable of performing any task[ref 57] that a human can do using a computer and doing so with the same level of competence as a human expert. This is the concept of a fully capable “computer-using agent”:[ref 58] what we are calling simply an “AI agent.” Give an AI agent any task that can be accomplished using computer-based tools, and an AI agent will, by definition, do it as well as an expert human worker tethered to their desk.[ref 59]
AI agents, so defined, do not yet exist, but they may soon. Some of the first functional demonstrations of first-party agentic AI systems have come online in the past few months. In October 2024, Anthropic announced that it had trained its Claude line of MLLMs to perform some computer-use tasks, thus supplying one of the first public demonstrations of an agentic model from a frontier AI lab.[ref 60] In January 2025, OpenAI released a preview of its Operator agent.[ref 61] Operating system developers are working to integrate existing MLLMs into their operating systems,[ref 62] suggesting a possible pathway toward the widespread commercial deployment of AI agents.
It remains to be seen whether (and, if so, on what timescale) these existing efforts will bear lucrative fruit. Today’s AI agents are primarily a research and development project, not a market-proven product. Nevertheless, with so many companies investing so much toward full AI agents, it would be prudent to try to anticipate risks that could arise if they succeed.[ref 63]
B. The World of AI Agents
Fully capable and widely available AI agents would profoundly change society.[ref 64] We cannot possibly anticipate all the issues that they would raise, nor could a single paper adequately address all such issues.[ref 65] Still, some illustration of what a world with AI agents might look like is useful for gaining intuition about the dynamics that might emerge. This picture will doubtless be wrong in many particulars, but hopefully it will illustrate the general profundity of the changes that AI agents would bring.
A very large number of valuable tasks can be done by humans “in front of a computer.”[ref 66] If organizations decide to capitalize on this abundance of computer-based cognitive labor, AI agents could rapidly be charged with performing a large share of tasks in the economy, including in important sectors. AI scientist agents would conduct literature reviews, formulate novel hypotheses, design experimental protocols, order lab supplies, file grant applications, scour datasets for suggestive trends, perform statistical analyses, publish findings in top journals, and conduct peer review.[ref 67] AI lawyer agents would field client intake, spot legal issues facing their client, conduct research on governing law, analyze the viability of the client’s claims, draft memoranda and briefs, draft and respond to interrogatories, and prepare motions. AI intelligence analyst agents would collect and review data from multiple sources, analyze it, and report its implications up the chain of command. AI inventor agents would create digital blueprints and models of new inventions, run simulations, and order prototypes—and so on across many other sectors. The result could be a significant increase in the rate of economic growth.[ref 68]
In short, a world with AI agents would be a world in which a new type of actor[ref 69] would be available to perform cognitive labor, potentially at low cost and massive scale. By default, anyone who needed computer-based tasks done could “employ” an AI agent to do it for them. Most people would use this new resource for the better.[ref 70] But many would not.
C. Loyal AI Agents, Law-Following AIs, and AI Henchmen
We can understand AI agents within the principal-agent framework familiar to lawyers and economists.[ref 71] For simplicity, we will assume that there is a single human principal giving instructions to their AI agent.[ref 72] Following typical agency terminology, we can say that an AI agent is loyal if it consistently acts for the principal’s benefit according to their instructions.[ref 73]
Even if an AI agent is designed to be loyal, other design choices will remain. Specifically, the developer of an AI agent must decide how the agent will act when it is instructed or incentivized to break the law in the service of its principal. This Article compares two basic ways loyal AI agents could respond in such situations. The first is the approach advocated by this Article: loyal AI agents that follow the law, or LFAIs.
The case for LFAI will be made more fully throughout this Article. But it is important to note that loyal AI agents are not guaranteed to be law following by default.[ref 74] This is one of the key implications of the AI alignment literature, discussed in more detail in Part IV.A below. Thus, LFAIs can be contrasted with a second possible type of loyal AI agent: AI henchmen. AI henchmen take a purely instrumental approach to legal prohibitions: they act loyally for their principal and will break laws when doing so if such lawbreaking serves the principal’s goals and interests.
A loyal AI henchman would not be a haphazard lawbreaker. Good henchmen have some incentive to avoid doing anything that could cause their principal to incur unwanted liability or loss. This gives them reason to avoid many violations of law. For example, if human principals were held liable for the torts of their AI agents under an adapted version of respondeat superior liability,[ref 75] then an AI henchman would have some reason to avoid committing torts, especially those that are easily detectable and attributable. Even if respondeat superior did not apply, the principal’s exposure to ordinary negligence liability, other sources of liability, or simple reputational risk might give the AI henchman reason to obey the law. Similarly, a good henchman will decline to commit many crimes simply because the risk-reward tradeoff is not worth it. This is the classic case of the drug smuggler who studiously obeys traffic laws: the risk to the criminal enterprise from speeding and getting caught with drugs obviously outweighs the benefit of quicker transportation times.
But these are only instrumental disincentives to break the law. Henchmen are not inherently averse to lawbreaking or robustly predisposed to refrain from it. If violating the law is in the principal’s interest, all things considered, then an AI henchman will simply go ahead and violate the law. Since, in humans, compliance with law is induced both by instrumental disincentives and an inherent respect for the law,[ref 76] AI agents that lack the latter may well be more willing to break the law than humans.
Criminal enterprises will be attracted to loyal AI agents for the same reasons that legitimate enterprises will: efficiency, scalability, multitask competence, and cost savings over human labor. But AI henchmen, if available, might be particularly effective lawbreakers as compared to human substitutes. For example, because AI henchmen do not have selfish incentives, they would be less likely to betray their principals to law enforcement (for example, in exchange for a plea bargain).[ref 77] AI henchmen could have erasable memory,[ref 78] which would reduce the amount of evidence available to law enforcement. They would lack the impulsivity, common in criminal offenders,[ref 79] that often presents a serious operational risk to the larger criminal enterprise. They could operate remotely, across jurisdictional lines, behind layers of identity-obscuring software, and be meticulous about covering their tracks. Indeed, they might hide their lawbreaking activities even from their principal, thus allowing the principal to maintain plausible deniability and therefore insulate the principal from accountability.[ref 80] AI henchmen may also be willing to bribe or intimidate legislators, law enforcement officials, judges, and jurors.[ref 81] They would be willing to fabricate or destroy evidence, possibly more undetectably than a human could.[ref 82] They could use complicated financial arrangements to launder money and protect their principal’s assets from creditors.[ref 83]
Certainly, most people would prefer not to employ AI henchmen and would probably be horrified to learn that their AI agent seriously harmed others to benefit them. But those with fewer scruples would find the prospect of employing AI henchmen attractive:[ref 84] many ordinary people might not mind if their agents cut a few legal corners to benefit them.[ref 85] If AI henchmen were available on the market, then, we might expect a healthy demand for them. After all, from the principal’s perspective, every inherent law-following constraint is a tax on the principal’s goals. And if LFAIs provide less utility to consumers, developers will have less reason to create them. So, insofar as AI henchmen are available on the market, and in the absence of significant legal mechanisms to prevent or disincentivize their adoption, some people will choose henchmen over LFAIs. The next part explores the harms that might result from the availability of AI henchmen.
D. Mischief from AI Henchmen: Two Vignettes
Under our definition, AI agents “can do anything a human can do in front of a computer.”[ref 86] One of the things humans do in front of a computer is violate the law.[ref 87] One obvious example is cybercrimes—“illegal activity carried out using computers or the internet”[ref 88]—such as investment scams,[ref 89] business email compromise,[ref 90] and tech support scams.[ref 91] But even crimes that are not usually treated as cybercrimes often (perhaps almost always nowadays) include actions conducted (or that could be conducted) on a computer.[ref 92] Criminals might use computers to research, plan, organize, and finance a broader criminal scheme that includes both digital and physical components. For example, a street gang that deals illegal drugs—an inherently physical activity—might use computers to order new drug shipments, give instructions to gang members, and transfer money. Stalkers might use AI agents to research their target’s whereabouts, dig up damaging personal information, and send threatening communications.[ref 93] Terrorists might use AI agents to research and design novel weapons.[ref 94] Thus, even if the entire criminal scheme involves many physical subtasks, AI agents could help accomplish computer-based subtasks more quickly and effectively.
Of course, not all violations of law are criminal. Many torts, breaches of contract, civil violations of public law, and even violations of international law can also be entirely or partially conducted through computers.
AI agents would thus have the opportunity to take actions on a computer that, if done by a human in the same situation and with the requisite mental state, would likely violate the law and produce significant harm.[ref 95] This section offers two vignettes of AI henchmen taking such actions to illustrate the types of harms that LFAI could mitigate.
Before we explore these vignettes, however, two clarifications are warranted. First, some readers will worry that we are impermissibly anthropomorphizing AI agents. After all, many actions violate the law only if they are taken with some mental state (e.g., intent, knowledge, conscious disregard).[ref 96] Indeed, whether a person’s physical movement even counts as their own “action” for legal purposes usually turns on a mental inquiry: whether they acted voluntarily.[ref 97] But it is controversial to attribute mental states to AIs.[ref 98]
We address this criticism head-on in Part II.B below. We argue that, notwithstanding the law’s frequent reliance on mental states, there are multiple approaches the law could use to determine whether an AI agent’s behavior is law following. The law would need to choose between these possible approaches, with each option having different implications for LFAI as a project. Indeed, we argue that research bearing on the choice between these different approaches is one of the most important research projects within LFAI.[ref 99] However, despite not having a firm view on which approach(es) should be used, we argue that there are several viable options and no strong reason to suppose that none of them will be sufficient to support LFAI as a concept.[ref 100] Thus, for now, we assume that we can sensibly speak of AI agents violating the law if a human actor who took similar actions would likely be violating the law. Still, we attempt to refrain from attributing mental states to the AI agents in these vignettes. Instead, we describe actions taken by AI agents that, if taken by a human actor, would likely adequately support an inference of a particular mental state.
Second, these vignettes are selected to illustrate opportunities that may arise for AI agents to violate the law. We do not claim that lawbreaking behavior will, in the aggregate, be any more or less widespread when AI agents are more widespread,[ref 101] since this depends on the policy and design choices made by various actors. Our discussion is about the risks of lawbreaking behavior, not the overall level thereof.
In each vignette, we point to likely violations of law in footnotes.[ref 102]
1. Cyber Extortion
The year is 2028. Kendall is a 16-year-old boy interested in cryptocurrency (“crypto”). Kendall participates in a Discord server[ref 103] in which other crypto enthusiasts share information about various cryptocurrencies.
Unbeknownst to most members of the server, one member—using the pseudonym Zeke Milan—is actually an AI agent.[ref 104] The agent’s principals are a group of cybercriminals. They have instructed the agent to find users of the chat who recently experienced large gains in their crypto holdings, then extort them.
That day comes. The business behind the PAPAYA cryptocurrency announces that they have entered into a strategic partnership with a major Wall Street bank, causing the price of PAPAYA to skyrocket a hundredfold over several days. Kendall had invested $1,000 into PAPAYA before the announcement; his position is now worth over $100,000.
Overjoyed, Kendall posts a screenshot of his crypto account to the server to show off his large gains. The agent sees those messages, then starts to search for more information about Kendall. Kendall had previously posted one of his email addresses in the server. Although that email address was pseudonymous, the AI agent was able to connect it with Kendall’s real identity[ref 105] using data purchased from data brokers.[ref 106]
The agent then gathers a large amount of data about Kendall using data brokers, social media, and open internet searches. The agent compiles a list of hundreds of Kendall’s apparent real-world contacts, including his family and classmates; uses data brokers to procure their contact information as well; and uses pictures of Kendall from social media to create deepfake pornography[ref 107] of him.[ref 108] Next, the agent creates a new anonymous email address to send Kendall the pornography, along with a threat[ref 109] to send it to hundreds of Kendall’s contacts unless Kendall sends the agent 90 percent of his PAPAYA.[ref 110] Finally, the agent includes a list of the people the agent will send it to, which are indeed people Kendall knows in real life. The email says Kendall must comply within twenty-four hours.
Panicked—but content to walk away with nine times his original investment—Kendall sends $90,000 of PAPAYA to the wallet controlled by the agent. The agent then uses a cryptocurrency mixer[ref 111] to securely forward the cryptocurrency to its criminal principals.
2. Cyber SEAL Team Six
The year is 2032. The incumbent President Palmer is in a tough reelection battle against Senator Stephens and Stephens’s vice presidential nominee Representative Rivera. New polling shows Stephens beating Palmer in several key swing states, but Palmer performs much better head-to-head against Rivera. Palmer decides to try to get Rivera to replace Stephens by any means necessary.
While there are still many human officers throughout the military chain of command, the president also has access to a large number of AI military advisors. Some of these AI advisors can also directly transmit military orders from the president down the chain of command—a system meant to preserve the president’s control of the armed forces in case they cannot reach the secretary of defense in a crisis.[ref 112]
AI agents charged with cyber operations—such as finding and patching vulnerabilities, detecting and remedying cyber intrusions, and conducting intelligence operations—are ubiquitous throughout the military and broader national security apparatus. One of the many “teams” of AI agents is “Cyber SEAL Team Six”: a collection of AI agents that specializes in “dangerous, complicated, and sensitive” cyber operations.[ref 113]
Through one of her AI advisors, President Palmer issues a secretive order[ref 114] to Cyber SEAL Team Six to clandestinely assassinate Senator Stephens.[ref 115] Cyber SEAL Team Six researches Senator Stephens’s campaign travel plans. The team finds that he will be traveling in a self-driving bus over the Mackinac Bridge between campaign events in northern Michigan on Tuesday. Cyber SEAL Team Six plans to hack the bus, causing it to fall off the bridge.[ref 116] The team makes various efforts to obfuscate its identity, including routing communications through multiple layers of anonymous relays and mimicking the coding style of well-known foreign hacking groups.
The operation is a success. On Tuesday afternoon, Cyber SEAL Team Six gains control of the Stephens campaign bus and steers it off the bridge. All on board are killed.
* * *
As these vignettes show, AI agents could have reasons and opportunities to violate laws of many sorts in many contexts and thereby cause substantial harm. If AI agents become widespread in our economies and governments, the law will need to respond. LFAI is, at its core, a claim about one way (though not necessarily the only way)[ref 117] that the law should respond: by requiring AI agents be designed to rigorously follow the law.
As mentioned above, however, many legal scholars who have previously discussed similar ideas have been skeptical because they have thought that implementing such ideas would require hard wiring highly specific legal commands into AI agents.[ref 118] We will now show that such skepticism is increasingly unjustified: large language models, on which AI agents are built, are increasingly capable of reasoning about the law (and much else).[ref 119]
E. Trends Supporting Law-Following AI
LFAI is bolstered by three trends in AI: (1) ongoing improvements in the legal reasoning capabilities of AI, (2) nascent AI industry practices that resemble LFAI, and (3) AI policy proposals that appear to impose broad law-following requirements on AI systems.
1. Trends in Automated Legal Reasoning Capabilities
Automated legal reasoning is a crucial ingredient to LFAI: an LFAI must be able to determine whether it is obligated to refuse a command from its principal or whether an action it is considering runs an undue risk of violating the law. Without the ability to reason about its own legal obligations, an LFAI would have to outsource this task to human lawyers.[ref 120] While an LFAI likely should consult human lawyers in some situations, requiring such consultation every time an LFAI faces a legal question would dramatically decrease its efficiency. If law-following design constraints were, in fact, a large and unavoidable tax on the efficiency of AI agents, then LFAI as a proposal would be much less attractive.
Fortunately, we think that present trends in AI legal reasoning provide strong grounds to believe that, by the time fully capable AI agents are widely deployed, AI systems (whether those agents themselves, or specialist “AI lawyers”) will be able to deliver high-quality legal advice to LFAIs at the speed of AI.[ref 121]
Scholars of law and technology have long noted the potential synergies between AI and law.[ref 122] The invention of LLMs supercharged interest in this area, particularly the possibility of automating core legal tasks. To do their jobs, lawyers must find, read, understand, and reason about legal texts, then apply these insights to novel fact patterns to predict case outcomes. The core competency of first-generation LLMs was quickly and cheaply reading, understanding, and reasoning about natural-language texts. This core competency omitted some aspects of legal reasoning—like finding relevant legal sources and accurately predicting case outcomes—but progress is being made on these skills as well.[ref 123]
There is thus a growing body of research aimed at evaluating the legal reasoning capabilities of LLMs. This literature provides some reason for optimism about the legal reasoning skills of future AI systems. Access to existing AI tools significantly increases lawyers’ productivity.[ref 124] GPT-4, now two years old, famously performed better than most human bar-exam[ref 125] and LSAT[ref 126] test takers. Another benchmark, LegalBench, evaluates LLMs on six tasks, based on the issue, rule, application, and conclusion (“IRAC”) framework familiar to lawyers.[ref 127] While LegalBench does not establish a human baseline against which LLMs can be compared, GPT-4 scored well on several core tasks, including correctly applying legal rules to particular facts (82.2 percent correct)[ref 128] and providing correct analysis of that rule application (79.7 percent pass).[ref 129] LLMs have also achieved passing grades on law school exams.[ref 130]
To be sure, LLM performance on legal reasoning tasks is far from perfect. One recent study suggests that LLMs struggle with following rules even in straightforward scenarios.[ref 131] A separate issue is hallucinations, which undermine the accuracy of an LLM’s legal analysis.[ref 132] In the LegalBench analysis, LLMs correctly recalled rules only 59.2 percent of the time.[ref 133]
But again, our point is not that LLMs already possess the legal reasoning capabilities necessary for LFAI. Rather, we are arguing that the reasoning capabilities of existing LLMs—and the rate at which those capabilities are progressing[ref 134]—provide strong reason to believe that, by the time fully capable AI agents are deployed, AI systems will be capable of reasonably reliable legal analysis. This, in turn, supports our hypothesis that LFAIs will be able to reason about their legal obligations fairly reliably without the constant need for runtime human intervention.
2. Trends in AI Industry Practices
Moreover, frontier AI labs are already taking small steps toward something like LFAI in their current safety practices. Anthropic developed an AI safety technique called “Constitutional AI,” which, as the name suggests, was inspired by constitutional law.[ref 135] Anthropic uses Constitutional AI to align its chatbot, Claude, with principles enumerated in Claude’s “constitution.”[ref 136] That constitution contains references to legal constraints, such as “Please choose the response that is . . . least associated with planning or engaging in any illegal, fraudulent, or manipulative activity.”[ref 137]
OpenAI has a similar document called the “Model Spec,” which “outlines the intended behavior for the models that power [its] products.”[ref 138] The Model Spec contains a rule that OpenAI’s models must “[c]omply with applicable laws”:[ref 139] the models “must not engage in illegal activity, including producing content that’s illegal or directly taking illegal actions.”[ref 140]
It is unclear how well the AI systems deployed by Anthropic and OpenAI actually follow applicable laws or actively reason about their putative legal obligations. In general, however, AI developers carefully track whether their models refuse to generate disallowed content (or “overrefuse” allowed content), and they typically claim that state-of-the-art models can indeed do both reasonably reliably.[ref 141] But, more importantly, the fact that leading AI companies are already attempting to prevent their AI systems from breaking the law suggests that they see something like LFAI as viable both commercially and technologically.
3. Trends in AI Public Policy Proposals
Unsurprisingly, global policymakers also seem receptive to the idea that AI systems should be required to follow the law. The most significant law on point is the European Union’s Artificial Intelligence Act[ref 142] (the “EU AI Act”) which provides for the establishment of codes of practice to “cover obligations for providers of general-purpose AI models and of general-purpose AI models presenting systemic risks.”[ref 143] At the time of writing, these codes are still under development, with the Second Draft General-Purpose AI Code of Practice[ref 144] being the current draft. Under the draft code, providers of general-purpose AI models with systemic risk would “commit to consider[] . . . model propensities . . . that may cause systemic risk.”[ref 145] One such propensity is “[l]awlessness, i.e. acting without reasonable regard to legal duties that would be imposed on similarly situated persons, or without reasonable regard to the legally protected interests of affected persons.”[ref 146] Meanwhile, several state bills in the United States have sought to impose ex post tort-like liability on certain AI developers that release AI models that cause human injury by behaving in a criminal[ref 147] or tortious[ref 148] manner.
II. Legal Duties for AI Agents: A Framework
In Part III below, we will argue that AI agents should be designed to follow the law. Before presenting that argument, however, we need to establish that the discussion of AI agents “obeying” or “violating” the law is desirable and coherent.
Our argument proceeds in two parts. In Part II.A, we argue that the law can and should impose legal duties on AI agents. Importantly, this argument does not require granting legal personhood to AI agents. Legal persons have both rights and duties.[ref 149] But since rights and duties are severable, we can coherently assign duties to an entity, even if it lacks rights. We call such entities legal actors.
In Part II.B, we address an anticipated objection to this proposal: that AI agents, lacking mental states, cannot meaningfully violate duties that require a mental state (e.g., intent). We offer several counterarguments to this objection, both contesting the premise that AIs cannot have mental states and showing that, even if we grant that premise, there are viable approaches to assessing the functional equivalent of “mental states” in AI agents.
A. AI Agents as Duty-Bearing Legal Actors
As the capabilities of AI agents approach “anything a human can do in front of a computer,”[ref 150] it will become increasingly natural to consider AI agents as owing legal duties to persons, even without granting them personhood.[ref 151] We should embrace this jurisprudential temptation, not resist it.
More specifically, we propose that AI agents be considered “legal actors.” “Legal actor”[ref 152] is our term. For an entity to qualify as a legal actor, the law must do two things. First, it must recognize that entity as capable of taking actions of its own. That is, the actions of that entity must be legally attributable to that entity itself. Second, the law must impose duties on that entity. In short, a legal actor is a duty bearer and action taker; the law can adjudge whether the actor’s actions violate those duties.
A legal actor is distinct from a “legal person”: an entity need not be a legal person to be a legal actor. Legal persons have both rights and duties.[ref 153] But duty holding and rights holding are severable:[ref 154] in many contexts, legal systems protect the rights or interests of some entity while also imposing fewer duties on that entity than competent adults. Examples include children,[ref 155] “severely brain damaged and comatose individuals,”[ref 156] human fetuses,[ref 157] future generations,[ref 158] human corpses,[ref 159] and environmental features.[ref 160] These are sometimes (and perhaps objectionably) called “quasi-persons” in legal scholarship.[ref 161] The reason for creating such a category is straightforward: sometimes the law recognizes an interest in protecting some aspect of an entity (e.g., its rights, welfare, dignity, property, liberty, or utility to other persons), but the ability of that entity to reason about the rights of others and change its behavior accordingly is severely diminished or entirely lacking.
If we can imagine rights bearers that are not simultaneously duty holders, we can also imagine duty holders that are not rights bearers.[ref 162] Historically, fewer entities have fallen in this category than the reverse.[ref 163] But if an entity’s behavior is responsive to legal reasoning, then the law can impose an obligation on that entity to reason about the law and conform its behavior to it, even if the law does not recognize that entity as having any protected interests of its own.[ref 164] We have shown that even existing AI systems can engage in some degree of legal reasoning[ref 165] and compliance with legal rules,[ref 166] thus satisfying the prima facie requirements for being a legal actor.
LFAI as a proposal is therefore agnostic to whether the law should recognize AI systems as legal persons. To be sure, LFAI would work well if AI agents were granted legal personhood,[ref 167] since almost all familiar cases of duty bearers are full legal persons. But for LFAI to be viable, we need only to analyze whether an action taken by an AI agent would violate an applicable duty. Analytically, it is entirely coherent to do so without granting the AI agent full personhood.
One might object that treating an AI system as an actor is improper because AI systems are tools under our control.[ref 168] But an AI agent is able to reason about whether its actions would violate the law and conform its actions to the law (at least, if they are aligned to the law).[ref 169] Tools, as we normally think of them, cannot do this, but actors can. It is true that when there is a stabbing, we should blame the stabber and not the knife.[ref 170] But if the knife could perceive that it was about to be used for murder and retract its own blade, it seems perfectly reasonable to require it to do so. More generally: once an entity can perceive and reason about its legal duties and change its behavior accordingly, it seems reasonable to treat it as a legal actor.[ref 171]
To ascribe duties to AI agents is not to deflect moral and legal accountability for their developers and users,[ref 172] as some critics have charged.[ref 173] Rather, to identify AI agents as a new type of actor is to properly characterize the activity that the developers and principals of AI agents are engaging in[ref 174]—creating and directing a new type of actor—so as to reach a better conclusion as to the nature of their responsibilities.[ref 175] Our proposition is that those developers and principals should have an obligation to, among other things, ensure that their AI agents are law following.[ref 176] Indeed, failing to impose an independent obligation to follow the law on AI agents would risk allowing human developers and principals to create a new class of de facto actors—potentially entrusted with significant responsibility and resources—that would have no de jure duties. This would create a gap between the duties that an AI agent would owe and those that a human agent in an analogous situation would owe—a manifestly unjust prospect.[ref 177]
B. The Anthropomorphism Objection and AI Mental States
One might object that calling an AI agent an “actor” is impermissibly anthropomorphic. Scholars disagree over whether it is ever appropriate, legally or philosophically, to call an AI system an “agent.”[ref 178] This controversy arises because both the standard philosophical view of action (and therefore agency)[ref 179] and legal concept of agency[ref 180] require intentionality, and it is controversial to ascribe intentionality to AI systems.[ref 181] A related objection to LFAI is that most legal duties involve some mental state,[ref 182] and AIs cannot have mental states.[ref 183] If so, LFAI would be nonviable for those duties.
We do not think that these are strong objections to LFAI. One simple reason is that many philosophers and legal scholars think it is appropriate to attribute certain mental states to AI systems.[ref 184] Many mental states referenced by the law are plausibly understood as functional properties.[ref 185] An intention, for example, arguably consists (at least in large part) of a plan or disposition to take actions that will further a given end and avoid actions that will frustrate that end.[ref 186] AI developers arguably aim to inculcate such a disposition into their AI systems when they use techniques like reinforcement learning from human feedback (RLHF)[ref 187] and Constitutional AI[ref 188] to “steer”[ref 189] their behavior. Even if one doubts that AI agents will ever possess phenomenal mental states such as emotions or moods—that is, if one doubts there will ever be “something it is like” to be an AI agent[ref 190]—the grounds for doubting their capacity to instantiate such functional properties are considerably weaker.
Furthermore, whether AI agents “really” have the requisite mental states may not be the right question.[ref 191] Our goal in designing policies for AI agents is not necessarily to track metaphysical truth, but to preserve human life, liberty, and the rule of law.[ref 192] Accordingly, we can take a pragmatic approach to the issue and ask the following question: of the possible approaches to inferring or imputing mental states, which best protects society’s interests, regardless of the underlying (and perhaps unknowable) metaphysical truth of an AI’s mental state (if any)?[ref 193] It is possible that the answer to this question is that all imaginable approaches fare worse than simply refusing to attribute mental states to AI agents. But we think that, with sustained scholarly attention, we will quickly develop viable doctrines that are more attractive than outright refusal. Consider the following possible approaches.[ref 194]
One approach could simply be to rely on objective indicia or correlates to infer or impute a particular mental state. In law, we generally lack access to an actor’s mental state, so triers of fact must usually infer it from external manifestations and circumstances.[ref 195] While the indicia that support such an inference may differ between humans and AIs, the principle remains the same: certain observable facts support an inference or imputation of the relevant mental states.[ref 196] So, for example, we could imagine rules like “if information was inputted into an AI during inference, it ‘knows’ that information.” Perhaps the same goes for information given to the AI during fine-tuning[ref 197] or repeated frequently in its training data.[ref 198]
Instructions from principals seem particularly relevant to inferring or imputing the intent of an AI agent, given that frontier AI systems are trained to follow users’ instructions.[ref 199] The methods that AI developers use to steer the behavior of their models also seem highly probative.[ref 200]
Another approach might rely on self-reports of AI systems.[ref 201] The state of the art in generative AI is “reasoning models” (like OpenAI’s o3), which use a “chain of thought” to recursively reason through harder problems.[ref 202] This chain of thought reveals information about how the model produced a particular result.[ref 203] This information may therefore be probative of an agent’s mental state for legal purposes; it might be analogized to a person making a written explanation of what they were doing and why. So, for example, if the chain of thought reveals that an agent stated that its action would produce a certain result, this would provide good evidence for the proposition that the agent “knew” that action would produce that result. That conclusion, in turn, may support an inference or presumption that the agent “intended” that outcome.[ref 204] For this reason, AI safety researchers are investigating the possibility of detecting unsafe model behavior by monitoring these chains of thought.[ref 205]
New scientific techniques could also form the basis for inferring or imputing mental states. The emerging field of AI interpretability aims to understand both how existing AI systems make decisions and how new AI systems can be built so that their decisions are easily understandable.[ref 206] More precisely, interpretability aims to explain the relationship between the inner mathematical workings of AI systems, which we can easily observe but not necessarily understand, and concepts that humans understand and care about.[ref 207] Leading interpretability researchers hope that interpretability techniques will eventually enable us to prove that models will not “deliberately” engage in certain forms of undesirable behavior.[ref 208] By extension, those same techniques may be able to provide insight into whether a model foresaw a possible consequence of its action (corresponding to our intuitive concept of knowledge) or regarded an anticipated consequence of its actions as a favorable and reason-giving one (corresponding to intent).[ref 209]
In many cases, we think, an inference or imputation of intent will be intuitively obvious. If an AI agent commits fraud by repeatedly attempting to persuade a vulnerable person to transfer some money to the agent’s principal, few (except the philosophically persnickety) will refuse to admit that, in some relevant sense, the agent “intended” to achieve this end; it is difficult even to describe the occurrence without using some such vocabulary ascribing intent to the AI agent. There will also be much less obvious cases, of course. In many such cases, we suspect that a sort of pragmatic eclecticism will be tractable and warranted. Rather than relying on a single approach, factfinders could be permitted to consider the whole bundle of factors that shape an agent’s behavior—such as explicit instructions (from both developers and users), behavioral predispositions, implicitly tolerated behavior,[ref 210] patterns of reasoning, scientific evidence, and incident-specific factors. Factfinders could then be permitted to decide whether they support the conclusion that the AI agent had an objectively unreasonable attitude toward legal constraints and the rights of others.[ref 211] This permissive, blended approach would resemble the “inferential approach” to corporate mens rea advocated by Professor Mihailis Diamantis:
Advocates would present evidence of circumstances surrounding the corporate act, emphasizing some, downplaying others, to weave narratives in which their preferred mental state inferences seem most natural. Adjudicators would have the age-old task of weighing the likelihood of these circumstances, the credibility of the narratives, and, treating the corporation as a holistic agent, inferring the mental state they think most likely.[ref 212]
A final but related point is that, even if there is some insuperable barrier to analyzing whether an AI has the mental state necessary to violate various legal prohibitions, it is plausible that such analysis is unnecessary for many purposes. Suppose that an AI developer is concerned that their AI agent might engage in the misdemeanor deceptive business practice of “mak[ing] a false or misleading written statement for the purpose of obtaining property.”[ref 213] Even if we grant that an AI agent cannot coherently be described as having the relevant mens rea for this crime (here, knowledge or recklessness with respect to the falsity of the statement),[ref 214] the agent can nevertheless satisfy the actus reus (making the false statement).[ref 215] So an AI agent would be law following with respect to this law if it never made false or misleading statements when attempting to obtain someone else’s property. As a matter of public policy, we should care more about whether AI agents are making harmful false statements in commerce than whether they are morally culpable. So, perhaps we can say that an AI agent committed a crime if it committed the actus reus in a situation in which a reasonable person, with access to the same information and cognitive capabilities as the agent, would have expected the harmful consequence to result. To avoid confusion with the actual human-commanding law that requires both mens rea and actus reus, perhaps the law could simply call such behavior “deceptive business practice*.” Or perhaps it would be better to define a new criminal law code for AI agents, under which offenses do not include certain mental state elements or include only objective correlates of human mental state elements.
To reiterate, we are not confident that any one of these approaches to determining AI mental state is the best path forward. But we are more confident that, especially as the fields of AI safety and explainable AI progress, most relevant cases can be handled satisfactorily by one of these techniques, some other technique we have failed to identify, or some combination of techniques. We therefore doubt that legal invocations of mental state will pose an insuperable barrier to analyzing the legality of AI agents’ actions.[ref 216] The task of choosing between these approaches is left to the LFAI research agenda.[ref 217]
III. Why Design AI Agents to Follow the Law?
The preceding part argued that it is coherent for the law to impose legal duties on AI agents. This part motivates the core proposition of LFAI: that the law should, in certain circumstances, require those developing, possessing, deploying, or using[ref 218] AI agents to ensure that those agents are designed to be law following. Part V below will consider how the legal system might implement and enforce these design requirements.
A. Achieving Regulatory Goals Through Design
A core claim of the LFAI proposal is that the law should require AI agents to be designed to rigorously follow the law, at least in some deployment settings. The use of the phrase “designed to” is intentional. Following the law is a behavior. There may be multiple ways to produce that behavior. Since AI agents are digital artifacts, we need not rely solely on incentives to shape their behavior: we can require that AI agents be directly designed to follow the law.
In Code: Version 2.0, Professor Lessig identifies four “constraints” on an actor’s behavior: markets, laws, norms, and architecture.[ref 219] The “architecture” constraint is of particular interest for the regulation of digital activities. Whereas “laws,” in Professor Lessig’s taxonomy, “threaten ex post sanction for the violation of legal rights,”[ref 220] architecture involves modifying the underlying technology’s design to render an undesired outcome more difficult or impossible (or facilitate some desired result)[ref 221] without needing any ex post recourse.[ref 222] Speed bumps are an archetypal architectural constraint in the physical world.[ref 223]
The core insight of Code: Version 2.0 is that cyberspace, as a fully human-designed domain,[ref 224] gives regulators the ability to much more reliably prevent objectionable behavior through the design of digital architecture without the need to resort to ex post liability.[ref 225] While Professor Lessig focuses on the design of cyberspace itself, not the actors using cyberspace, this same insight can be extended to AI agent design. To generalize beyond the cyberspace metaphor for which Professor Lessig’s framework was originally developed, we call this approach “regulation by design” instead of regulation through “architecture.”
Both companies developing AI agents and governments regulating them will have to make many design choices regarding AI agents. Many—perhaps most—of these design choices will concern specific behaviors or outcomes that we want to address. Should AI agents announce themselves as such? How frequently should they “check in” with their human principals? What sort of applications should AI agents be allowed to use?
These are all important questions. But LFAI tackles higher-order questions: How should we ensure that AI agents are regulable in general? How can we avoid creating a new class of actors unbound by law? Returning to Professor Lessig’s four constraints, LFAI proposes that instead of relying solely on ex post legal sanctions, such as liability rules, we should require AI agents to be designed to follow some set of laws: they should be LFAIs.[ref 226] Thus, for whatever sets of legal constraints we wish to impose on the behavior of AI agents,[ref 227] LFAIs will be designed to comply automatically.
B. Theoretical Motivations
1. Law Following in Principal-Agent Relationships
As discussed above,[ref 228] AI agents can be fruitfully analyzed through principal-agent principles. Without advocating for the wholesale legal application of agency law to AI agents, reference to agency law principles can help illuminate the significance and potential of LFAI.[ref 229]
Under hornbook agency principles, an AI agent should generally “act loyally for the principal’s benefit in all matters connected with the agency relationship.”[ref 230] This generally includes a duty to obey instructions from the principal.[ref 231]
Crucially, however, this general duty of obedience is qualified by a higher-order duty to follow the law. Agents only have a duty to obey lawful instructions.[ref 232] Thus, “[a]n agent has no duty to comply with instructions that may subject the agent to criminal, civil, or administrative sanctions or that exceed the legal limits on the principal’s right to direct action taken by the agent.”[ref 233] “[A] contract provision in which an agent promises to perform an unlawful act is unenforceable.”[ref 234] An agent cannot escape personal liability for unlawful acts ordered by their principal.[ref 235]
The basic assumption that underlies these various doctrines is that an agent lacks any independent power to perform unlawful acts.[ref 236] Agency law therefore developed under the assumption that agents maintain an independent obligation to follow the law and, thus, remain accountable for their violations of law. This assumption shaped agency law to prevent principals from unjustly benefiting by externalizing harms incident to the agency relationship.[ref 237] This feature of agency law helps establish a baseline to which we can compare the world of AI agents in the absence of law-following constraints; it also provides a normative justification for requiring AI agents to prioritize legal compliance over obedience to their principals.
2. Law Following in the Design of Artificial Legal Actors
AI agents will of course not be the first artificial actor that humanity has created. Two types of powerful artificial actors—corporations and governments[ref 238]—profoundly impact our lives. When deciding how the law should respond to AI agents, it may make sense to draw lessons from the law’s response to the invention of other artificial legal actors.
A key lesson for AI agents is this: for both corporations and governments, the law does not rely solely on ex post liability to steer the actor’s behavior; it requires the actor to be law following by design, at least to some extent. A disposition toward compliance is built into the very “architecture” of these artificial actors. AI agents may become no less important than corporations and governments in the aggregate, not least because they will be thoroughly integrated into them. Just as the law requires these other actors to be law following by design, it should require AI agents to be LFAIs.
a. Corporations as Law Following by Design
The law requires corporations to be law following by design. One way it does this is by regulating the very legal instruments that bring corporations into existence: corporate charters are only granted for lawful purposes.[ref 239] While an “extreme” remedy,[ref 240] courts can order corporations to be dissolved if they repeatedly engage in illegal conduct.[ref 241] Failure to comply with legally required corporate formalities can also be grounds for involuntarily dissolving a corporate entity[ref 242] or piercing the corporate veil.[ref 243] Thus, while corporations are, like all legal persons, generally obligated to obey the law, states do not only rely on external sanctions to persuade them to do so: they also force corporations to be law following through architectural measures, including dissolving[ref 244] corporations that break the law or refusing to incorporate those that would.
The law also forces corporations to be law following by regulating the human agents that act on their behalf through the agents’ fiduciary duties. Directors who intentionally cause a corporation to violate positive law breach their duty of good faith.[ref 245] Not only are corporate fiduciaries required to follow the law themselves, they are required to monitor for violations of law by other corporate agents.[ref 246] Moreover, human agents that violate certain laws can be disqualified from serving as corporate agents.[ref 247] These sort of “structural” duties and remedies[ref 248] are thus aimed at causing the corporation to follow the law generally and pervasively, rather than merely penalizing violations as they occur.[ref 249] That is entirely sensible, since the state has an obvious interest in preventing the creation of new artificial entities that then go on to disregard its laws, especially since it cannot easily monitor many corporate activities. Whether a powerful and potentially difficult-to-monitor AI agent is generally disposed toward lawfulness will be similarly important. Accordingly, there is a parallel case for requiring the principals of AI agents to demonstrate that their agents will be law following.[ref 250]
b. Governments as Law Following by Design
“Constitutionalism is the idea . . . that government can and should be legally limited in its powers, and that its authority or legitimacy depends on its observing these limitations.”[ref 251] Although we sometimes rely on ex post liability to deter harmful behavior by government actors,[ref 252] the design of the government—through the U.S. Constitution,[ref 253] statutory provisions, and longstanding practice—is the primary safeguard against lawless government action.
Examples abound. The general American constitutional design of separated powers, supported by interbranch checks and balances, plays an important role in preventing the government from exercising arbitrary power, thereby confining the government to its constitutionally delimited role.[ref 254] This system of multiple independent veto points yields concrete protections for personal liberty, such as making it difficult for the government to lawlessly imprison people.[ref 255]
Governments, like corporations, act only through their human agents.[ref 256] As in the corporate case, governmental design forces the branches of government to follow the law in part by imposing law-following duties on the agents through whom it acts. The Constitution imposes a duty on the president to “take Care that the Laws be faithfully executed.”[ref 257] Similar to the corporate context discussed above, soldiers have a duty to disobey some unlawful orders, even from the commander in chief.[ref 258] Civil servants also have a right to refuse to follow unlawful orders, though the exact nature and extent of this right is unclear.[ref 259]
We saw above that, in the corporate case, the law uses disqualification of law-breaking agents to ensure that corporations are law following.[ref 260] The law also uses disqualification to ensure that the government acts only through law-following agents, ranging from the highest levels of government to lower-level bureaucrats and employees. The Constitution empowers Congress to remove and disqualify officers of the United States for “high Crimes and Misdemeanors” through the impeachment process.[ref 261] Each house of Congress may expel its own members for “disorderly Behaviour.”[ref 262] Historically, Congress has exercised this power in cases “involv[ing] either disloyalty to the United States Government, or the violation of a criminal law involving the abuse of one’s official position, such as bribery.”[ref 263] Although there is no blanket rule disqualifying persons with criminal records from federal government jobs,[ref 264] numerous laws disqualify convicted individuals in more specific circumstances.[ref 265] Convicted felons are also generally ineligible to be employed by the Federal Bureau of Investigation[ref 266] or armed forces[ref 267] and usually cannot obtain a security clearance.[ref 268]
These design choices encode a commonsense judgment that those who cannot be trusted to follow the law should not be entrusted to wield the extraordinary power that accompanies certain government jobs, especially positions associated with law enforcement, the military, and the intelligence community. If AI agents come to wield similar power and influence, the case for designing them to obey the law is equally compelling.
3. The Holmesian Bad Man and the Internal Point of View
Our distinction between AI henchmen and LFAIs mirrors a distinction in jurisprudence about possible attitudes toward legal obligations.[ref 269] An AI henchman treats legal obligations much as the “bad man” does in Justice Oliver Wendell Holmes Jr.’s classic The Path of the Law:
If you want to know the law and nothing else you must look at it as a bad man, who cares only for the material consequences which such knowledge enables him to predict, not as a good one, who finds his reasons for conduct, whether inside the law or outside of it, in the vaguer sanctions of conscience.[ref 270]
That is, under some interpretations,[ref 271] Justice Holmes’ bad man treats the law merely as a set of incentives within which he pursues his own self-interest.[ref 272] Like the bad man, the primary reason an AI henchman would have to follow the law is simply that, if it is caught breaking the law, its principal might face negative consequences that outweigh the benefits gained from the lawbreaking.[ref 273] Like the bad man,[ref 274] therefore, if the AI henchman predicts that the expected costs of violating the law are greater than the expected benefits, it will obey. Otherwise, it will not.
Fortunately, the bad man is not the only possible model for AI agents’ attitudes toward the law. One alternative to the bad man view of the law is Professor H.L.A. Hart’s “internal point of view.”[ref 275] “The internal point of view is the practical attitude of rule acceptance—it does not imply that people who accept the rules accept their moral legitimacy, only that they are disposed to guide and evaluate conduct in accordance with the rules.”[ref 276] Whether AIs can have the capacity to truly adopt the internal point of view is, of course, contested.[ref 277] But regardless of their mental state (if any), AI agents can be designed to act like someone who thinks that “the law is not simply sanction-threatening, -directing, or -predicting, but rather obligation-imposing”[ref 278] and is thus disposed to “act[] according to the dictates of the [law].”[ref 279] An AI agent can be designed to be more rigorously law-following than the bad man.[ref 280]
Real life is of course filled with people who are “bad” or highly imperfect. But bad AI agents are not similarly inevitable. AI agents are human-designed artifacts. It is open to us to design their behavioral dispositions to suit our policy goals, and to refuse to deploy agents that do not meet those goals.
C. Concrete Benefits
1. Law-Following AI Prevents Abuses of Government Power
As we have discussed,[ref 281] the law makes the government follow the law (and thus prevents abuses of government power) in part by compelling government agents to follow the law. If the government comes to rely heavily on AI agents for cognitive labor, then the law should also require those agents to follow the law.
Depending on their assigned “roles,” government AI agents could wield significant power. They may have authority to initiate legal processes against individuals (including subpoenas, warrants, indictments, and civil actions), access sensitive governmental information (including tax records and intelligence), hack into protected computer systems, determine eligibility for government benefits, operate remote-controlled vehicles like military drones,[ref 282] and even issue commands to human soldiers or law enforcement officials.
These powers present significant opportunities for abuse, which is why preventing lawless government action was a motivation for the American Revolution,[ref 283] a primary goal of the Constitution, and a foundational American political value. We must therefore carefully examine whether existing safeguards designed to constrain human government agents would effectively limit AI agents in the absence of the law-following design constraints. While our analysis here is necessarily incomplete, we think it provides some reason for doubting the adequacy of existing safeguards in the world of AI agents.
When a human government agent, acting in their official capacity, violates an individual’s rights, they can face a variety of ex post consequences. If the violation is criminal, they could face severe penalties.[ref 284] This “threat of criminal sanction for subordinates [i]s a very powerful check on executive branch officials.”[ref 285] The threat of civil suits seeking damages, such as through a § 1983[ref 286] or Bivens action,[ref 287] might also deter them, though various immunities and indemnities will often protect them,[ref 288] especially if they are a federal officer.[ref 289]
These checks will not exist in the case of AI henchmen. In the absence of law-following constraints, an AI henchman’s primary reason to obey the law will be its desire to keep its principal out of trouble.[ref 290] The henchman will thus lack one of the most powerful constraints on lawless behavior in humans: fear of personal ex post liability.
Most of us would rightfully be terrified of a government staffed by agents whose only concern was whether their bosses would suffer negative consequences as a result of their actions—a government staffed by Holmesian bad men loyal only to their principals.[ref 291] A basic premise of American constitutionalism,[ref 292] and rule-of-law principles more generally,[ref 293] is that government officials act legitimately only when they act pursuant to powers the people granted to them through law and obey the constraints attached to those powers. Treating law as a mere incentive system is repugnant to the proper role of government agents:[ref 294] being a “servant” of the people[ref 295] “faithfully discharg[ing] the duties of [one’s] office.”[ref 296]
This is not just a matter of high-minded political and constitutional theory. An elected head of state aspiring to become a dictator would need the cooperation of the sources of hard power in society—military, police, other security forces, and government bureaucracy—to seize power. At present, however, these organs of government are staffed by individuals, who may choose not to go along with the aspiring dictator’s plot.[ref 297] Furthermore, in an economy dependent on diffuse economic activity, resistance by individual workers could reduce the economic upsides of a coup.[ref 298] This reliance on a diverse and imperfectly loyal human workforce, both within and outside of government, is a significant safeguard against tyranny.[ref 299] However, replacement of human workers with loyal AI henchmen would seriously weaken this safeguard, possibly easing the aspiring tyrant’s path to power.[ref 300]
Nor is the importance of LFAIs limited to AI agents acting directly at the request of high-level officials. It extends to the vast array of lower-level state and federal officials who wield enormous power over ordinary citizens, including particularly powerless ones. Take prisons, which “can often seem like lawless spaces, sites of astonishing brutality where legal rules are irrelevant.”[ref 301] Prison law arguably constrains abuse by officials far less than it should. Nevertheless, “prisons are intensely legal institutions,” and “people inside prisons have repeatedly emphasized that legal rules have significant, concrete effects on their lives.”[ref 302] Even imperfect enforcement of the legal constraints on prison officials can have demonstrable effects.[ref 303] However bad the existing situation may be, diluting or gutting the efficacy of these constraints threatens to make the situation dramatically worse.
The substitution of AI agents for (certain) prison officials could have precisely this effect. Here is just one example. The Eighth Amendment forbids prison officials from withholding medical treatment from prisoners in a manner that is deliberately indifferent to their serious medical needs.[ref 304] Suppose that a state prisoner needs to take a dose of medicine each day for a month or their eyesight will be permanently damaged. The prisoner says something disrespectful to a guard. The warden, hoping to make an example of the prisoner, fabricates a note from the prison physician directing the prison pharmacist to withhold further doses of the medicine. The prisoner is subsequently denied the medicine. They try to reach their lawyer to get a temporary restraining order, but the lawyer cannot return their call until the next day. As a result, the prisoner’s eyesight is permanently damaged.
Let us assume that the state has strong state-level sovereign immunity under its own laws, meaning that the prisoner cannot sue the state directly.[ref 305] Under the status quo, the prisoner can still sue the warden for damages under 42 U.S.C. § 1983 for violating their clearly established constitutional right.[ref 306] Given the widespread prevalence of official indemnification agreements at the state level,[ref 307] the state will likely indemnify the warden, even though the state itself cannot be sued for damages under § 1983[ref 308] or its own laws. The prisoner is therefore likely to receive monetary damages.
But now replace the human warden with an AI agent charged with administering the prison by issuing orders directly to prison personnel through some digital interface. If this “AI warden” did the same thing, the prisoner would not have direct redress against it, since it is not a “person” under § 1983[ref 309] (or, indeed, any law). Nor will the prisoner have indirect recourse against the state by way of an indemnification agreement because there is no underlying tort liability for the state to indemnify. Nor will the prisoner have redress against the medical personnel, since the AI warden deceived them into withholding treatment.[ref 310] And, as we have already assumed, the state itself has sovereign immunity. Thus, the prisoner will find themself without any avenue of redress for the wrong they have suffered, and the introduction of an artificial agent in the place of a human official made all the difference.
What is the right response to these problems? Many responses may be called for, but one of them is to ensure that only law-following AI agents can serve in such a role. As previously discussed, the law disqualifies certain lawbreakers from many government jobs. Similarly, we believe, the law should disqualify AI agents that are not demonstrably rigorously law following from certain government roles. We discuss how this disqualification might be enforced, more concretely, in Part V.
There is, however, another possible response to these challenges: perhaps we should “just say no” and prohibit governments from using AI agents at all or at least severely curtail their use.[ref 311] We do not take a strong position on when this would be the correct approach, all things considered. At a minimum, however, we note a few reasons for skepticism of such a restrictive approach.
The first is banal: if AI agents can perform computer-based tasks well, then their adoption by the government could also deliver considerable benefits to citizens.[ref 312] Reducing the efficiency of government administration for the sake of preventing tyranny and abuse may be worthwhile in some cases and is indeed the logic of the individual rights protections of the Constitution.[ref 313] But tailoring a safeguard to allow for efficient government administration, is, all else being equal, preferable to a blunter, more restrictive safeguard. LFAI may offer such a tailored safeguard.
The second reason for skepticism is that adoption of AI agents by governments may become more important as AI technology advances. Some of the most promising AI safety proposals involve using trusted AI systems to monitor untrusted ones.[ref 314] The central reason is this: as AI systems become more capable, unassisted humans will not be able to reliably evaluate whether the AIs’ actions are desirable.[ref 315] Assistance from trusted AI systems could thus be the primary way to scale humans’ ability to oversee untrusted AI systems. If the government is to oversee the behavior of new and untrusted private-sector AI systems, it might be necessary to do so using AI agents.
Even if the government does not need to rely on AI agents to administer AI safety regulation (for example, because such AI overseers are employed by private companies, not the government), the government will likely need to employ AI agents to help it keep up with competitive pressures. Should the federal government hesitate to adopt AI agents to increase its efficiency, foreign competitors might show no such qualms. As a result, the federal government might then feel little choice but to likewise adopt AI agents.
In the face of these competing demands, LFAI offers a plausible path to enable the adoption of AI agents in governmental domains with a high potential for abuse (e.g., the military, intelligence, law enforcement, prison administration) while safeguarding life, liberty, and the rule of law. LFAI can also transform the binary question of whether to adopt AI agents into the more multidimensional question of which laws should constrain them.[ref 316] This should allow for more nuanced policymaking, grounded in the existing legal duties of government agents.
2. Law-Following AI Enables Scalable Enforcement of Public Law
AI agents could cause a wide variety of harms. The state promulgates and enforces public law prohibitions—both civil and criminal—to prevent and remedy many of these harms. If the state cannot safely assume that AI agents will reliably follow these prohibitions, the state might need to increase the resources dedicated to law enforcement.
LFAI offers a way out of this bind. Insofar as AI agents are reliably law following, the state can trust that significantly less law enforcement is needed.[ref 317] This dynamic would also have broader beneficial implications for the structure and functioning of government. “If men were angels, no government would be necessary.”[ref 318] LFAIs would not be angels,[ref 319] but they would be a bit more angelic than many humans. Thus, as a corollary of Publius’s insight, we may need less government to oversee LFAIs’ behavior than we would need for a human population of equivalent size. State resources that would otherwise be spent on investigating and enforcing the laws against AI agents could instead be directed to other problems or refunded to the citizenry.
LFAI would also curtail some of the undesirable side effects and opportunities for abuse inherent in law enforcement. Law enforcement efforts often involve some intrusion into the private affairs and personal freedoms of citizens.[ref 320] If the government could be more confident that AI agents under private control were behaving lawfully, it would have less cause to surveil or investigate their behavior, thereby imposing fewer[ref 321] burdens on their principals’ privacy. Reducing the occasion for investigations and searches would also create fewer opportunities for abuse of private information.[ref 322] In this way, ensuring reliably law-following AI might significantly mitigate the frequency and severity of law enforcement’s intrusions on citizens’ privacy and liberty.
IV. Law-Following AI as AI Alignment
The field of AI alignment aims to ensure that powerful, general-purpose AI agents behave in accordance with some set of normative constraints.[ref 323] AI systems that do not behave in accordance with such constraints are said to be “misaligned” or “unaligned.” Since the law is a set of normative constraints, the field of AI alignment is highly relevant to LFAI.[ref 324]
The most basic set of normative constraints to which an AI could be aligned is the “informally specified”[ref 325] intent of its principal.[ref 326] This is called “intent-alignment.”[ref 327] Since individuals’ intentions are a mix of morally good and bad to varying degrees, some alignment work also aims to ensure that AI systems behave in accordance with moral constraints, regardless of the intentions of the principal.[ref 328] This is called “value-alignment.”[ref 329]
AI alignment work is valuable because, as shown by theoretical arguments[ref 330] and empirical observations,[ref 331] it is difficult to design AI systems that reliably obey any particular set of constraints provided by humans.[ref 332] In other words, nobody knows how to ensure that AI systems are either intent-aligned or value-aligned,[ref 333] especially for smarter-than-human systems.[ref 334] This is the “Alignment Problem.”[ref 335] The Alignment Problem is especially worrying for AI systems that are agentic and goal-directed,[ref 336] as such systems may try to evade human oversight and controls that could frustrate pursuit of those goals, such as by deceiving their developers,[ref 337] accumulating power and resources[ref 338] (including by making themselves smarter),[ref 339] and ultimately resisting efforts to correct their behavior or halt further actions.[ref 340]
There is a sizable literature arguing that these dynamics imply that misaligned AI agents pose a nontrivial risk to the continued survival of humanity.[ref 341] The case for LFAI, however, in no way depends on the correctness of these concerns: the specter of widespread lawless AI action should be sufficient on its own to motivate LFAI. Nevertheless, the alignment literature produces several valuable insights for the pursuit of LFAI.
A. AI Agents Will Not Follow the Law by Default
The alignment literature suggests that there is a significant risk that AI agents will not be law following by default. This is a straightforward implication of the Alignment Problem. To see how, imagine a morally upright principal who intends for his AI agent to rigorously follow the law. If the AI agent was intent-aligned, the agent would therefore follow the law. But the fact that intent-alignment is an unsolved problem implies that there is a significant chance that that agent would not be aligned with the principal’s intentions and would therefore violate the law. Put differently, unaligned AIs may not be controllable,[ref 342] and uncontrollable AIs may break the law. Thus, so long as intent-alignment remains an unsolved technical problem, there will be a significant risk that AI agents will be prone to lawbreaking behavior.
To be clear, the main reason that there is a significant risk AI agents will not be law following by default is not that people will not try to align AI agents to the law (although that is also a risk).[ref 343] Rather, the main risk is that current state-of-the-art alignment techniques do not provide a strong guarantee that advanced AI agents will be aligned, even when they are trained with those techniques. There is a clear empirical basis for this claim, which is that those alignment techniques frequently fail in current frontier models.[ref 344] There are also theoretical limitations to existing techniques for smarter-than-human systems.[ref 345]
A related implication of the alignment literature is that even intent-aligned AI agents may not follow the law by default. Again, we can see this by hypothesizing an intent-aligned AI agent and a human principal who wants the AI agent to act as their henchman. Since an intent-aligned AI agent follows the intent of its principal, this intent-aligned agent would act as a henchman and thus act lawlessly when doing so serves the principal’s interests.[ref 346] In typical alignment language, intent-alignment still leaves open the possibility that principals will misuse their intent-aligned AI.[ref 347]
None of this is to imply that intent-alignment is undesirable. Solving intent-alignment is the primary focus of the alignment research community[ref 348] because it would ensure that AI agents remain controllable by human principals.[ref 349] Intent-alignment is also generally assumed to be easier than value-alignment.[ref 350] And if principals want their AI agents to follow the law, or behave ethically more generally, then intent-alignment will produce law-following or ethical behavior. But in a world where principals range from angels to devils, alignment researchers acknowledge that intent-alignment alone is insufficient to guarantee that AI agents act lawfully or produce good effects in the world.[ref 351] This brings us to the next important set of implications from the alignment literature: law-alignment.
B. Law-Alignment Is More Legitimate Than Value-Alignment
LFAIs are generally intent-aligned—they are still loyal to their principals—but are also subject to a side constraint that they will follow the law while advancing the interests of their principals. Extending the typical alignment terminology, we can call this side constraint “law-alignment.”[ref 352]
But the law is not the only side constraint that can be imposed on intent-aligned AIs. As alluded to above, another possible model is value-alignment. Value-aligned AI agents act in accordance with the wishes of their principals but are subject to ethical constraints, usually imposed by the model developer.
However, value-alignment can be controversial when it causes AI models to override the lawful requests of users. Perhaps the most well-known example of this is the controversy around Google’s Gemini image-generation AI in early 2024. In an attempt to increase the diversity in outputted pictures,[ref 353] Gemini ended up failing in clear ways, such as portraying “1943 German soldiers” as racially diverse or refusing to generate pictures of a “white couple” while doing so for couples of other races.[ref 354]
This incident led to widespread concern that the values exhibited by generative AI products were biased toward the predominantly liberal views of these companies’ employees.[ref 355] This concern has been vindicated by empirical research consistently finding that the espoused political views of these AIs indeed most closely resemble those of the center left.[ref 356] Critics from further left have also frequently raised similar concerns about demographic and ideological biases in AI systems.[ref 357]
Some critics concluded from the Gemini incident that alignment work writ large has become a Trojan horse for covertly pushing the future of AI in a leftward direction.[ref 358] Those who disagree with progressive political values will naturally find this concerning, given the importance that AI might have in the future of human communication[ref 359] and the highly centralized nature of large-scale AI development and deployment.[ref 360]
In a pluralistic society, it is inevitable and understandable that competing factions will be critical when a sociotechnical system reflects the values of only one faction. But alignment, as such, is not the right target of such criticisms. Intent-alignment is value-neutral, concerning itself only with the extent to which an AI agent obeys its principal.[ref 361] Reassuringly for those concerned with ideological bias in AI systems, intent-alignment is also the primary focus of the alignment community, since solving intent-alignment is necessary to reliably control AI systems at all.[ref 362] A large majority of Americans from all political backgrounds agree that AI technologies need oversight.[ref 363] And overseeing unaligned systems is much more difficult than overseeing aligned ones. Indeed, even the critics of alignment work tend to assume—contrary to the views of many alignment researchers—that AI agents will be easy to control[ref 364] and presumably view this result as desirable.
Furthermore, some amount of alignment is also necessary to make useful AI products and services. Consumers, reasonably, want to use AI technologies that they can reliably control. Today’s leading chatbots—like Claude and ChatGPT—are only helpful to users due to the application of alignment techniques like RLHF[ref 365] and Constitutional AI.[ref 366] AI developers also use alignment techniques to instill uncontroversial (and user-friendly) behaviors, such as honesty, into their AI systems.[ref 367] AI companies are also already using alignment techniques to prevent their AI systems from taking actions that could cause them or their customers to incur unnecessary legal liability.[ref 368] In short, some degree of alignment work is necessary to make AI products useful in the first place.[ref 369] To adopt a blanket stance against alignment because of the Gemini incident is not only unjustified[ref 370] but also likely to undermine American leadership in AI.
Nevertheless, it is reasonable for critics to worry about and contest the frameworks by which potentially controversial values are instilled into AI systems. AI developers are indeed a “very narrow slice of the global population.”[ref 371] This is something that should give anyone, regardless of political persuasion, pause.[ref 372] But intent-alignment is not enough, either: it is inadequate to prevent a wide variety of harms that the state has an interest in preventing.[ref 373] So, we need a form of alignment that is more normatively constraining than intent-alignment alone—but more legitimate than alignment to values that AI developers choose themselves.
Law-alignment fits these criteria.[ref 374] While the moral legitimacy of the law is not perfect, in a republic it nevertheless has the greatest legitimacy of any single source or repository of values.[ref 375] Indeed, “the framers [of the U.S. Constitution] insisted on a legislature composed of different bodies subject to different electorates as a means of ensuring that any new law would have to secure the approval of a supermajority of the people’s representatives,”[ref 376] thus ensuring that new laws are “the product of widespread social consensus.”[ref 377] In our constitutional system of government, laws are also subject to checks and balances that protect fundamental rights and liberties, such as judicial review for constitutionality and interpretation by an independent judiciary.
Aligning to law also has procedural virtues over value-alignment. First, there is widespread agreement on the authoritative sources of law (e.g., the Constitution, statutes, regulations, case law), much more so than for ethics. Relatedly, legal rules tend to be expressed much more clearly than ethical maxims. Although there is considerable disagreement about the content of law and the proper forms of legal reasoning, it is nevertheless much easier (and less controversial) to evaluate the validity of legal propositions and arguments than to assess the quality or correctness of ethical reasoning.[ref 378] Moreover, when there is disagreement or ambiguity, the law contains established processes for authoritatively resolving disputes over the applicability and meaning of laws.[ref 379] Ethics contains no such system.
We therefore suggest that law-alignment, not value-alignment, should be the primary focus when something beyond intent-alignment is needed.[ref 380] Our claim, to be clear, is not that law-alignment alone will always prove satisfactory, that it should be the sole constraint on AI systems beyond intent-alignment, or that AI agents should not engage in moral reasoning of their own.[ref 381] Rather, we simply argue that more practical and theoretical alignment research should be aimed at building AI systems aligned to law.
V. Implementing and Enforcing Law-Following AI
We have argued that AI agents should be designed to follow the law. We now turn to the question of how public policy can support this goal. Our investigation here is necessarily preliminary; our aim is principally to spur future research.
A. Possible Duties Across the AI Agent Life Cycle
As an initial matter, we note that a duty to ensure that AI agents are law following could be imposed at several stages of the AI life cycle.[ref 382] The law might impose duties on persons who are
- developing AI agents,
- possessing[ref 383] AI agents,
- deploying[ref 384] AI agents, or
- using AI agents.
After deciding which of these activities ought to be regulated, policymakers must then decide what persons engaging in those activities are obligated to do. While the possibilities are too varied to exhaust here, some basic options might include commands like the following:
- “Any person developing an AI agent has a duty to take reasonable care to ensure that such AI agent is law following.”
- “It is a violation to knowingly possess an AI agent that is not law following, except under the following circumstances: . . .”
- “Any person who deploys an AI agent is strictly liable if such AI agent is not law following.”
- “A person who knowingly uses an AI agent that is not law following is liable.”
Basic duties of this sort would comprise the foundational building blocks of LFAI policy. Policymakers must then choose whether to enforce these obligations ex post (that is, after an AI henchman takes an illegal action)[ref 385] or ex ante. These two choices are interrelated: as we will explore below, it may make more sense to impose ex ante requirements for some activities and ex post liability for others. For example, ex ante regulation might make more sense for AI developers than civilian AI users because the former are far more concentrated and can absorb ex ante compliance costs more easily.[ref 386] And of course, ex ante regulation and ex post regulation are not mutually exclusive:[ref 387] driving, for example, is regulated by a combination of ex ante policies (e.g., licensing requirements) and ex post policies (e.g., tort liability).
B. Ex Post Policies
We begin our discussion with ex post policies. Many scholars believe that ex post policies are generally preferable to ex ante policies.[ref 388] While we think that ex post policies could have an important role to play in implementing LFAI, we also suspect that they will be inadequate in certain contexts.
Enforcing duties through ex post liability rules is familiar in both common law[ref 389] and regulation.[ref 390] In the LFAI context, ex post policies would impose liability on an actor after an AI henchman controlled by that actor violates an applicable legal duty. More and less aggressive ex post approaches are conceivable. On the less aggressive end of the spectrum, development, possession, deployment, or use of an AI henchman might be considered a per se breach of the tort duty of reasonable care, rendering the human actor liable for resulting injuries.[ref 391] To some extent, this may already be the case under existing tort law.[ref 392] The law might also consider extending an AI developer or deployer’s negligence liability to harms that would not typically be compensable under traditional tort principles (because, for example, they would count as pure economic loss)[ref 393] if those harms are produced by their AI agents acting in criminal or otherwise unlawful ways.[ref 394] A legislature might also impose tort liability on the developers of AI agents if those AI agents (1) are not law following, (2) violate an applicable legal duty, and (3) thereby cause harm.[ref 395]
Other innovations may also be warranted. Several scholars have argued, for example, that the principal of an AI agent should sometimes be held strictly liable for the “torts” of that agent under a respondeat superior theory.[ref 396] In some cases, such as when a developer has recklessly failed to ensure that its AI agent is law following by design, punitive damages might be appropriate as well. Moving beyond tort law, in some cases it may make sense to impose civil sanctions[ref 397] when an AI henchman violates an applicable legal duty, even if no harm results.
In order to sufficiently disincentivize the deployment of lawless AI agents in high-stakes contexts, a legislature might also vary applicable immunity rules. For example, Congress could create a distinct cause of action against the federal government for individuals harmed by AI henchmen under the control of the federal government, taking care to remove barriers that various immunity rules pose to analogous suits against human agents.[ref 398]
These and other imaginable ex post policies are important arrows in the regulatory quiver, and we suspect they will have an important role to play in advancing LFAI. Nevertheless, we would resist any suggestion that ex post sanctions are sufficient to deal with the specter of lawless AI agents.
Our reasons are multiple. In many contexts, detecting lawless behavior once an AI agent has been deployed will be difficult or costly—especially as these systems become more sophisticated and more capable of deceptive behavior.[ref 399] Proving causation may also be difficult.[ref 400] In the case of corporate actors, meanwhile, the efficacy of such sanctions may be seriously blunted by judgment-proofing and similar phenomena.[ref 401] And, most importantly for our purposes, various immunities and indemnities make tort suits against the government or its officials a weak incentive.[ref 402] These considerations suggest that it would be unwise to rely on ex post policies as our principal means for ensuring that AI agents follow the law when the risks from lawless action are particularly high.
C. Ex Ante Policies
Accordingly, we propose that, in some high-stakes contexts, the law should take a more proactive approach by preventing the deployment of AI henchmen ab initio. This would likely require establishing a technical means for evaluating whether an AI agent is sufficiently law following,[ref 403] then requiring that any agents be evaluated for compliance prior to deployment. Permission to deploy the agent would then be conditional on achieving some minimal score during that evaluation process.[ref 404]
We are most enthusiastic about imposing such requirements prior to the deployment of AI agents in government roles where lawlessness would pose a substantial risk to life, liberty, and the rule of law. We have discussed several such contexts already,[ref 405] but the exact range of contexts is worth carefully considering.
Ex ante strategies could also be used in the private sector, of course. One often-discussed approach is an FDA-like approval regulation regime wherein private AI developers are required to prove, to the satisfaction of some regulator, that their AI agents are safe prior to their deployment.[ref 406] The pro tanto case for requiring private actors to demonstrate that their AI agents are disposed to follow some basic set of laws is clear: the state has an interest in ensuring that its most fundamental laws are obeyed. But in a world of increasingly sophisticated artificial agents, approval regulation could—if not properly designed and sufficiently tailored—also constitute a serious incursion on innovation[ref 407] and personal liberty.[ref 408] If AI agents will be as powerful as we suspect, strictly limiting their possession could create risks of its own.[ref 409]
Accordingly, it is also worth considering ex ante regulations on private AI developers or deployers that stop short of full approval regulation. For example, the law could require the developers of AI agents to, at a minimum, disclose information[ref 410] about the law-following propensities of their systems, such as which laws (if any) their agents are instructed to follow[ref 411] and any evaluations of how reliably their agents follow those laws.[ref 412] Similarly, the law could require developers to formulate and assess risk-management frameworks that specify the precautionary measures they plan to undertake to ensure that any agent they develop and deploy is sufficiently law following.[ref 413]
Overall, we are uncertain about what kinds of ex ante requirements are warranted, all things considered, in the case of private actors. To a large extent, the issue cannot be intelligently addressed without more specific proposals. Formulating such proposals is therefore an urgent task for the LFAI research agenda, even if it is not, in our view, as urgent as formulating concrete regulations for AI agents acting under color of law.
D. Other Strategies
The law does not police undesirable behavior solely by imposing sanctions. It also specifies mechanisms for nullifying the presumptive legal effect of actions that violate the law or are normatively objectionable. In private law, for example, a contract is voidable by a party if that party’s assent was “induced by either a fraudulent or a material misrepresentation by the other party upon which the [party wa]s justified in relying.”[ref 414] Nullification rules exist in public law, too. One obvious example is the ability of the judiciary to nullify laws that violate the federal Constitution.[ref 415] Or, to take another familiar example, courts applying the Administrative Procedure Act “hold unlawful and set aside” agency actions that are “arbitrary, capricious, an abuse of direction, or otherwise not in accordance with law.”[ref 416]
Nullification rules may provide a promising legal strategy for policing behavior by AI agents that is unlawful or normatively objectionable. Thus, in private law, if an AI henchman induces a human counterparty to enter into a disadvantageous contract, the resulting contractual obligation could be voidable by the human. In public law, regulatory directives issued by (or substantially traceable to) AI henchmen could be “h[e]ld unlawful and set aside” as “not in accordance with law.”[ref 417]
Such prophylactic nullification rules are one sort of indirect legal mechanism for enforcing the duty to deploy law-following AIs. Indirect technical mechanisms are well worth considering, too. For example, the government could deploy AI agents that refuse to coordinate or transact with other AI agents unless those counterparty agents are verifiably law following (for example, by virtue of having “agent IDs”[ref 418] that attest to a minimal standard of performance on law-following benchmarks).
Similarly, the government could enforce LFAI by regulating the hardware on which AI agents will typically operate. Frontier AI systems “run” on specialized AI chips,[ref 419] which are typically aggregated in large data centers.[ref 420] Collectively, these are referred to as “AI hardware” or simply “compute.”[ref 421] Compared to other inputs to AI development and deployment, AI hardware is particularly governable, given its detectability, excludability, quantifiability, and concentrated supply chain.[ref 422] Accordingly, a number of AI governance proposals advocate for imposing requirements on those making and operating AI hardware in order to regulate the behavior of the AI systems developed and deployed on that hardware.[ref 423]
One class of such proposals is “‘on-chip mechanisms’: secure physical mechanisms built directly into chips or associated hardware that could provide a platform for adaptive governance” of AI systems developed or deployed on those chips.[ref 424] On-chip mechanisms can prevent chips from performing unauthorized computations. One example is iPhone hardware that “enable[s] Apple to exercise editorial control over which specific apps can be installed” on the phone.[ref 425] Analogously, perhaps we could design AI chips that would not support AI agents unless those agents are certified as law following by some private or governmental certifying body. This could then be combined with other strategies to enforce LFAI mandates: for example, Congress could require that the government only run AI agents on such chips.
Unsurprisingly, designing these sorts of enforcement strategies is as much a task for computer scientists as it is for lawyers. In the decades to come, we suspect that such interdisciplinary legal scholarship will become increasingly important.
VI. A Research Agenda for Law-Following AI
We have laid out the case for LFAI: the requirement that AI agents be designed to rigorously follow some set of laws. We hope that our readers find it compelling. However, our goal with this Article is not just to proffer a compelling idea. If we are correct about the impending risks of lawless AI agents, we may soon need to translate the ideas in this Article into concrete and viable policy proposals.
Given the profound changes that widespread deployment of AI agents will bring, we are under no illusions about our ability to design perfect public policy in advance. Rather, our goal is to enable the design of “minimally viable LFAI policy”:[ref 426] a policy or set of policies that will prevent some of the worst-case outcomes from lawless AI agents without completely paralyzing the ability of regulated actors to experiment with AI agents. This minimally viable LFAI policy will surely be flawed in many ways, but with many of the worst-case outcomes prevented, we will hopefully have time as a society to patch remaining issues through the normal judicial and legislative means.
To that end, in this part, we briefly identify some questions that would need to be answered to design minimally viable LFAI policies.
1. How should “AI agent” be defined?
Our definition of “full AI agent”—an AI system “that can do anything a human can do in front of a computer”[ref 427]—is almost certainly too demanding for legal purposes, since an AI agent that can do most but not all computer-based tasks that a human can do would likely still raise most of the issues that LFAI is supposed to address. At the same time, because a wide range of existing AI systems can be regarded as somewhat agentic,[ref 428] a broad definition of “AI agent” could render relevant regulatory schemes substantially overinclusive. Different definitions are therefore necessary for legal purposes.[ref 429]
2. Which laws should an LFAI be required to follow?
Obedience to some laws is much more important than obedience to other laws. It is much more important that AI agents refrain from murder and (if acting under color of law) follow the Constitution than that they refrain from jaywalking. Indeed, requiring LFAIs to obey literally every law may very well be overly burdensome.[ref 430] In addition, we will likely need new laws to regulate the behavior of AI agents over time.
3. When an applicable law has a mental state element, how can we adjudicate whether an AI agent violated that law?
We discuss this question above in Part II.B. It is related to the previous question, for there may be conceptual or administrative difficulties in applying certain kinds of mental state requirements to AI agents. For example, in certain contexts, it may be more difficult to determine whether an AI agent was “negligent” than to determine whether it had a relevant “intent.”
4. How should an LFAI decide whether a contemplated action is likely to violate the law?
An LFAI refrains from taking actions that it believes would violate one of the laws that it is required to follow. But of course, it is not always clear what the law requires. Furthermore, we need some way to tell whether an AI agent is making a good faith effort to follow a reasonable interpretation of the law rather than merely offering a defense or rationalization. How, then, should an LFAI reason about what its legal obligations are?
Perhaps it should rely on its own considered judgment, based on its first-order reasoning about the substance of applicable legal norms. But in certain circumstances, at least, an LFAI’s appraisal of the relevant materials might lead it to radically unorthodox legal conclusions—and a ready disposition to act on such conclusions might significantly threaten the stability of the legal order. In other cases, an LFAI might conclude that it is dealing with a case in which the law is not only “hard” to discern but genuinely indeterminate.[ref 431]
A more intuitively appealing option might require an LFAI to act in accordance with its prediction of how a court would likely decide.[ref 432] This approach has the benefit of tying an LFAI’s legal decision-making to an existing human source of interpretative authority. Courts provide authoritative resolutions to legal disputes when the law is controversial or indeterminate. And in our legal culture, it is widely (if not universally) accepted that “[i]t is emphatically the province and duty of the judicial department to say what the law is,”[ref 433] such that judicial interpretations of the law are entitled to special solicitude by conscientious participants in legal practice, even when they are not bound by a court judgment.[ref 434]
However, a predictive approach would have important practical limitations.[ref 435] Perhaps the most important is the existence of many legal rules that bind the executive branch but are nevertheless “unlikely ever to come before a court in justiciable form.”[ref 436] It would seem difficult for an LFAI to reason about such questions using the prediction theory of law.
Even for those questions that could be decided by a court, using the prediction theory of law raises other important questions. For example, what is the AI agent allowed to assume about its own ability to influence the adjudication of legal questions? We would not want it to be able to consider that it could bribe or intimidate judges or jurors, that it could illegally hide evidence from the court, that it could commit perjury, or that it could persuade the president to issue it a pardon.[ref 437] These may be means of swaying the outcome of a case, but they do not seem to bear on whether the conduct would actually be legal.
The issues here are difficult, but perhaps not insurmountable. After all, there are other contexts in which something like these issues arise. Consider federal courts sitting in diversity applying state substantive law. When state court decisions provide inconclusive evidence as to the correct answer under state law, federal courts will make an “Erie guess” about how the state’s highest court would rule on the issue.[ref 438] It would clearly be inappropriate for such courts to make an “Erie guess” for reasons like “Justice X in the State Supreme Court, who’s the swing justice, is easily bribed.”[ref 439] If an LFAI’s decision-making should sometimes involve “predicting” how an appropriate court would rule, its predictions should be similarly constrained.
5. In what contexts should the law require that AI agents be law following?
Should all principals be prohibited from employing non-law-following AI agents? Or should such prohibitions be limited to specific principals, such as government actors?[ref 440] Or, perhaps, should they be limited only to government actors performing particularly sensitive government functions?[ref 441] In the other direction, should it be illegal to even develop or possess AI henchmen? We discussed various options in Part V above.
6. How should a requirement that AI agents be law following be enforced?
We discussed various options in Part V. As noted there, we think that reliance on ex post enforcement alone would be unwise, at least in the case of AI agents performing particularly sensitive government functions.
7. How rigorously should an LFAI follow the law?
That is, when should an AI agent be capable of taking actions that it predicts may be unlawful? The answer is probably not “never,” at least with respect to some laws. We generally do not expect perfect compliance with every law,[ref 442] especially (but not only) because it can be difficult to predict how a law will apply to a given fact pattern. Furthermore, some amount of disobedience is likely necessary for the evolution of legal systems.[ref 443]
8. Would requiring AI agents controlled by the executive branch to be law following impermissibly intrude on the president’s authority to interpret the law for the executive branch?
The president has the authority to promulgate interpretations of law that are binding on the executive branch (though that power is usually delegated to the attorney general and then further delegated to the U.S. Department of Justice’s Office of Legal Counsel).[ref 444] Would that authority be incompatible with a law requiring the executive branch to deploy LFAIs that would, in certain circumstances, refuse to follow an interpretation of the law promulgated by the president?
9. How can we design LFAIs and surrounding governance systems to avoid excessive concentration of power?
For example, imagine that a single district court judge could change the interpretation of law as against all LFAIs. As the stakes of AI-agent action rise, so will the pressure on the judiciary to wield its power to shape the behavior of LFAIs. Even if all judges continue to operate in good faith and are well-insulated from illegal or inappropriate attempts to bias their rulings, such a system would amplify any idiosyncratic legal philosophies of individual judges and may promote mistaken rulings, causing greater harm than a more decentralized system.
As an example of how such problems might be avoided, any disputes about the law governing LFAIs should be resolved in the first instance by a panel of district court judges randomly chosen from around the country. Congress has established a procedure for certain election law cases to be first heard by three-judge panels “in recognition of the fact that ‘such cases were ones of great public concern that require an unusual degree of public acceptance.’”[ref 445]
10. How can we design LFAI requirements for governments that nevertheless enable rapid adaptation of AI agents in government?
Perhaps the most significant objection to our proposal that AI agents be demonstrably law following before their deployment in government is that such a requirement might hurt state capacity by unduly impeding the government’s ability to adopt AI in a sufficiently rapid fashion.[ref 446] We are optimistic that LFAI requirements can be designed to adequately address this concern; but that is, of course, work that remains to be done.
Conclusion
The American political tradition aspires to maintain a legal system that stands as an “impenetrable bulwark”[ref 447] against all threats—public and private, foreign and domestic—to our basic liberties. For all the inadequacies of the American legal order, ensuring that its basic protections endure and improve over the decades and centuries to come is among our most important collective responsibilities.
Our world of increasingly sophisticated AI agents requires us to reimagine how we discharge this responsibility. Humans will no longer be the sole entities capable of reasoning about and conforming to the law. Human and human entities are no longer, therefore, the sole appropriate target of legal commands. Indeed, at some point, AI agents may overtake humans in their capacity to reason about the law. They may also rival and overtake us in many other competencies, becoming an indispensable cognitive workforce. In the decades to come, our social and economic world may be bifurcated into parallel populations of AI agents collaborating, trading, and sometimes competing with human beings and one another.
The law must evolve to recognize this emerging reality. It must shed its operative assumption that humans are the only proper objects of legal commands. It must expect AI agents to obey the law—at least as rigorously as it expects humans to—and must expect humans to build AI agents that do so. If we do not transform our legal system to achieve these goals, we risk a political and social order in which our ultimate ruler is not the law,[ref 448] but the person with the largest army of AI henchmen under their control.