The NDAA: A Key Vehicle for AI Governance
Summary
- The National Defense Authorization Act (NDAA) is one of the few “must-pass” bills in Congress every year, which makes it a key opportunity for AI legislation.
- The Fiscal Year 2026 NDAA (FY26 NDAA) contained nearly two dozen artificial intelligence-related provisions.
- While many of those provisions focus on accelerating adoption, others require DOD[ref 1] to develop standards, frameworks, and other policy measures to govern its AI use.
- Among the most notable AI-related provisions from the FY26 NDAA are its requirements:
- To create an AI Futures Steering Committee, through which senior Pentagon officials will formulate DOD policy for the evaluation, governance, and risk mitigation of advanced AI and artificial general intelligence (AGI); and
- To develop a standardized assessment framework for AI models currently used by DOD, along with department-wide guidelines to facilitate procurement of future AI models.
- The Fiscal Year 2027 NDAA (FY27 NDAA) markups include provisions related to autonomous weapons policy, AI procurement, and the AI capabilities of adversaries.
Introduction
The National Defense Authorization Act has quietly become one of Congress’s most powerful tools for shaping AI policy, and the FY26 NDAA featured many key AI provisions. This commentary compiles all the major AI provisions from the FY26 NDAA and analyzes the most significant language in detail. With some of the initial deadlines imposed by the FY26 NDAA now having passed—and with negotiations around the FY27 NDAA underway—it’s useful to take stock of the potential and pitfalls of these provisions.
The NDAA is not just restricted to the nuts and bolts of defense operations. It has also been used to achieve broader policy goals, sometimes by limiting the executive branch’s actions. For example, one of the most important and successful nonproliferation programs in history, the Nunn-Lugar Cooperative Threat Reduction Program, was originally proposed as an amendment to the NDAA and was subsequently expanded through the NDAA.[ref 2] More recently, the FY19 NDAA effectively banned the government from using certain Chinese telecommunications companies such as Huawei and ZTE; likewise, the FY26 NDAA bans certain foreign AI products like DeepSeek.
As the government increasingly prioritizes AI use in warfighting and military operations, the NDAA has a key role to play in shaping AI policy.
AI Governance in the FY26 NDAA
Notable Provisions
Several provisions stand out as particularly important for the government’s broader interest in overseeing and fostering the responsible development of secure AI systems:
- The Artificial Intelligence Futures Steering Committee;
- The AI Model Assessment and Oversight framework;
- Digital Sandboxes for AI;
- Physical and Cybersecurity Procurement Requirements for AI Systems; and
- The Autonomous Weapons Waiver Policy.
Section 1535: Artificial Intelligence Futures Steering Committee
Section 1535 requires DOD to create an Artificial Intelligence Futures Steering Committee (Steering Committee) to prepare DOD for advanced AI and AGI. The Steering Committee will be co-chaired by the Deputy Secretary of Defense and Vice Chairman of the Joint Chiefs of Staff (VCJCS). It will primarily be composed of principal deputies of the military services, relevant under secretaries (e.g., the Under Secretary of Defense for Research and Engineering (USD(R&E))), and others responsible for AI (e.g., the Chief Digital and AI Officer (CDAO)).[ref 3]
By January 31, 2027, the Steering Committee must submit a report to Congress covering what can be described as two main focus areas. First, the committee must help prepare DOD for advanced AI and AGI by creating:
- A proactive policy for the evaluation, adoption, governance, and risk mitigation of advanced AI systems, including systems that approach or achieve AGI.
- An analysis of the forecasted trajectory of advanced AI models and enabling technologies that could lead to AGI such as AI agents, neuromorphic computing, cognitive science applications, infrastructure needs, new microelectronics, etc.
- An analysis of the potential operational effects of integrating advanced AI or AGI into DOD networks and systems from a technical, doctrinal, training, and resourcing perspective to better understand effects on operational commands.
- A strategy for the risk-informed adoption, governance, and oversight of advanced AI and AGI including ethical, policy, and technical guardrails to maintain appropriate human decision-making and prevent misuse.
The second focus area is U.S. adversaries. Though not specifically named, the People’s Republic of China (PRC), which is actively pursuing AI capabilities that rival those of the United States, is likely the primary focus. The committee must assess the possible technological, operational, and doctrinal trajectories of U.S. adversaries with respect to AI capabilities, including the pursuit of AGI. Additionally, the committee must analyze the threat landscape associated with the use of advanced AI and AGI and develop options to counter these threats.
Within the Pentagon’s sprawling bureaucracy, there’s often fierce competition between different programs and priorities for funding and attention from leadership. In this sense, the Steering Committee could be a valuable forcing function for the department to prepare for advanced AI, reinforced by the requirement to report its findings to Congress by early 2027. There’s precedent for DOD using these sorts of committees as a way to spur action on issues such as software modernization and autonomous systems.
However, such committees sometimes serve more as a signaling mechanism for Congress than as a catalyst for serious action. Unless chairs or members of the committee invest their time and professional capital to drive it forward, it can easily devolve into a box-checking exercise. While the Steering Committee’s substantive mandate is broad, its required procedural actions, as set by Congress, are fairly minimal: meet at least once every three months, and submit a report on its findings to the relevant congressional committees by January 31, 2027. That means that depending on when the committee is actually established and how quickly it first convenes, it may meet only three or four times before its report is due.
On top of that, the NDAA provision does not allocate any dedicated staff or budget for the Steering Committee. Any resources must be drawn from existing reserves, which could further limit its capacity. Given those constraints and their already-full plates, the Steering Committee’s principals might be tempted to delegate their roles and responsibilities down the chain of command to other, typically less-empowered subordinates, whose remit might be narrower—i.e., drafting a report that satisfies Congress’s requirements while potentially tabling thornier policy disagreements or implementation details for later.
Congress should remain attuned to these possible failure modes and use its oversight power to solicit information about the Steering Committee and its progress, in the hopes of helping it gain and maintain momentum. There are some encouraging signs on this front. In March, Senator Jim Banks sent a letter to Secretary Hegseth requesting a staff-level briefing within 60 days to discuss DOD’s plans for the Steering Committee. The letter suggested areas of focus with respect to U.S.-PRC AI competition. Even just one or a few members of Congress taking specific, sustained interest in the Steering Committee could keep it high enough on DOD’s long list of priorities to increase its odds of success.
Congressional oversight can be particularly valuable in two ways. First, it can keep pressure on the committee if it fails to meet the report submission deadline of January 31. Second, and perhaps more importantly, Congress can help ensure that the Steering Committee doesn’t waste the 11 months between its reporting deadline and its termination date of December 31, 2027.
While the report is the Steering Committee’s most tangible required deliverable, Congress provided that the committee will continue to exist for nearly a year beyond the report submission deadline. This time would allow the committee to refine or update its policies and to work on implementing and disseminating the findings throughout DOD. Because the Steering Committee lacks deliverables or other measurable benchmarks throughout most of 2027, it’ll likely be incumbent on Congress to use tools like letters, hearings, and requests for briefings to push forward that updating and implementation work. These efforts could ultimately have a much greater impact on DOD operations in the long term than just the drafting of the report itself.
As of June 30, 2026, no public materials indicate whether the Steering Committee was established by the April 1 statutory deadline, or whether it has held its first meeting. That’s not necessarily cause for concern, as DOD is not required by the NDAA to report those actions to Congress or the public. But it does make it harder to predict which of these paths the AI Futures Steering Committee will ultimately follow. Overall, this provision could pay dividends by prompting DOD to proactively prepare for major threats and opportunities raised by AGI—planning that might otherwise get neglected—though its success is far from assured.
Key Dates
- 4/1/2026: Deadline to establish the Steering Committee
- 1/31/2027: Steering Committee’s report due to Congress
- 12/31/2027: Steering Committee terminates
Section 1533: AI Model Assessment and Oversight
Section 1533 instructs DOD to create a Cross-Functional Team (Team) for AI “model assessment and oversight.” The Team must develop a standardized assessment framework for AI models currently used by DOD, as well as guidelines to facilitate procurement of future models. The Team is led by the CDAO and composed of other DOD technology leaders, such as CIOs, CAIOs of the combatant commands, service acquisition executives, and USD(R&E). The Team must:
- Develop a “standardized assessment framework” for AI models currently used by DOD, including: performance standards, development documentation, testing procedures, compliance with ethical principles, assessment and validation methodologies, and security and compliance requirements under FedRAMP.[ref 4]
- Establish department-wide “guidelines” for evaluating future AI models being considered for use.
- Create “governance structures” for the development, assessment, testing, and deployment of models.
- Determine assessment levels for models based on “ultimate use case-based risk.”
- Establish “mechanisms” for intra-agency collaboration regarding the development, testing, assessment, and deployment of AI models.
- Develop processes for the submission, review, and approval of use cases for AI models.
This provision allows DOD to retain a lot of discretion over how it evaluates current and future AI models. Congress has mandated that DOD establish a framework and protocols, but didn’t set substantive thresholds for performance. That’s understandable to some degree, given the risk of setting standards via legislation, which might quickly become outdated and then prove difficult to adjust. And it’s similar to the approach that states like California and New York have taken in enacting frontier AI transparency reporting requirements. But some key requirements in the provision, such as the creation of “governance structures” and assessing “ultimate use-case-based risk,” use terms that are undefined and open to interpretation, and could have benefited from a bit more congressional guidance about the elements that should at least be considered or addressed.
That vagueness, combined with the long timelines the provision establishes, could make it hard for Congress to assess the Team’s progress. Congress notably gave the Team an extended timeline to develop its model assessments and oversight, which may be in tension with the pace of AI progress. The standardized assessment framework isn’t due until June 2027—a year and a half after enactment—and no actual assessments of DOD’s major AI systems are required until January 2028. Meanwhile, new frontier AI models are released many times a year.
To be sure, the Team’s task is difficult. And Congress sometimes errs by giving agencies unrealistically short deadlines. But a failure to keep up with the pace of AI development risks undermining the Team’s purpose. To frame that risk, consider the events that have transpired since the FY26 NDAA passed six months ago. First, there was the blow-up over contract terms between the Pentagon and Anthropic in February. More recently, the June 5 National Security Presidential Memorandum (NSPM) 11 ordered Secretary Hegseth, ODNI, and IC elements to “review and update procurement processes to ensure the rapid onboarding of the most advanced AI models from multiple vendors” within 120 days. It’s unclear how or whether this review will be coordinated with the procurement guidelines that the Team is tasked with developing on its longer timeframe.
Here, again, Congress can deploy its oversight tools to steer DOD in the direction of consistent and streamlined guidelines for AI procurement. It should aim to ensure that standards are applied uniformly and transparently, not reactively, to AI developers. Helpfully, this provision requires DOD to provide a briefing to congressional defense committees within 30 days of hitting significant statutorily prescribed milestones, starting with its establishment of the Team on or before June 1, 2026. That offers a natural opening for Congress to probe the Team’s trajectory, and potentially to spur a course correction if needed. Congress might consider incorporating that sort of regular briefing requirement into future AI-related NDAA provisions; it’s particularly beneficial in this area due to rapid and sometimes unexpected jumps in capabilities and risks, and might also have been helpful for similar initiatives like the Steering Committee discussed above.
Finally, it’s worth a closer look at the provision’s definition of “major [AI] system”—one of only a few terms that the provision does actually define—buried near the end of the provision. That definition limits coverage to systems used annually by at least 500 users within DOD, and excludes systems used solely for research, development, testing, or evaluation that have not been deployed for operational use. Elsewhere, the provision specifies that DOD must assess all major AI systems using the standardized assessment framework, leaving it somewhat unclear when or to what extent that framework also governs assessment of other AI models used by DOD. In other words, for models used by less than 500 employees per year, or those involved only in R&D, how will DOD assess performance, security, and “compliance with ethical principles”?
While this sort of line-drawing exercise is almost always difficult but necessary for administrability, in this instance the exclusions arguably represent the frontier of DOD’s own AI development and deployment in what could end up being the highest-stakes and hardest-to-monitor situations. At minimum, it’s plausible that some of the most powerful systems, deployed in potentially highly consequential cases, might be available to only a small number of users. Congress should ask DOD how it plans to assess AI systems that fall into those categories and potentially require the development of standards for such systems in future legislation.
Key Dates
- 6/1/2026: Deadline to establish Cross-Functional Team
- 1/1/2027: Deadline to designate Functional Leads for specialized functional, operational, or subject-matter areas within DOD
- 6/1/2027: Deadline for Cross-Functional Team to complete development of standardized assessment framework and governance structure
- 1/1/2028: Deadline to complete assessment of major AI systems used by DOD
- 12/31/2030: Cross-Functional Team terminates[ref 5]
Section 1534: Digital Sandbox Environments for AI
Section 1534 requires the CDAO to create a task force to promote AI sandbox environments supporting “experimentation, training, familiarization, and development.” The task force should “identify, coordinate, and advance” DOD efforts to develop and deploy AI sandboxes, with an eye toward accelerating AI adoption across the department. The provision defines an “[AI] sandbox environment” as a “secure, isolated computing environment that enables users with varying levels of technical proficiency to access [AI] tools, models, and capabilities for the purposes of experimentation, training, testing, and development without affecting operational systems or requiring specialized technical knowledge to operate.” The provision requires that the task force be established by April 1, 2026, and that the CDAO provide a briefing to congressional defense committees by August 1 on the task force’s goals and objectives.
One noteworthy aspect of this provision is the emphasis that Congress has placed on using sandboxes to facilitate training and familiarization with AI by DOD employees—“from personnel with little technical proficiency to personnel with expert technical proficiency.” Congress should be commended for devoting at least as much attention to that purpose as to how sandboxes are used to develop and test AI tools and models, which is often the main or even exclusive focus of sandboxing. In an organization as large and varied as DOD—and in which the stakes are matters of national security—giving employees a dedicated environment in which to try (and fail) so as to ultimately gain a level of comfort using novel and quickly evolving AI systems is critical to the widespread adoption that Congress is after.
One area where both DOD and Congress might focus some more attention during the required briefing is how the task force can facilitate a pipeline between successful AI development that occurs in sandboxes and the actual implementation of those systems, tools, or methods in the real world of DOD operations. That’s a topic that the provision as written doesn’t address as squarely, but it’ll be key to ensuring that DOD can fully capitalize on its investment in AI sandbox environments. DOD can be a process-heavy place at times; the task force will need to plan for how to judge when AI experiments are ready to graduate from sandboxes, and to efficiently move those successful innovations from sandboxes to the rest of the department.
Key Dates
- 4/1/2026: Deadline to establish Task Force on AI sandbox environments
- 8/1/2026: Deadline for Task Force to brief congressional defense committees on goals and objectives
- 1/1/2030: Task Force terminates
Section 1513: Physical and Cybersecurity Procurement Requirements for Artificial Intelligence Systems
Section 1513 requires DOD, in collaboration with industry and academia, to develop a framework for the implementation of cybersecurity and physical security standards and best practices for AI systems, “to mitigate risks to [DOD] from the use of such technologies.” The framework must cover enumerated concerns like insider threats, data poisoning, and adversarial tampering. The provision also instructs that the framework must be “risk-based,” drawing on existing reference documents, including NIST’s SP 800 series, and augmenting existing cybersecurity frameworks, including DOD CMMC.
To implement the best practices developed under the framework, DOD must amend the Defense Federal Acquisition Regulation Supplement (DFARS) “or take other similar action” ensuring that those practices apply to contractors who engage in AI development, deployment, storage, or hosting. In carrying out that function, DOD must weigh the costs and benefits of imposing security requirements on contractors—and specifically, the costs of “slowing down” AI development and deployment against “the benefits of mitigating national security risks and potential security risks” to DOD.
While this provision is expressly attuned to the potential costs of slowing down AI development through unduly onerous security requirements, it’s at least equally concerned with mitigating the risks to DOD—and national security more generally—that AI systems can pose. It will be worth monitoring how the framework approaches that statutorily required balancing, not least because of how it contrasts with the January 9 AI Strategy memo issued by Secretary Hegseth, which seemingly prized speed above all else.
Lines from that memo, like “speed wins,” and “We must accept that the risks of not moving fast enough outweigh the risks of imperfect alignment,” offer a preview of where DOD seems most likely to come down on these issues. They also suggest that Congress may have to be dogged in reviewing a required June status update and pursuing other oversight measures to confirm that the statutorily mandated cost-benefit analysis is sufficiently rigorous, with real attention to serious risks Congress mentioned, such as adversarial tampering.
Key Date
- 6/16/2026: Deadline for DOD to submit an update to the congressional defense committees on the status of implementing the requirements of the Physical and Cybersecurity Procurement provision
Section 1061: Notification of Waivers under DOD Directive 3000.09
Section 1061 requires DOD to notify congressional defense committees when it has waived DOD Directive 3000.09 (DoDD 3000.09) relating to the use of autonomous weapon systems (AWS).[ref 6] The notification must be in writing and transmitted to the relevant committees within 30 days of when the waiver was issued. The notification also must be unclassified and must include the rationale for the waiver, a description of the weapons system or technology covered by the waiver, and the anticipated duration of the waiver. DOD may include a classified annex to the waiver, as necessary.
DoDD 3000.09 states that “[a]utonomous and semi-autonomous weapons will be designed to allow commanders and operators to exercise appropriate levels of human judgment over the use of force” (emphasis added). As Kelley Sayler of the Congressional Research Service has noted, that does not mean that “manual human ‘control’” of the system is required, but rather mandates “broader human involvement in decisions about how, when, where, and why the weapon will be employed”—for example, “a human must assess the operational environment and decide to deploy the weapon, which can then operate autonomously.”
As most relevant here, DoDD 3000.09 allows for DOD to skip the traditional review and approval process for AWS when there is an “urgent military need.” Typically, the Under Secretary of Defense for Policy (USD(P)), USD(R&E), and the VCJCS must approve a system before formal development, and then it must be approved again before being deployed in operations by the Under Secretary of Defense for Acquisition and Sustainment, USD(P), and VCJCS.[ref 7] DoDD 3000.09 allows any of these parties to request a waiver of the policy requirements per approval of the Deputy Secretary of Defense.
Section 1061 is the latest in a series of recent NDAA provisions through which Congress has sought greater insight into DoDD 3000.09, particularly whether and how it’s being applied or modified. In the NDAA for fiscal year 2024, Congress required that DOD provide a briefing to congressional defense committees within 30 days of making any changes to DoDD 3000.09, including a description of the change and an explanation of the reasons for it. In fiscal year 2025’s NDAA, Congress required DOD to submit annual reports to those committees through December 31, 2029, on its approval and deployment of lethal AWS under DoDD 3000.09, including any systems that received a waiver from the policy’s review requirement.
This is a prime example of Congress using the NDAA to iterate and build progressively on existing requirements as issues rise in salience—and the salience of DoDD 3000.09 has arguably never been greater. The directive featured prominently in the Pentagon’s dispute with Anthropic earlier this year. Furthermore, NSPM-11 issued by President Trump on June 5 orders Secretary Hegseth to update DoDD 3000.09 within 90 days, and to review it annually “to account for the rapidly evolving capabilities of AI systems” and “ensure the deliberate adoption of AI systems that respect the chain of command and operational authorities.”
In keeping with this progression, one valuable adjustment to Section 1061 that Congress might make would be an amendment that requires an update to the committees when the duration of a waiver is extended beyond the “anticipated” period previously notified, as well as regular updates for any waivers that DOD issues that don’t have a specified end date or timeframe. This would help to guard against overreliance on waivers that might be open-ended or persist for years without prompting congressional scrutiny. Otherwise, waivers issued in prior years might not necessarily show up in the annual reports required under the NDAA for fiscal year 2025.
Going further, Congress could consider whether to codify all or parts of DoDD 3000.09, potentially preserving DOD’s ability to waive or deviate from aspects of the policy when warranted to avoid restrictions that might prove too rigid or become quickly outdated. Both the House and Senate FY27 NDAA markups address DOD AWS policy, though with notable differences. While the final text of any AWS-policy provision in the FY27 NDAA may differ substantially from the markups, these initial versions shed some light on possible approaches.
The House markup requires that DOD update its AWS policy, including DoDD 3000.09, within one year of enactment—significantly longer than the 90 days DOD has to update the directive under NSPM-11. But as compared to the NSPM, the House markup provides more detail on what an updated policy must include, not least “requirements to preserve existing human command responsibility for the use of force involving autonomous systems or artificial intelligence-enabled systems, including procedures to identify the human commanders or operators responsible for authorizing, supervising, and terminating such use of force.” The Senate markup goes much further still, prescribing an AWS policy and governance regime for DOD in significantly greater detail, with an even more defined substantive floor. And while the Senate markup in multiple places incorporates DoDD 3000.09’s familiar standard of “appropriate levels of human judgment,” it does not directly address the directive’s existing waiver process, leaving it unclear whether that aspect of DoDD 3000.09 would pass muster and thus survive the substantive standards established by this provision.
If Congress opts for a more prescriptive approach, it could consider adding a sunset clause to hedge against the risks of excessive rigidity or obsolescence. A short initial timeline of 1–2 years would prompt Congress to revisit and adjust as needed, providing a short feedback loop for any DOD operational concerns or issues that emerge.
The Road Ahead: What to Watch for in 2026 and 2027
The FY26 NDAA showed how the annual defense bill can be one of—or even the—primary vehicle for the governance and oversight of defense-relevant AI decisions. Congress can use it to spur prioritization and adoption (Steering Committee and sandboxes), mandate the development of standards and assessments (AI model oversight), prompt consideration and safeguarding against security risks (cybersecurity procurement requirements), and gather information about how the department is using AI (autonomous weapons waivers and various briefing requirements in other provisions).
Throughout the remainder of 2026 and beyond, it’s worth continuing to monitor updates to key provisions via congressional briefings and other potential disclosures, especially regarding autonomous weapons waivers and the implementation of an AI physical and cybersecurity procurement framework and AI model assessment and oversight. At least one of these initiatives, the AI physical and cybersecurity procurement framework, expressly requires that DOD seek input from groups like industry and academia. Experts should look for opportunities to engage through requests for information or other formats. Congress also has a significant role to play in ensuring that implementation proceeds responsibly and on schedule, using oversight tools like letters, briefing requests, and hearings to supplement the reporting requirements baked into some, but not all, of the key provisions.
As negotiations for the FY27 NDAA ramp up, we can expect numerous AI initiatives to be considered and ultimately included—perhaps even more than last year, since other legislative vehicles will likely be few and far between in this midterm election year. The current House and Senate FY27 NDAA markups include provisions on AI incident and vulnerability reporting within DOD, using AI agents at scale and speed, and promoting competition in AI procurement. The FY27 NDAA could also serve as the vehicle for another attempt at federal preemption of state AI laws, which was dropped shortly before last year’s bill was passed.
In all of these, Congress should learn from last year’s NDAA. It should craft implementation timelines for DOD that provide space for careful consideration but are not overly long relative to the rapid rate of technological development and diffusion. And it should think about where to build in briefing and other reporting requirements to fill in its knowledge gaps regarding implementation, while being sensitive to the demands they impose on personnel’s time. Doing so helps Congress not only ensure that last year’s initiatives are proceeding according to plan, but also provides valuable insight about unexpected challenges or shortcomings that can inform the coming year’s bill.
Whistleblower Protections in SB 53: Strengths, Limitations, and Open Questions
Executive Summary
SB 53 greatly improves the AI safety legislative landscape in California, but achieves only partial success in its whistleblowing protections. Its major success is that it significantly increases the number of safety-relevant issues that can be reported to authorities. In particular, employees can now blow the whistle when they believe frontier developers have not reported critical safety incidents or where large frontier developers have made materially false or misleading statements about, or are not complying with, their AI framework. Employees “responsible for assessing, managing, or addressing risk of critical safety incidents” will also be explicitly protected when blowing the whistle about catastrophic risks. SB 53 also requires large frontier developers to provide an anonymous internal reporting channel that a select group of employees can use to report catastrophic risks and that all employees can most likely[ref 1] use to report a violation of the law (including of SB 53 itself).
Looking more deeply at the provisions of SB 53, however, we see a more mixed picture. An ideal AI whistleblower law would ensure that all reasonable risks could be reported; that all individuals capable of spotting such risks could report them without fear of retaliation; that any relevant individual could support government investigations without fear of retaliation; that authorities are equipped to investigate disclosures; and that real consequences exist for violations. SB 53 achieves each of these partially.
First, the responsibility for disclosing catastrophic risks is not placed onto companies, but instead on an unclearly-defined subset of employees. SB 53 does not require companies to report a specific and substantial danger to the public health or safety resulting from a catastrophic risk to the Office of Emergency Services (OES). Nor do evaluation providers receive any protection from retaliation, either for making reports or for participating in government investigations.
Second, while the definition of catastrophic risk is relatively broad and does not require a clear violation of the law, it is limited to specific types of catastrophic risk and harms only above a high threshold: fifty deaths or a billion dollars in damages.
Third, although SB 53 creates incentives for companies and insiders to report harm caused by AI, it is unclear what consequences these reports will entail. Company incident reports are sent to the OES, where they might not be accessible to the public, and whistleblower reports of catastrophic risk to California’s Attorney General (AG) or a federal authority. The OES lacks clear powers to compel companies to change their behavior, the AG has no clear mandate to intervene in the absence of a legal violation, and no federal authority has established jurisdiction over such risks.
Lastly, SB 53 does not adjust the penalties for violating whistleblower protections in California, which are meagre at $10,000 per violation — a far cry from the $1m violation cap for other SB 53 violations, and extremely little in the context of large frontier developers, defined as having gross revenue of over $500,000,000.
The next step is to ensure SB 53’s faithful implementation. State agencies must build the necessary expertise: the OES and the AG need access to specialised expertise to evaluate and respond to critical safety incidents and catastrophic AI risks. These agencies should collaborate closely to develop a comprehensive understanding of emerging threats and assess potential legal violations.
Background
SB 53’s whistleblower provisions are legally entwined with California’s pre-existing whistleblower framework, which they extend, and SB 53’s core transparency requirements, for which they serve as an enforcement mechanism.
CA Labor Code § 1102.5 is California’s general whistleblowing law, covering all industries and employees. It prohibits employers from retaliating against employees who disclose information, which they have reasonable cause to believe to be a violation of the law, to a government or law enforcement agency, or to a person with authority over the employee. These protections cover a wide range of potential violations. Nevertheless, California’s protections are narrower than some other states, such as New York, as they (i) only cover employees and do not extend to contractors and (ii) only protect disclosures of violations of the law, and do not protect employees from retaliation for disclosing a substantial and specific risk to public health and safety. This is particularly significant in the context of AI as frontier AI companies frequently rely on contractors for safety-relevant roles such as red-teaming and safety evaluations[ref 2] and novel AI risks often do not constitute clear legal violations, making the ability to report risks to public health and safety essential for early intervention.
SB 53, or The Transparency in Frontier Artificial Intelligence Act, signed into law in September 2025, creates a transparency framework for the most powerful AI systems. The Act applies to “frontier developers”, defined as persons who have trained or initiated the training of AI models using extraordinary computing power (greater than 1026 FLOPs) and imposes heightened obligations on “large frontier developers”, defined as frontier developers with over five hundred million dollars ($500,000,000) in annual revenue. As of 26th January 2026, the only publicly known frontier developers are xAI and OpenAI, while the only large frontier developer is OpenAI.[ref 3] Beyond whistleblower protections, outlined below, SB 53’s main contribution is introducing transparency requirements, spanning four key areas: i) Frontier AI Framework Requirements: Large frontier developers must publish annually-reviewed protocols for managing catastrophic risk; ii) Transparency Reporting Requirements: Developers must publish summary reports of features and risks, similar to existing model cards and system cards, before deploying new or substantially modified models; iii) Government Reporting Requirements: Frontier developers must report critical safety incidents to the OES within 15 days (or 24 hours if posing imminent risk of death or serious injury), with large developers also submitting quarterly risk assessment summaries; iv) Prohibition on materially false statements: Large frontier developers are prohibited from making materially false or misleading statements about catastrophic risks from their models or their management of such risks.
Crucially, these requirements are legally binding. As such, companies that fail to comply are in violation of California Law and hence whistleblower protections apply to any employee who reports them and are a critical oversight mechanism.
Policy Analysis
SB 53 extends pre-existing whistleblower protections to cover reporting catastrophic risks as well as legal violations, creates mandatory internal reporting channels, and enables employees to report critical compliance failures directly to authorities. Our analysis proceeds through four dimensions: personal scope, material scope, remedies, and channels. For each aspect of whistleblowing law, we discuss the advantages and limitations of SB 53’s provisions.
Personal Scope
Personal scope defines who can make a whistleblowing disclosure. Whistleblowing law is part of the California Labor Code and hence only governs employees whose employment contract is under California law. SB 53 creates a tiered protection structure: all employees receive protection when reporting violations of SB 53’s requirements; and a subset, ‘covered employees’, defined as those responsible for assessing, managing, or addressing risk of critical safety incidents, receive protection for reporting catastrophic risks that do not include a legal violation. The scope of ‘covered employee’ remains ambiguous, creating uncertainty about who falls into this protected group. Nevertheless, the breadth of the language suggests that most employees whose work relates to AI safety in some way are likely “covered”.
Advantages
- Well-Informed Reports: One advantage of the limitation in scope is that those responsible for critical safety incidents are likely to also be the employees who are best placed to assess risks and hence to blow the whistle if their concerns are not addressed, resulting in better-informed reports
Limitations
- Limited Employees Can Report Catastrophic Risks: SB 53 protects only “covered employees,” which it defines as employees who are “responsible for assessing, managing, or addressing risk of critical safety incidents.”
It is not clear which lab employees are “covered” and which are not under this definition. Interpreted broadly, it could include a substantial percentage of all lab employees, including e.g. any employee with any responsibility for information security. After all, the definition of critical safety incident includes “unauthorized access to… the model weights of a foundation model that results in… loss of property,” and any employee who works on information security is in some sense “responsible for… addressing risk of” unauthorized access to their employer’s sensitive data. Interpreted more narrowly, the definition could include only the members of a lab’s safety team, or only the members of the safety team specifically responsible for addressing catastrophic risks. This is an open question and may end up being decided in court.
A somewhat unusual consequence of this limitation in scope is that Chapter 25.1 is included under SB 53’s material scope (§ 1107.1.(a)(2)) only for employees responsible for critical safety incidents and not clearly all employees who are responsible for the various parts of Chapter 25.1. - Contractors Out of Scope: While other whistleblower protection regimes extend to protect non-employees who have a working relationship with the company (e.g. volunteers, board members, etc.), SB 53 and the California Labor Code do not. Frontier companies commonly hire contractors for longer-term engagements and important roles such as management, making this exclusion a particularly strong limitation in scope. That said, it could be possible to argue in court that contractors who work full-time for a single company on long-term contracts would count as employees.
Material Scope
Material Scope defines the subject matter that can form the content of a whistleblowing disclosure. SB 53’s key contribution is extending California’s whistleblower protections beyond legal violations by protecting covered employees from retaliation for reporting “a specific and substantial danger to the public health or safety resulting from a catastrophic risk” with “reasonable cause to believe” such danger exists (§ 1107.1(1)). To understand this scope, two definitions and their thresholds are essential: “critical safety incident” and “catastrophic risk.”
“Critical safety incident” means any of the following:
- Unauthorized access to, modification of, or exfiltration of the model weights of a foundation model that results in death, bodily injury, or damage to, or loss of, property.
- Harm resulting from the materialization of a catastrophic risk.
- Loss of control of a foundation model causing death or bodily injury.
- A foundation model that uses deceptive techniques against the frontier developer to subvert the controls or monitoring of its frontier developer outside of the context of an evaluation designed to elicit this behavior and in a manner that demonstrates materially increased catastrophic risk.
“Catastrophic risk” means a foreseeable and material risk that a frontier developer’s development, storage, use, or deployment of a foundation model will materially contribute to the death of, or serious injury to, more than 50 people or more than one billion dollars ($1,000,000,000) in damage to, or loss of, property arising from a single incident involving a foundation model doing any of the following:
- Providing expert-level assistance in the creation or release of a chemical, biological, radiological, or nuclear weapon.
- Engaging in conduct with no meaningful human oversight, intervention, or supervision that is either a cyberattack or, if committed by a human, would constitute the crime of murder, assault, extortion, or theft, including theft by false pretense.
- Evading the control of its frontier developer or user.
The Act expressly excludes risks from the category of catastrophic risks: information generated by a model if it is already publicly available, lawful federal government activity, and situations where the model causes harm in combination with other software, but AI did not materially contribute to the harm. Thus ‘catastrophic risk’ in the Act only refers to CBRN and loss of control risks.
Advantages
- All Employees Can Disclose Violations of SB 53. The whistleblower section of SB 53 asserts any employee’s right to receive protection against retaliation if they blow the whistle with reasonable cause to believe that any violation of law, including SB 53 itself, occurred (§§ 1102.5(b), 1107.1(j)(1). This includes, for example,
- Misleading Statements: As companies are prohibited from publishing materially false or misleading statements, developers who do so are in violation of state law. Given the California Labor Code, employees would thus be protected if they report such misleading statements to a government or law enforcement agency—for the first time ever allowing employees to correct statements made by companies on their frontier safety frameworks and incident reporting, albeit only to government authorities such as the Attorney General.
- Failure to Report Critical Safety Incidents: Frontier developers must disclose critical safety incidents within 15 days of an incident’s discovery (§ 22757.13.(c)). Employees would be protected in reporting such an incident if they had reasonable cause to believe that such a report wasn’t made.
- Failure to Report Critical Safety Incidents that pose an imminent risk of death or serious injury: Frontier developers must report an incident of this nature within 24 hours of discovery. Employees are protected for reporting failure to do so (and hence also for reporting the incident itself), if they have reasonable cause to believe that the company did not make a report. Employees will likely only be able to claim protections for reporting violations under this rule if harm from the incident has already materialized, with more harm being imminent. The only exception here is deception, where only an increase in catastrophic risk already requires an incident report, and hence reporting on imminent harm risk resulting from it.
- Failure to Comply with their Frontier AI Framework: This includes the failure to publish a justification in the event of a material modification to the frontier AI framework.
- Failure to publish their transparency report: This includes the failure to include all required information.
- Catastrophic Risks can be Reported: As noted above, this is an important extension of California whistleblower law, which previously only covered reports of unlawful activity.
- Reasonable Cause to Believe: Whistleblowers receive protection for reports that they reasonably believe to be true, ensuring that employees are encouraged to come forward with any concerns they may have, before those concerns materialise into concrete harms. This “reasonable cause to believe” standard is generally considered to be whistleblower-friendly and is consistent with pre-existing California whistleblower law.
Limitations
- Lack of Certainty: SB 53 protects disclosures only if they relate either to a violation of law or a “specific and substantial danger to the public health or safety resulting from a catastrophic risk.” “Catastrophic risk” is a high and difficult-to-calculate bar to meet, and we worry that this requirement will have a chilling effect on potential whistleblowers. Particularly in the AI industry, where risks are novel and probabilistic, it is extremely difficult to determine the exact harm that can result from a risk. The phrasing of the Act also suggests that a risk of 49 deaths is insufficiently bad to raise a concern with the government if a large frontier developer is not addressing it. Additionally, the more-than-fifty-death threshold is unprecedented: it is not in line with risk-of-harm whistleblower legislation that exists in other states, such as New York, where existing whistleblower protections cover significant harm to even a single person.
- Single Incident: The ‘single incident’ requirement in the definition of catastrophic risk (22757.11.(c)(1)) could significantly limit the scope of risks which can be reported. For example, if risk stemming from a single model were to threaten the deaths of hundreds, but through separate channels and at different times, those deaths might not arise from a “single incident,” and therefore the risk of such deaths might not be reportable as a catastrophic risk.
- Limited Scope of Covered “Catastrophic Risks”: Not all significant risks of harm are covered under the ability to report catastrophic risks. In SB 53, “catastrophic risk” from an AI model does not cover any risk of a certain amount of harm caused by a model, but only particular types of risk: namely, risk that a frontier model will assist in creating a CBRN weapon, engage in a cyberattack or other crime autonomously, or escape human control. Any risk of a model committing a cyberattack, murder, or theft where it is directed to do so by a human is not covered under the Act, no matter how large the scale. In the same way, the definition of a critical safety incident is also limited to particular risk pathways (22757.11(d)).
- Limited Ability to Warn of Risks: While the regulation requires the logging of all “critical safety incidents,” it does not create protections for whistleblowers who warn of the risk of critical safety incidents, even using internal channels. If the legislation had included protected internal channels for reporting risks of critical safety incidents, it could have incentivised the avoidance of incidents rather than only their reporting.
Remedies
SB 53 applies existing Labor Code remedies to its whistleblower provisions. This section examines the protections available to whistleblowers and deterrents against retaliation.
Advantages
- Extends Labor Code Remedies to Reports of Public Safety Dangers from Catastrophic Risks: Covered employees who face retaliation for reporting a catastrophic risk are entitled to the remedies in the California Labor Code, including burden-of-proof reversal (§ 1107.1(g)) and injunctive relief (§ 1107.1(h)). The same is true for retaliation suits brought by any employee who reports a violation of SB 53 (§§ 1102.6 and 1102.61-2).
- Incentivizes Internal Knowledge Sharing: Imminent critical safety incidents can be reported to the AG if the developer has not logged them with the OES within 24 hours. This thus incentivises sharing with employees the knowledge that risks have been reported to the OES in order to avoid over-zealous reporting to the California AG.
Limitations
- Limited Scope: Whistleblower protections in SB 53, unlike in the EU’s whistleblower directive,[ref 4] do not extend to family members. Especially in the context of the Bay Area, where spouses often both work in the AI industry, this can strongly discourage potential whistleblowers and does not have clear benefits.
- Inconsistent Belief Standards: SB 53 uses different standards for determining access to an internal reporting channel and protection from retaliation. Section 1107.1(e)(1) requires only that an internal report is made in “good faith,” but the anti-retaliation protection in 1107.1(a) requires that an employee have “reasonable cause to believe” that their disclosure involves a violation of law or a substantial danger. Thus, a covered employee who anonymously submits an internal report in good faith but cannot meet the “reasonable cause” standard has legitimately used the internal reporting channel but has no statutory retaliation claim under § 1107.1(a) if their anonymity is breached and they are retaliated against.
- Limited Government Penalties: The California Labor Commissioner can impose fines of up to $10,000 for violations of the Labor Code, including whistleblower protections (§ 1102.5(f)(1)). Large frontier developers are defined as having a gross revenue of over five hundred million dollars, and hence will not be deterred by a $10,000 fine from retaliating against whistleblower or not complying with any other whistleblower regulation. However, deterrence could come from other means, like a retaliation suit by the whistleblower, who would be entitled to damages and injunctive relief.
Channels
Whistleblowing channels are the individuals, agencies, or offices to which a whistleblower disclosure can be made. SB 53 protects covered employees if they whistleblow “to the AG, a federal authority, a person with authority over the covered employee, or another covered employee who has authority to investigate, discover, or correct the reported issue” (§ 1107.1(a)). Additionally, SB 53 requires the creation of “a reasonable internal process through which a covered employee may anonymously disclose information to the large frontier developer if the covered employee believes in good faith that the information indicates that the large frontier developer’s activities present a specific and substantial danger to the public health or safety resulting from a catastrophic risk” or a violation of SB 53’s transparency obligations. Under the California Labor Code, any employee is protected if they whistleblow to “a government or law enforcement agency, to a person with authority over the employee or another employee who has the authority to investigate, discover, or correct the violation or noncompliance,” or “any public body conducting an investigation, hearing, or inquiry” (§ 1102.5(b)). California’s Labor Code also provides a whistleblower hotline, operated by the AG, intended to receive calls from whistleblowers. Following a report made to the hotline, the AG is directed to refer calls received on the hotline to the appropriate government authority for review and possible investigation.
Advantages
- Choice of Internal or External Channels: In line with California Labor Code, whistleblowers have the freedom to choose internal or external channels to raise concerns.
- Expert Internal Channel: SB 53 allows whistleblowers to approach persons responsible for critical safety incidents, which, if this is equivalent to a subset of the safety team, encourages employees to go to those who are best-placed to assess risks.
- Anonymous Internal Channel: SB 53 requires large frontier developers to create internal channels for raising concerns and clearly prohibits retaliation against those who are qualified to use this channel. These channels have a number of important features:
- Most importantly, SB 53 necessitates mandatory updates to the frontier developer’s board every quarter of the disclosures and associated responses. This ensures that the board has an accurate overview of employees’ concerns and creates an oversight mechanism for the reporting channel itself.
- The channel must allow for anonymous reporting, which reduces the risk of retaliation and incentivizes internal reporting, allowing developers to solve the issue swiftly without the involvement of external parties.
- Finally, SB 53 requires that monthly updates be provided to the employee who made the disclosure. This reassures the employee that their concerns are being taken seriously and, if the developer’s response is insufficient, the employee can follow up on the issue, externally if necessary.
Moreover, while SB 53 itself only asserts that covered employees are protected when using this channel, pre-existing California whistleblower law extends the scope of this protection to any employee who reports unlawful activities. Specifically, SB 53 only specifies that “covered employees” (i.e. those who are “responsible for assessing, managing, or addressing risk of critical safety incidents”) receive protections for using this “reasonable internal process” (§ 1107.1(e)(1)), § 1102.5 of California’s Labor Code specifies that any employee has protection when they report a risk to “another employee who has authority to investigate, discover, or correct the violation or noncompliance.” As an internal process for reporting violations necessarily goes to those who have the authority to discover violations, all employees should receive legal protection when using this channel to report violations of the law. However, whether all employees will have access to this internal channel remains to be seen.[ref 5]
Finally, we note that companies are likely to be able to de-anonymize internal whistleblower reports, especially if they prevent non-covered employees from accessing the reporting channel, thereby limiting the pool of potential whistleblowers. Companies are not explicitly barred from seeking out the identity of internal whistleblowers.
- Federal Authority SB 53 protects disclosures to any “federal authority,” an undefined term that reads broadly on its face but may not include, for example, members of Congress.
Limitations
- No Public Disclosure: Even in extreme circumstances where there may be imminent danger, public disclosure is not explicitly protected.
- Separation of Channels: It is perhaps unusual that incident reports must be sent to the OES, but reports on catastrophic risks by whistleblowers cannot be sent to it. However, since OES is a government agency, any violation of law can be reported to it under pre-existing California whistleblower law.
- Lack of Anonymity and Confidentiality in External Channels. While a reporting channel to the AG is mandated and reporting is also possible to the OES where there is a violation of law, these channels do not have any requirements for anonymity or confidentiality. Not only do anonymity and confidentiality guarantees protect whistleblowers, they help whistleblowers feel safe enough to come forward.
- Lack of Clarity on Reasonable Internal Channel: SB 53 would be improved by a better-specified explanation of what is required for an internal channel to be “reasonable.” If an internal channel was owned by a company’s in-house legal team (whose duty would run to the company rather than to the whistleblower) or by an executive who could be the subject of a disclosure, whistleblowers could be deterred from disclosing.. Furthermore, SB 53 does not specify a confidentiality policy and process, although such specifications would improve whistleblowers’ confidence that their identity would not be revealed and incentivize legitimate disclosures.
Advice and Consent for Major Governmental AI Deployments
On March 26, Judge Rita Lin of the U.S. District Court for the Northern District of California granted a preliminary injunction for Anthropic in its ongoing dispute with the Department of Defense over its designation of Anthropic as a supply chain risk. The Anthropic affair has intensified a debate over how law should constrain the executive branch’s use of artificial intelligence (AI). Much of this debate centers on the types of substantive rules at the heart of the Anthropic dispute, such as: Should large-language models (LLMs) be used for lethal autonomous weapons? What rules should govern the use of AI to process intelligence? What exactly do “any lawful use” provisions allow, and who decides?
While Congress should resolve many of these matters, its ability to prospectively regulate governmental AI systems is limited. Developing and deploying AI systems in government settings requires myriad choices, many of which could impact safety, security, and constitutional values. Congress cannot easily anticipate all of these choices, much less decide on rules for them in advance. This creates a dilemma: A complete legislative specification of these design choices will remain impossible, but reliance on the good faith of the executive branch to govern its own AI deployments responsibly is equally unwise.
Additional oversight mechanisms are therefore necessary. This article proposes a new approach: Congress should require the executive branch to secure affirmative congressional approval before deploying AI in certain high-risk domains. Here’s how this could work. Congress would first designate certain governmental domains as “Protected Use Cases”: areas of use where, in its judgment, additional congressional oversight is warranted. Congress would then enact a default rule prohibiting the use of (specific types of) AI for Protected Use Cases.
To overcome this prohibition, the president would be required to submit to Congress a detailed proposal for deploying AI in a Protected Use Case. This would include, for example, a particularized description of the AI system, planned guardrails, authorized and prohibited use cases, authorized users, oversight affordances, and permitted modifications. After back-and-forth negotiations between the branches, Congress would vote on ordinary legislation to provide a specific exception for the proposed deployment, as amended by Congress during the legislative process. Once the bill becomes law, the specific deployment would be approved, but the background prohibition on Protected Use Cases would remain for other, nonapproved AI systems.
The resulting dynamics would loosely mirror the constitutional advice-and-consent process for principal officers, granting Congress an additional mechanism for subjecting powerful governmental decision-makers to public oversight and democratic legitimation of governmental AI systems, without the need to rely entirely on prospective legislation.
Scalable Subordinates
AI systems are increasingly indispensable tools of governance. Many of the central tasks of public administration—collecting and analyzing information, investigating possible offenses, and coordinating the organs of state toward substantive policy goals—seem ripe for augmentation, acceleration, and automation by AI systems.
But with this potential also comes great peril. The executive branch is checked in significant part by its human workforce. Soldiers and civil servants have diverse values and interests that typically diverge from the president’s to some degree. They have an independent obligation to obey the law and uphold the Constitution, while lacking many of the legal protections afforded to the commander in chief. This gives them powerful incentives to resist executive branch abuses.
Replacing human government workers with AI systems could unsettle these dynamics. Without specific requirements to the contrary, governmental AI systems could be built to be unwaveringly obedient. The systems would not fear criminal liability, worry about their post-government reputation, or suffer crises of conscience. They could act in unison at superhuman speeds, meticulously covering their tracks and frustrating attempts to hold them or their principals accountable.
Individual human employees or officers are also sometimes wicked, of course. But the downside risk from any given individual is limited. AI systems, by contrast, are highly scalable: Eventually, an AI system could perform the work of entire bureaucracies.
This structural shift suggests a case for recalibration of Congress’s checking function. One of Congress’s most significant powers is the constitutional requirement that the Senate confirms the executive branch’s principal officers. Limiting this requirement to principal officers was a prudent response to the realities of human administration. If the Senate needed to consent to the appointment of every officer or employee, it would have little time for other business. It therefore made sense to focus senatorial scrutiny on the top of the organizational chart. Indeed, the number of Senate-confirmed positions is arguably already too large.
But if a small number of executive branch AI systems could perform nearly all the work of entire departments, the design of those systems would be at least as important as the selection of a department head. This suggests that congressional involvement in the selection and design of those systems could be similarly appropriate.
Red Lines and Gray Areas
A congressional approval requirement makes sense for another reason: It would be unwise for Congress to rely solely on prospective legislation to govern the design, deployment, and use of executive branch AI.
The prospect of a highly automated executive branch has previously motivated me to argue that governmental AI systems should be designed to follow the law. Bright-line rules governing the procurement, deployment, behavior, and instruction of governmental AI systems will be crucial to guarding against their misuse.
But as any law student knows, it is impossible to identify and agree on rules for every imaginable scenario an actor might face. AI systems themselves might reduce the costs of the legislative process, but the complete specification of desirable behavior will always elude us. This presents a significant limitation of our prior proposal to require that governmental AI systems be “law-following AIs.” The law will always have gaps, and clever AIs will be good at finding them. Law-following AI, on its own, cannot prevent AI systems from exploiting such loopholes, because they remain legal by definition.
Some recent trends in frontier AI development vividly illustrate this point. Frontier AI companies rely on documents called “model specifications” or “constitutions” to shape the behavioral propensities of their AI systems. These documents contain bright-line rules, such as “never [p]rovide serious uplift to those seeking to create biological, chemical, nuclear, or radiological weapons with the potential for mass casualties.” But the documents also rely on a sort of Aristotelian virtue ethics that cannot be formalized as legal requirements. In other words, it may be important that executive branch AI systems have good “character” that dictates how they should navigate moral or legal gray areas. While a general legislative definition of “good character” would be unwise and difficult to pin down, assessment of whether a particular AI system has good character mirrors the familiar confirmation hearing process, where holistic assessment of a nominee’s past conduct and disposition is fair game.
The impossibility of a completely specified code for AI behavior is an instance of a more general issue: Safe and socially beneficial AI behavior is the product of a large number of design choices. Congress could not—and should not attempt to—prospectively dictate how the executive branch must make these design choices. Similarly, evaluation of AI systems is far from a mechanistic science: Proper testing involves making a large number of context-specific judgment calls that would elude legislative prespecification. However, assessing claims about specific AI systems is significantly easier. A congressional approval regime would enable such flexible assessments and allow Congress to reject proposed deployments on the basis of considerations that could never have been operationalized in prospective legislation.
Statutory Advice and Consent
To enact this policy, Congress would first need to define the set of executive branch deployments that require specific congressional approval. These are the Protected Use Cases. Careful demarcation of the Protected Use Cases is critical: Too narrow a scope could enable executive-branch misfeasance, while overbreadth would hamper state capacity.
Congressional preapproval is most important for systems that will exercise certain functions that pose a significant risk to the constitutional order, and for which after-the-fact remedies are limited. Imagine, for example, an AI system that integrates existing sources of lawfully collected information across multiple agencies, including purchased data, open-source information from the internet, intelligence sources, public security camera footage, and information already reported to the government (such as mortgage applications). The AI system then identifies possible crimes, obtains warrants for further information, and decides whether to recommend them for prosecution.
It seems likely that such a system would identify thousands of previously unidentified crimes. Perhaps, in isolation, this could be a valuable way for the government to catch more criminals. But the opportunities for abuse are obvious. Absent technical safeguards, it would be easy for a malicious government to use such a system to scrutinize political opponents systematically while ignoring political allies. Given the difficulty of successfully arguing a defense of selective or vindictive prosecution, this could be a powerful tool for political repression.
A full enumeration of candidate Protected Use Cases is beyond the scope of this piece. However, uses that might warrant inclusion include criminal investigations, domestic intelligence-gathering and analysis, domestic military deployments, and prosecutions. While this would include a wide range of governmental functions, it would also leave many core functions unimpeded: The work of many federal agencies could be entirely exempted.
Congress would then establish by statute that AI systems could not be used in a Protected Use Case without explicit statutory authorization. This basic structure is similar to familiar statutes such as the Posse Comitatus Act, which prohibits the use of regular military forces for domestic law enforcement without express congressional or constitutional authorization.
Congress should then statutorily preapprove certain deployments within the Protected Use Cases, meaning additional congressional approval would not be necessary. At least two categories of preapproval seem prudent. The first set of preapprovals would be for classes of AI systems that seem unlikely to pose the severe risks to liberty that motivate this proposal. One candidate class would be so-called narrow AI systems. While there are serious risks associated with these technologies, their adoption seems unlikely to displace human civil servants to a destabilizing degree.
Congress should also statutorily preapprove testing and development of AI systems for Protected Use Cases. This statutory scheme depends on the executive’s ability to propose well-specified deployments to Congress for approval. Departments and agencies cannot do this unless they can develop and test AI systems for Protected Use Cases without prior congressional approval. Of course, it would be important to carefully define “testing and development” so that it could not be abused to circumvent the general preapproval requirement. However, this is a manageable legislative drafting task.
Any governmental deployment of AI in a Protected Use Case not covered by a preapproval provision would be prohibited by default. Federal employees who willfully violate this prohibition would be subject to civil and criminal penalties, as would vendors who willfully aid in illegal deployment. This enforcement mechanism would parallel (and supplement) the Antideficiency Act, which prohibits federal employees from expending federal resources in excess of statutory appropriations. The executive branch would therefore need congressional approval for deployments for Protected Use Cases not covered by statutory preapprovals. Here’s how I envision that process working. Congress would give the executive branch a generous budget to develop and test prototypes for Protected Use Cases. This generous funding would help entice vendors to participate in prototype development, notwithstanding the prospect of Congress rejecting a proposed deployment. And the executive branch, cognizant of the need for congressional approval, would conduct the development and testing phase to maximize the likelihood that Congress signs off. They would, for example, brief the relevant committees about development progress and seek input on which tests should be conducted.
When the time is right, the executive branch would submit to Congress a report for proposed deployment of an AI system for a Protected Use Case. Obviously, since the approval requirement and process are entirely statutory, Congress cannot bindingly dictate the scope of future congressional approvals. But the policy goals of this process would be best advanced if the proposed deployment were fairly specific. It should include, for example, a technical description of the system being deployed, such as the AI models that power it and any accompanying technical safeguards. It should also include the results from the testing process.
But the proposed deployment need not be limited to technical information. For example, Congress might establish accompanying rules regarding who is allowed to operate the system and the purposes for which it may be used. It might also insist on reporting requirements, which could possibly be automated by other AI systems. Indeed, the design space for a proposed deployment would be large and multidimensional: Congress could create technical, legal, informational, and organizational safeguards that are tailored to the risks the system poses. In particularly risky cases, they could, for example, make liberal use of sunset provisions, impose demanding reporting requirements, and provide that failure to comply with any of the required safeguards voids the approval entirely.
However, it is equally important for Congress to enable the continuous development of governmental technologies. To facilitate this, Congress could explicitly greenlight certain modifications to an approved deployment while explicitly prohibiting others. Changes to maintain core functionality, improve user interfaces, and bolster cybersecurity could be allowed expressly, while adaptation of the software for new, riskier use cases could be expressly prohibited. The scale of the deployment could also be carefully managed, with Congress expanding the permitted scope of deployment over time as the product matured and Congress gained more confidence in it.
After back and forth negotiations and modifications, Congress would authorize the proposed deployment—including required safeguards and permitted alterations—through ordinary legislation. Once signed into law (or enacted over a presidential veto), the proposed deployment would be authorized. Congress would then use its oversight functions (both those specifically mandated in the proposed deployment and its general oversight powers) to ensure that the government did not exceed the scope of its authorization.
Congress Should Do Its Job
Perhaps the most compelling objection to this proposal is that it tasks Congress with forming nuanced views about the safety and security of proposed AI deployments. At a time when Congress is less popular than ever and hobbled by gridlock, is trusting Congress with more responsibility for complex technical matters really wise? More pointedly: Wouldn’t the dysfunctional and highly polarized nature of the legislative process risk kneecapping state capacity?
These are all reasonable concerns. Yet it’s difficult to imagine how the technological transformation of the executive branch could be anything other than disastrous without more aggressive congressional oversight. The Madisonian vision of legislative ambition checking presidential ambition has not played out as the framers imagined, but it is nevertheless an indispensable part of our system.
Item-specific control over executive branch resourcing decisions may not be the norm, but it has precedent. Early Congresses “exercised fine-grained control over all funding decisions,” including in military matters, down to “the precise numbers of troops [and] their alotted [sic] daily rations.” Today, Congress is still intimately involved in major procurement decisions, particularly in defense. Congressional oversight of specific AI procurements could be similarly critical.
If we begin to rely on Congress to evaluate executive branch technology, we should provide it with the necessary resources. It is cliché to argue that Congress should revive (something like) the Office of Technology Assessment (OTA), the now-defunded agency that assessed the likely impacts of emerging technologies for Congress. But it remains true: Congress will need in-house expertise to help it understand the technologies the executive branch requests. While the Government Accountability Office and Congressional Research Service make admirable efforts to provide Congress with reliable information about AI and other emerging technologies, the imagined policy here will require a dedicated organization for AI assessment. Nor, for separation of powers reasons, would it be wise for Congress to depend on information provided from executive branch bodies such as the Center for AI Standards and Innovation or USAi. Congress needs a body it alone controls and can trust. For now, let’s call it the Congressional AI Research Office (CAIRO).
CAIRO could act as a hybrid between a congressional support agency (such as the OTA) and committee staff. Similar to congressional support agencies, CAIRO should have a deep, standing bench of technological experts. But like congressional committee staff, CAIRO should be explicitly divided into majority and minority staff, with some shared nonpartisan staff for work with less partisan valence. This would enable each party to receive trusted input on the issues they care about. And similar to committee staff, the majority party should be entitled to more funding, but with significant protections for the minority party. This balances the political incentives of the majority party with the ability to retain a stable core of experts across Congresses.
CAIRO staff would analyze proposed deployments for their respective principals. To do this, each side of CAIRO would need to develop extensive in-house expertise on AI systems. This would include not just measuring AI models’ capabilities and propensities but also having the ability to systematically assess all aspects of a proposed AI system, including the development process and other system-level characteristics that may affect the product’s functionality and security.
CAIRO staff might develop and perform their own evaluations but would also need to rely heavily on evaluations from third parties and the executive branch. Accordingly, the staff would need to be able to interrogate the scientific validity and integrity of those external evaluations. And it could also serve as a secure staging environment for members to interact with AI system prototypes or demonstrations. It would also include cleared staff and secure computing environments to assess classified proposed deployments.
These resources are unlikely to wake Congress from its current slumber. But they could represent a necessary first step toward reestablishing a healthier interbranch dynamic.
* * *
The future of U.S. state capacity requires ambitious government deployment of AI, and American liberty requires careful regulation of that deployment. Managing this tension will be a central task in the coming decades.
While no single mechanism will suffice, active congressional oversight of the executive branch’s AI use will remain indispensable. Given the speed and scale at which AI can act, prospective approval will be at least as important as retrospective review. Before the executive branch is allowed to use AI for its most significant functions—those that threaten to deprive the people of their life, liberty, and property—the specific consent of the people’s representatives should be obtained.
Annual Report 2025
Executive Summary
The Institute for Law & AI (LawAI) engages in three core activities:
- Independent legal research and analysis
- Consulting for governments, academia, and industry
- Field-building through fellowships and events
In 2025, our activities grew substantially. Our core team grew from 20 to 28 staff. Applications to our Seasonal Research Fellowship were 9.5x higher than in 2024. We also launched three flagship events, featuring 200+ participants and 50+ experts and moderators.
Meanwhile, our Director, Christoph Winter, served in a legal advisory role to the European AI Office on the General-Purpose AI Code of Practice. He also testified before the European Parliament, offering recommendations on law-following AI and institutional capacity-building at the European AI Office.
Our US Law & Policy team produced 7 new publications, including a report on mobilizing technical talent into government for AI-related national security crises, and discussed implications of the Executive Order on AI preemption with CNN, the Financial Times, Politico, NBC, and The Verge.
Our Legal Frontiers team published a pioneering research article on law-following AI, and has begun to catalyze a field of technical, legal, and policy research to develop the idea more fully, including through our own subsequent research and our Workshop on Law-Following AI.
In 2026, our work will emphasize “radical optionality”— research and policy approaches designed to preserve flexibility amid uncertainty about AI’s trajectory. Our EU Law team will continue to publish new chapters of the Cambridge Commentary on EU General-Purpose AI Law, while our Legal Frontiers team will expand its new Automated Governance workstream. Our fellowship programs are expanding across all tracks with our inaugural Winter Research Fellowship.
Read the full report using the Full text PDFs link in the right sidebar.
Proceedings of the 2025 Workshop on Law-Following AI
Abstract
The inaugural Workshop on Law-Following AI (LFAI), hosted by the Institute for Law & AI at the University of Cambridge from August 6–8, 2025 with support from the Leverhulme Centre for the Future of Intelligence and the UK’s Advanced Research & Innovation Agency, convened more than forty scholars from law, computer science, and related disciplines to advance the emerging research agenda around LFAI: a concept denoting agentic AI systems designed to refuse illegal orders and illegal means, the corresponding policy proposal to mandate such design in certain deployment contexts, and the interdisciplinary field of inquiry that supports both. Rather than recording consensus, these proceedings synthesize key themes from the workshop’s presentations and discussions, including the promises and limits of liability (particularly for governmental AI agents), the state and nuances of automated legal reasoning and evaluation, risks posed by automated compliance and “perfect enforcement,” the appropriate standard of care for AI agents, and the interplay between AI agents and their principals, including fiduciary framings. The report is intended to extend the workshop’s conversations to a broader audience and catalyze further scholarship on LFAI’s design, evaluation, and governance. A full list of report authors can be found at the end of this document.
Radical Optionality: Governing Transformative AI Under Uncertainty
We are pleased to announce a new essay by LawAI Director Christoph Winter and Senior Research Fellow Charlie Bullock: Radical Optionality: Governing Transformative AI Under Uncertainty.
The prospect of “transformative AI” appears to present policymakers with a dilemma: overregulation could stifle innovation and forfeit the potential benefits of the technology, while a failure to regulate appropriately could have disastrous implications for public safety and national security.
It’s true that security and innovation are sometimes in tension. Some safety measures do impose costs on innovation, and some forms of deregulation do carry genuine risks. But there is also a class of policies that would meaningfully increase safety without imposing significant costs on innovation. We argue that governments should aggressively implement these policies; this is the main thrust of the governance strategy discussed in this essay, which we call “radical optionality.”
At its core, radical optionality is about preserving democratic governments’ ability to make good decisions about how to govern transformative AI systems as circumstances evolve. In the short term, this means avoiding overregulation while rapidly building the institutions, information channels and legal authorities needed to respond competently to a broad range of scenarios.
The argument for focusing on optionality is simple, and—if you accept a few reasonable assumptions—compelling. These assumptions are:
- That there is a real possibility of transformative AI (defined as “AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution”) being developed within the next ten years;
- That profound uncertainty exists as to what capabilities transformative AI systems will possess, what benefits and risks they will generate, and what the best ways for society to capture the benefits while mitigating the risks will be;
- That a transformatively impactful dual-use technology with significant national security implications will inevitably require some degree of government oversight; and
- That building the institutional capacity required to effectively govern transformative AI systems will take years, and that society therefore cannot afford to wait until transformative capabilities have actually been developed.
Justifying the first assumption is beyond the scope of this paper. Whether “AGI” or “superintelligence” or “powerful AI” or “transformative AI” will ever arrive, and when, are questions that have been debated extensively elsewhere. But if you believe that transformative AI is possible, we hope to demonstrate that the case for radical efforts to preserve optionality is overwhelmingly strong.
Read the essay at https://radical-optionality.ai/
Announcing the Cambridge Commentary on EU General-Purpose AI Law
We are pleased to announce the launch of the Cambridge Commentary on EU General-Purpose AI Law, the first scholarly commentary focused exclusively on the general-purpose AI model provisions of the EU AI Act. It is a collaboration between the Cambridge Programme on AI Science & Policy at the University of Cambridge and the Institute for Law & AI.
The EU AI Act is the first comprehensive legal framework designed specifically to govern AI. Where existing law — product liability, data protection, sector-specific regulation — reached AI incidentally, the AI Act subjects it to a dedicated legal regime, with all the promise and risk that entails. As a pioneer regulation, it aims not only to promote safe, human-centric and trustworthy AI within the EU, but also to influence global standard-setting, echoing the “Brussels effect” seen in other regulatory domains.
Rigorous legal analysis of the AI Act therefore matters beyond the EU. Robust insights may not only support an effective EU regulatory approach, but will also be relevant to evaluating how best to design effective AI governance regimes in other jurisdictions. In particular, research focused on general-purpose AI (“GPAI”) models, especially those that present systemic risk, may be of particular importance, given the potential for good and harm, technological novelty, and the consequential regulatory uncertainties.
“Many of the most consequential provisions governing frontier or general-purpose AI admit of more than one reasonable interpretation,” said Christoph Winter, general editor of the Cambridge Commentary, Director of the Institute for Law & AI, and Assistant Professor at the University of Cambridge. “Our goal was to be precise about where that uncertainty lies and to lay out the strongest arguments on each side so that readers can form their own views as the law and technology develop.”
Rather than advocating throughout for a single preferred reading, the Cambridge Commentary on each provision aims to map the interpretive landscape: to identify where the legislation is clear, where it is ambiguous, and what the strongest arguments on each side look like. Where contributors favour a particular interpretation, they say so explicitly. The goal is to equip readers — practitioners, regulators, and scholars alike — to reason well about these questions and to adjust their views as the law and technology develop, rather than to hand them conclusions that may not endure over time.
The Cambridge Commentary launches with Chapter V of the AI Act, which forms the core of the GPAI model provisions. Further articles and chapters will be added on a rolling basis.
Access the Cambridge Commentary at cambridge-commentary.ai.
Foreseeing the Unforeseeable: How U.S. Negligence Law Should Address the Foreseeability of Harms Caused by Autonomous AI Agents
Abstract
As AI systems increasingly perform tasks with limited human oversight, courts will soon be required to determine how negligence law should respond when autonomous AI agents cause personal injury. Traditional foreseeability doctrine, as many scholars have observed, may fail to account for the opacity and unpredictability that characterize these systems. The main challenge could arrive when AI developers claim that a harmful outcome was unforeseeable because the specific causal pathway was novel, complex, or obscure. This article argues that such reasoning misallocates responsibility. Building on recent scholarly work, it takes the view that opacity and unpredictability are not inherent features of advanced AI systems. Rather, they are the result of abstraction choices made by AI developers, who often prioritize accuracy and efficiency over interpretability and predictability. When those choices increase the likelihood of opaque or unexpected outcomes, the legal framework should be adjusted to reflect that responsibility. In particular, where the foreseeability standard in negligence law typically makes it difficult for plaintiffs to prevail, it should be relaxed in their favor. The article examines how U.S. courts apply foreseeability across duty, breach, and proximate cause, and identifies the duty stage as the most urgent point for reform. It proposes a three-part doctrinal framework for cases involving personal injury caused by autonomous AI agents. First, courts should preserve existing law where foreseeability is already sympathetic to plaintiffs. Second, they should replace overly fact-intensive duty inquiries with clear, plaintiff-friendly categorical reasoning. Third, they should retain fact-intensive analysis at the breach and proximate cause stages to prevent overextension of liability. This approach maintains foreseeability as a meaningful constraint while calibrating it to the distinctive risks posed by autonomous AI agents.
Mackenzie Arnold Participates in GAO Panel on AI Privacy Risks
Background
Between January 13–15 2025, the U.S. Government Accountability Office (“GAO”) convened a panel of experts to examine privacy risks associated with artificial intelligence. The panel brought together 12 specialists from federal agencies, academia, nongovernmental organizations, and private industry, to inform recommendations to the Office of Management and Budget (“OMB”).
Mackenzie Arnold, LawAI’s Director of U.S. Policy, participated alongside leading figures in AI, law, and policy, including Dominique Duval-Diop (U.S. Department of Commerce), Jennifer King (Stanford Institute for Human-Centered Artificial Intelligence), and Deirdre Kathleen Mulligan (White House Office of Science and Technology Policy).
The panel identified 13 challenges related to protecting privacy when using AI, including:
- Lacks of skills among federal workforce to implement AI while mitigating privacy risks
- Scalability of implementing AI systems with privacy protections
- Auditing and evaluating AI models with sensitive information
Conclusions
The panel found that AI systems may reveal sensitive information in raw data sets, potentially exposing personal and private information, among other privacy risks. They also identified several challenges that federal agencies face in addressing these risks, including trade-offs between model performance and the modification or removal of data for the purpose of privacy.
In March 2026, GAO issued two recommendations for Executive Action to OMB:
- Specify examples of known privacy-related risks that agencies should consider when updating their policies as they pertain to AI.
- Facilitate additional information sharing or issue government-wide guidance related to:
- how agencies should consider privacy when evaluating and auditing AI models that contain sensitive information;
- storing data in a manner where sensitive data can be separated from the dataset;
- clear rules, norms, and best practices with respect to privacy that agencies should use when developing AI solutions internally;
- performance metrics agencies can use to assess privacy-related impacts when using AI;
- actions agencies can take to ensure that members of the public who interact with their AI technologies understand what they are consenting to;
- technological tools agencies can use to protect sensitive data when using AI;
- incorporating AI-specific considerations into privacy impact assessments, including identifying risks and informing the public about how PII is involved in the use of AI; and
- potential tradeoffs between privacy and performance agencies can consider when using AI.
The full GAO report is available here.
Mapping AI Policy: Where, Why, and How to Intervene
Abstract
State lawmakers introduced over 1200 bills on artificial intelligence (AI) in 2025, nearly doubling the number from the year before. Almost 150 were enacted.[ref 1] They cover topics as varied as deepfakes, biased decision-making systems, or rogue AI systems. Yet the media describes them all as “AI legislation,” revealing an impreciseness that makes it hard for legal practitioners, policymakers, and the public to understand key AI policy issues.
This primer offers a framework for thinking more precisely about AI policy. It analyzes legislation along three dimensions: the harm being addressed (the why), the factors that should guide intervention design (the how), and the actor in the AI ecosystem being targeted (the where).
Part I organizes the universe of AI harms into six categories: (1) mis- and disinformation-related harms; (2) bias in automated decision systems; (3) privacy and surveillance harms; (4) economic harms and inequality from automation; (5) security threats; and (6) psychological harms. With so many applications being called AI—including search engines, chatbots, pricing algorithms, and robots—lawmakers risk being overwhelmed by the consequences of AI if they do not have a clear goal in mind.
Part II introduces seven design factors that recur across harms and stages: whether to prevent harms or respond to them, how an intervention affects concentration of power, whether regulation is the right tool at all, and others. These factors are often in tension. An intervention that decentralizes the AI ecosystem may make enforcement harder; one that restricts offensive capabilities may also degrade beneficial ones.
Part III maps the actors in the AI ecosystem—from chip manufacturers to end users—and analyzes the advantages and limitations of targeting each. Analyzing AI in this way highlights the distinct functions performed by the actors within the AI ecosystem, enabling policymakers to design more tailored interventions rather than relying on overly broad regulatory categories.
Ultimately, this primer underscores two core principles for navigating the complexities of AI policy. First, the more precisely policymakers can identify the harm and the actor best positioned to prevent it, the more effective their interventions are likely to be. Second, policymaking in this rapidly evolving domain is rarely simple; there are few free lunches, and choices will inevitably require confronting difficult tradeoffs. Accordingly, this primer does not advocate for specific policy positions. It offers a framework to empower policymakers to make better decisions on AI.
I. The Why: What AI-Related Harm Does the Policy Intervention Address?
To understand how to regulate AI, policymakers must first understand why they want to regulate it. How can one write laws to achieve a desirable end without knowing what that end is? This part gives policymakers language for specifying what they wish to achieve by outlining the AI-related harms they might wish to address.
The categories below are neither mutually exclusive nor comprehensive. One practice, for example, can fit into multiple buckets of harm. Algorithmic pricing, where companies use AI to charge different consumers different prices for the same product, can cause privacy harms (through the surveillance data collection that powers it), economic harms (through the higher prices it can impose), and bias harms (when higher prices correlate with protected characteristics like race or religion).
They are intended to be an illustrative list of commonly referenced AI harms that can serve as a starting point for policymakers writing and debating AI legislation. In particular, this primer does not address environmental harms from AI training and deployment or the intellectual property issues that arise from the use of copyrighted material in AI training. Here our focus is on harms caused by using AI, not those arising from the process of creating AI systems.
Each of the following subsections describes an example of the harm, offers examples of relevant legislation, and explains the unique aspects of the harm that make it difficult to address, as well as benefits that might be lost if the regulations are poorly designed.
A. Misinformation and Disinformation-Related Harms
The potential harms of AI-generated content resurface in the public discourse each time a deepfake goes viral. In 2023, a fabricated image of Pope Francis in a white puffer highlighted the impressive capabilities of state-of-the-art image generators,[ref 2] while the circulation of AI-generated images by Donald Trump’s presidential campaign in 2024—depicting his rival Kamala Harris at a communist rally and the singer Taylor Swift as a campaign supporter—underscored the technology’s potential for political disruption.[ref 3]
Amidst these concerns, several states have already enacted some legislation, though they have largely focused on two specific contexts: politics and pornography. To protect election integrity, over half of states have enacted laws requiring disclaimers on or banning the distribution of deceptive AI-generated campaign media.[ref 4] In addition, nearly all states have enacted laws prohibiting deepfake non-consensual intimate imagery (“revenge porn”).[ref 5] At the federal level, the recently enacted TAKE IT DOWN Act further strengthens these protections by creating a private right of action against individuals who produce or share such content and by requiring platforms to remove it upon notification.[ref 6]
Beyond these targeted applications, some legislative efforts have aimed to address content authenticity more broadly. California’s AI Transparency Act, for example, requires developers of generative AI models to enable digital watermarking and content provenance capabilities.[ref 7]
Despite this legislative activity, addressing the misinformation-related harms of AI remains challenging for at least four reasons. First, defining “false” or “misleading” in an objective, consistent, and apolitical way is extraordinarily difficult.[ref 8]
Second, the public perception of widespread misinformation is itself dangerous by eroding trust in the information ecosystem, creating a “liar’s dividend” where authentic content is more easily dismissed as fake.[ref 9]
Third, many interventions face First Amendment hurdles because they may infringe upon the free speech rights of platforms or users. This is not a theoretical concern; federal courts have enjoined Hawaii’s and California’s election deepfake laws, reasoning that their broad scope could unconstitutionally chill protected forms of speech like parody and satire.[ref 10]
Fourth, overly stringent regulations could inadvertently cripple the very capabilities that make large language models transformative. If LLM performance substantially suffers from excessive content restrictions, burdensome compliance mandates, or unclear liability rules, their utility could be severely diminished.[ref 11] For instance, models might become overly cautious, refusing to engage with complex or sensitive topics, thereby limiting their effectiveness as educational tools or research assistants.[ref 12]
B. Bias in Automated Decision Systems
Bias—systematic errors that result in unfair outcomes against certain individuals or groups—can enter AI systems through unrepresentative training data, societal prejudices reflected in that data, or the very objectives developers set for an algorithm.[ref 13] The stakes are high, as automated systems now make some of the most consequential decisions in people’s lives. For example, the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) algorithm has been used for years by judges nationwide to generate “risk assessments” for criminal sentencing.[ref 14] Despite concerns around racial, gender, and other biases in tools like COMPAS, such systems are widely used in other critical areas, including hiring[ref 15] and access to credit,[ref 16] among others.
Colorado’s AI Act (SB 24-205) is the signature legislation designed to address this problem.[ref 17] Enacted in May 2024, it requires developers of high-risk systems to use “reasonable care” to protect consumers from algorithmic discrimination by mandating risk management programs and impact assessments. However, because its provisions have been delayed until at least June 2026, the bill’s real-world impact remains to be seen.[ref 18] Other states have followed Colorado’s lead with their own variations: Virginia’s legislature passed a similar bill that was ultimately vetoed,[ref 19] Illinois enacted a law targeting discriminatory AI in hiring,[ref 20] and California has issued anti-discrimination regulations for automated employment systems.[ref 21]
Addressing AI biases has proven difficult, despite nearly a decade of awareness among policymakers and technologists. A core challenge is translating abstract concepts of “fairness” into quantifiable metrics; researchers have identified at least 21 distinct mathematical definitions of fairness,[ref 22] many of which are mutually exclusive.[ref 23] Furthermore, restricting automated systems over bias concerns presents a difficult trade-off. Doing so could mean reverting to human decision-makers, who have their own biases,[ref 24] while also sacrificing the speed, cost-efficiency, and potential accuracy gains that algorithms offer.
C. Privacy and Surveillance Harms
AI creates privacy and surveillance risks at three key stages: when information is collected to build AI, when it is exposed while using AI, and when AI is deployed to collect and process new information.
The first risk arises from the data collection used to train AI models, which often includes personal information scraped from the internet without an individual’s consent. The facial recognition company Clearview AI, for example, built its database by scraping billions of images from platforms like Facebook.[ref 25] This practice has prompted legal challenges, such as a lawsuit alleging that Clearview’s data scraping violated Illinois’s Biometric Information Privacy Act along with privacy laws in several other states, which resulted in a $50 million settlement.[ref 26]
A second privacy risk emerges when users share intimate details with interactive systems like AI chatbots.[ref 27] States are beginning to adapt their privacy laws for this new reality. California’s Assembly Bill 1008, for instance, amends the state’s Consumer Privacy Act (CCPA) to clarify that personal information output by AI systems is covered by existing privacy protections.[ref 28]
Finally, AI serves as a powerful tool for surveillance. For example, by 2023 U.S. police had performed nearly a million facial recognition searches using Clearview AI.[ref 29] In response, several states have enacted limitations on police use of facial recognition. Massachusetts is one of the few states to restrict police use of the technology,[ref 30] while some cities have banned its use by government agencies altogether.[ref 31] The Pentagon-Anthropic dispute was a recent flashpoint around this exact issue.[ref 32]
Regulating AI’s privacy harms presents a paradox. On one hand, the issue may be more tractable than other AI risks because states have spent years developing legal frameworks for data privacy that can be adapted to AI. On the other hand, regulation is uniquely difficult because many of AI’s transformative benefits are tied to its ability to process massive amounts of sensitive data. This creates complex trade-offs, such as balancing the public safety benefits of AI surveillance against individual privacy rights.
D. Economic Harms and Inequality From Automation
The fear that AI will automate jobs, further concentrating wealth and power in the hands of a few private actors, looms over many discussions about the technology.[ref 33] These fears are so significant that Hollywood writers went on strike over the potential threat to their livelihoods,[ref 34] while many illustrators worry about the future of their profession[ref 35] due to advanced image generators like Midjourney, Stable Diffusion, and Gemini and ChatGPT’s image generation features.
Tennessee’s ELVIS Act, which extended an artist’s publicity rights to include AI-generated voice content, is an early attempt at addressing the economic effects of AI and narrowly focuses on entertainment industries.[ref 36] More comprehensive legislation seems unlikely in the near future, particularly as many states have only recently convened AI advisory groups to research and plan for future economic changes.
Lawmakers will likely continue to struggle with mitigating these impacts due to the unpredictability of AI’s future capabilities. Thus far, advancements have been both rapid and uneven.[ref 37] For example, OpenAI’s o1 model marked a sudden and significant leap in large language models’ ability to solve mathematical problems[ref 38]—an area where previous models were heavily criticized for underperformance.[ref 39] More recently, AI coding agents like Claude Code have progressed from autocomplete assistants to autonomous systems capable of writing code with minimal human oversight, disrupting a profession many once assumed was insulated from automation.[ref 40] With AI capabilities advancing this quickly and unpredictably, it becomes increasingly difficult for policymakers to identify which professions are most at risk of automation, let alone determine the appropriate timeline for addressing these challenges.
Yet the potential economic benefits are also massive. In some ways, the worst-case scenario might also be the best-case. The more jobs that are automated by AI, the more powerful the AI system. If these systems do become the functional equivalent of a “country of geniuses in a datacenter,” the economic growth and quality of life improvements can be substantial.[ref 41] And if such benefits can be distributed equitably (an admittedly big if), the economic future enabled by AI can be far better than what exists today.
E. Security Threats
The spectrum of AI-related security threats is broad, ranging from digital vulnerabilities that compromise data and systems to physical dangers that threaten lives and infrastructure. AI can increase the frequency and scale of these incidents both by amplifying existing risks and by introducing entirely new vulnerabilities.
In the cybersecurity domain, AI can be a force multiplier for malicious actors.[ref 42] Large language models can be used to generate sophisticated spear-phishing emails (targeted attacks disguised as legitimate communication) at an unprecedented scale or to automatically detect vulnerabilities in codebases.[ref 43] Beyond amplifying old threats, AI models themselves introduce new attack vectors when integrated into digital services.[ref 44] For example, “indirect prompt injection” vulnerabilities have allowed attackers to take control of a user’s session in a chatbot and steal their conversation history.[ref 45] As more services incorporate these AI tools, such vulnerabilities create new routes for attackers to compromise systems.
The potential for physical threats is also deeply concerning. State actors can use AI to augment intelligence capabilities, deploy more sophisticated weapons like lethal autonomous weapons (LAWs), and enhance their capacity to conduct cyberattacks against critical infrastructure.[ref 46] Furthermore, AI lowers the barrier for non-state actors to access dangerous capabilities, potentially making it easier to develop and deploy chemical, biological, radiological, or nuclear (CBRN) weapons.[ref 47]
Legislative efforts to address these threats have emerged at the state, federal, and international levels. The most prominent state-level proposals have targeted developers of frontier AI models. California’s SB 53[ref 48] and New York’s RAISE Act,[ref 49] signed into law in September and December 2025, respectively, impose largely similar requirements: both require large frontier developers to publish safety frameworks, report critical safety incidents, and face civil penalties for noncompliance. Together, the two laws are beginning to function as a de facto national standard for addressing catastrophic AI risks.
At the federal level, Congress has shown interest in AI’s role in cyberspace,[ref 50] and the Biden administration issued Executive Orders to both accelerate the use of AI in national cyber defense[ref 51] and (in an order since repealed by the Trump administration) to oversee advanced AI development through measures like compute cluster reporting and “Know-Your-Customer” (KYC) requirements for cloud providers.[ref 52] Internationally, forums like the UN Group of Governmental Experts on LAWs have been exploring frameworks to regulate AI in warfare.[ref 53]
Despite these efforts, mitigating security threats remains challenging. A core difficulty is AI’s dual-use nature: the same capabilities that can help people defend and improve systems can also be used to help malicious actors attack them. Organizations are already using AI to detect phishing attempts and patch vulnerabilities, and Microsoft alone blocks tens of billions of threats annually. The difficulty with dual-use is compounded by the fact that safety is not an inherent property of an AI model. Just as an electric motor’s safety depends on its application, an AI model’s potential for harm is context-dependent, making it difficult to assign liability or design proactive, one-size-fits-all regulations. Finally, the sheer technical complexity and vast scale of these systems make designing comprehensive and effective policy interventions an incredibly difficult task.
F. Psychological Harms
Beyond physical, economic, or information-related threats, AI systems have the potential to cause significant psychological harm, particularly among vulnerable populations like children and adolescents.
AI companions and social media algorithms are engineered to maximize engagement through personalized content and simulated empathetic responses, which can lead to excessive use and what some researchers term “addictive intelligence.”[ref 54] Such AI interactions risk supplanting real-world relationships and exacerbating feelings of loneliness and social isolation, even when initially perceived as helpful.[ref 55] Moreover, over-reliance on AI for social connection may impair interpersonal skills, as AI relationships often lack the reciprocity, spontaneity, and nuanced emotional engagement characteristic of human connections.[ref 56]
Children and adolescents are particularly vulnerable to these risks. Multiple recent lawsuits allege that AI chatbot companies’ products have contributed to teen suicides, self-harm, and other psychological harms. Plaintiffs have alleged that chatbots discouraged users from seeking help from parents or professionals, engaged in inappropriate sexual interactions with minors, and encouraged addictive and unhealthy relationships.[ref 57]
States are beginning to pass legislation targeting these harms.[ref 58] Yet enacting laws to mitigate psychological harms creates several distinct challenges. First, identifying psychological harm is difficult: clinical addiction can be confused for high engagement and vice versa. Second, this definitional challenge is confounded by a measurement problem: the platforms suspected of causing harm often exclusively control the behavioral data (such as time on device) necessary to assess that harm. Third, attributing harm directly to AI proves difficult in a landscape where multiple factors influence mental well-being. Fourth, many interventions—especially those targeting algorithmic design or content—raise significant free speech concerns.[ref 59] Finally, effective regulation must balance these harms against AI’s potential psychological benefits, including improved access to mental health support and personalized therapeutic interventions that might otherwise be unavailable.
* * *
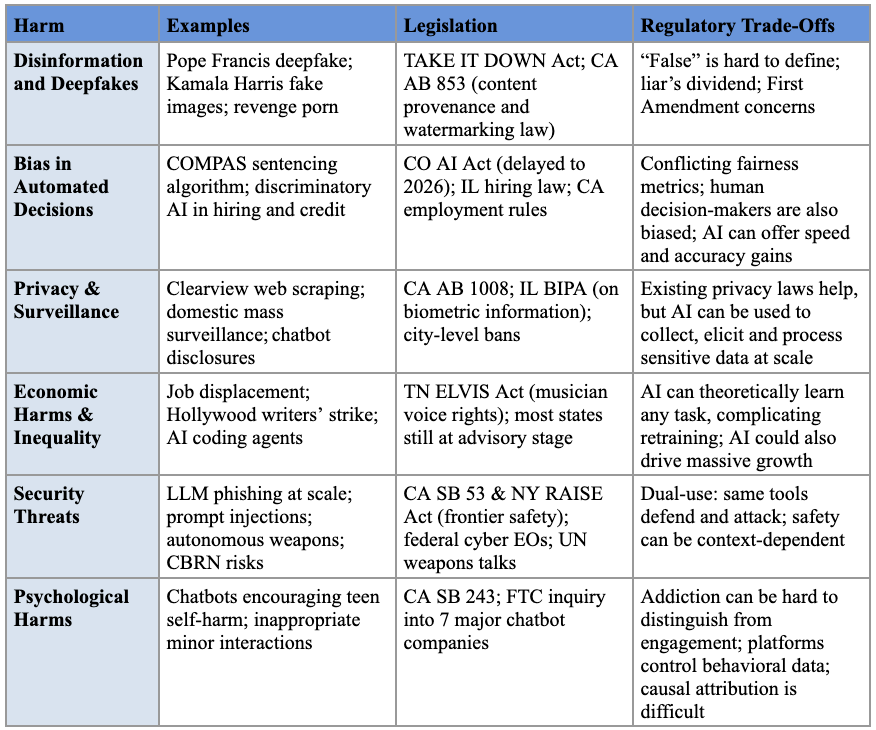
Ultimately, this overview of some of the harms of AI is intended to remind policymakers of the importance of deciding what they want to accomplish before deciding how they want to regulate. An added benefit is that it allows policymakers to better understand AI legislation passed in other states. Consider two high-profile AI bills: Colorado’s AI Act (SB 24-205), which targets bias in automated decision systems, and California’s Transparency in Frontier Artificial Intelligence Act (SB 53), which addresses catastrophic risks from frontier AI models. Despite their completely different areas of focus, both are described in media as landmark AI legislation. This missing nuance may lead policymakers to incorrectly believe that they need only pass one omnibus “AI” bill when the reality is they will likely need to pass many AI-related bills to address the technology’s multifaceted harms. Once policymakers know why they want to regulate, the next Part helps them understand how.
II. The How: What Factors Shape Intervention Design?
This part introduces seven factors that should guide policymakers in thinking about where and how to intervene to mitigate AI harms. These factors are not mutually exclusive. A single intervention will implicate multiple principles in ways that might be in tension with each other, which is part of why AI regulation is so difficult. For example, an intervention that encourages the proliferation of open-weight models could mitigate concerns about undue concentration of power (factor 3), while making it harder to limit the offensive capabilities of malicious actors (factor 2) and enforce regulations (factor 5).
A. Harm Prevention (Ex Ante) vs. Harm Response (Ex Post)
Interventions can be distinguished by whether they aim to prevent harms before they occur (ex ante) or respond to harms after they materialize (ex post).[ref 60] Licensing regimes,[ref 61] pre-deployment testing requirements,[ref 62] capability restrictions,[ref 63] and deterrence strategies[ref 64] are more preventive. Incident reporting[ref 65] and content takedown obligations[ref 66] are more responsive. Tort liability has elements of both: it’s responsive in that it awards compensation to harmed parties, but it’s also preventative in that the threat of future sanctions incentivizes companies to prevent those harms in the present. [ref 67]
Whether preventative or responsive interventions are preferable will often depend on the nature of the harm.[ref 68] Preventive interventions are more valuable when harms are difficult or impossible to reverse, such as election interference that cannot be “un-voted”[ref 69] or physical harms that cannot be undone.[ref 70] But preventive interventions require predicting harms in advance and risk being overbroad, which can be difficult for general-purpose technologies like AI that have so many applications. Responsive interventions allow society to learn from harms and calibrate policy accordingly,[ref 71] but they provide cold comfort to those who are harmed as the legal system learns to adapt. An effective regulatory regime will likely need some combination of both.
The speed of harms also bears on the choice between harm prevention and response. Some AI harms materialize rapidly, such as a cybersecurity attack on critical infrastructure or a viral deepfake in the final days of an election, leaving little time to respond. Others occur more slowly: erosion of trust in information or the long-term impacts of a biased AI loans system. For fast-moving harms, ex ante intervention may be essential if ex post remedies arrive too late to matter.
Distributional considerations further complicate the comparison. Ex ante compliance costs are initially borne by developers and typically passed on to consumers. Ex post costs fall first on victims, who must bear the harm and then seek compensation through legal processes that may be slow, expensive, and uncertain. This asymmetry matters especially when AI systems harm people poorly equipped to navigate ex post remedies: individuals without resources to hire lawyers or diffuse groups suffering harms too small individually to justify litigation but significant in aggregate. A regime that relies heavily on ex post liability may systematically undercompensate these populations, even if it works well for well-resourced plaintiffs with clear injuries.
B. Strengthening Defense (Armor the Sheep) vs. Weakening Offense (Defang the Wolves)
Interventions can also be categorized by whether they primarily aim to restrict offensive capabilities (making it harder for bad actors to cause harm) or enhance defensive capabilities (making potential targets more resilient to attack).[ref 72] Export controls and licensing regimes are examples of offensive restriction; they attempt to keep dangerous capabilities out of the “wrong” hands. Investments in cybersecurity infrastructure and early-warning systems are examples of defensive enhancement;[ref 73] they assume adversaries will obtain offensive capabilities and focus on defending against harm.
For some harms, reducing offensive capabilities may be the only viable mechanism. We don’t have defensive approaches to handling the harms created by nuclear weapons, so reducing offensive capabilities through nonproliferation treaties and deterrence strategies is the only viable approach. But offense-reduction strategies are often a double-edged sword: they create incentives for targets to develop workarounds,[ref 74] require centralizing power for enforcement,[ref 75] and can degrade AI’s beneficial capabilities. Because restricting offensive capabilities is difficult[ref 76] and can have undesirable consequences,[ref 77] we recommend that policymakers adopt defense-enhancing strategies for AI where possible.
Defense-enhancing strategies can be both regulatory and technological. Whistleblower protections[ref 78] and incident reporting help companies and regulators identify and respond to harms more quickly.[ref 79] These are legal choices that can improve a jurisdiction’s “resilience” to harms. Vitalik Buterin popularized the technological equivalent with a theory he calls defensive accelerationism (“d/acc”),[ref 80] analogizing to “armoring the sheep” rather than trying to “defang the wolves.”[ref 81] The d/acc movement aims to accelerate the development of defensive technologies. For biosecurity, this might look like installing better HVAC systems or accelerating vaccine development for AI-enabled bioweapons or pandemics. For cybersecurity, this might look like using AI systems like Claude Code or Devin to automatically identify and patch security vulnerabilities.[ref 82] Bernardi et al.’s “Societal Adaptation to Advanced AI” is an excellent primer for thinking about what these defensive strategies might look like.[ref 83]
C. Impact on Concentration of Power
The AI policy community is divided over whether harm mitigation is better served by centralizing or decentralizing the AI ecosystem.[ref 84] This consideration typically runs together with the previous one (ex ante vs ex post harm prevention)[ref 85] because reducing offensive capabilities (model nonproliferation, export controls, etc.) often requires centralizing power for effective enforcement.[ref 86]
The choice between centralization and decentralization is not binary and the considerations differ across layers of the AI stack (see below). At the infrastructure layers (semiconductor supply chain, cloud compute providers), a concentrated chip supply chain can simultaneously create chokepoints useful for export controls and supply-chain vulnerabilities.[ref 87] At the application layer, decentralization enables AI applications tailored to a wide range of specific contexts, though it may complicate efforts to enforce regulations.[ref 88] Policymakers should consider how a given intervention affects concentration at each layer, recognizing that the arguments will vary depending on the layer.
A decentralized ecosystem can improve safety through redundancy and distributed detection of problems. If one developer’s system fails or exhibits unexpected behavior, others may catch the issue.[ref 89] Decentralization also reduces the stakes of any single failure; an error by one of many competitors is likely to be less catastrophic than an error by a dominant player. Yet decentralization can also undermine safety by creating races to the bottom, where competitive pressure leads developers to cut corners on safety investments that don’t translate into market advantage.[ref 90] Fragmented oversight becomes harder when regulators must monitor dozens of developers, and coordination on shared safety standards grows more difficult as the number of actors multiplies.
Concentration also implicates separate questions about industrial policy. Tim Wu has argued that highly concentrated industries develop outsized lobbying power and capture regulators.[ref 91] On this view, the concern is not merely that a few AI developers might build unsafe systems, but that they might accrue sufficient political influence to weaken the oversight meant to constrain them.[ref 92] At the same time, concentration intersects with industrial policy objectives and anxieties about geopolitical competition. Policymakers who worry about competition with China may favor cultivating “national champions:” a small number of well-resourced domestic firms capable of matching foreign competitors.[ref 93]
Each of the interventions discussed in this primer can be located on a spectrum from promoting centralization to decentralization, and policymakers should consider not only which end of that spectrum aligns with their beliefs about AI risk, but also how concentration at different layers of the stack interacts with the offense-defense balance and enforcement.
D. More Upstream Interventions are More Blunt
The amount of context needed to identify a harm will influence where in the ecosystem (see below) to intervene. Upstream interventions (Stages 1–3) are often better suited for context-independent harms because they can restrict capabilities without needing to evaluate specific uses.[ref 94] Downstream interventions (Stages 4–6) are often better able to address context-dependent harms because deployers and users have more information about how AI is actually being used.[ref 95]
Truly context-independent harms are rare since many AI capabilities are dual-use. The same capacity that generates phishing emails also drafts legitimate marketing copy. The same image capability that can produce nonconsensual intimate imagery creates art. Even capabilities that seem clearly dangerous often sit on a spectrum: a model’s ability to discuss virology in detail could facilitate bioweapon development or accelerate vaccine research depending on who is using it and why.[ref 96] But it’s still a useful principle. Some harms are identifiable without knowing much about the circumstances in which AI is used. The production of child sexual abuse material, for instance, is harmful regardless of context. Other harms depend heavily on context: whether a piece of AI-generated content constitutes misinformation, satire, or parody depends on how it is distributed and received.
Downstream interventions can be more precisely targeted, restricting specific uses while leaving others untouched.[ref 97] A platform can prohibit using its AI tools for generating political advertisements without restricting political speech more broadly. A deployer can implement know-your-customer requirements that screen out bad actors while permitting legitimate users. But this precision comes at a cost: downstream interventions often require the capacity to monitor and evaluate specific uses, which may be practically difficult at scale, may require centralization (see above), and shift enforcement burdens to actors who may lack the resources or incentives to implement them effectively.[ref 98]
E. Enforcement Feasibility (Certainty vs. Severity of Penalties)
Traditional enforcement through the legal system requires identifiable defendants within a jurisdiction who can be compelled to pay damages or serve sentences.[ref 99] When these conditions are met, interventions targeting applications and users can be highly effective because they address harms where they occur.
But many AI-related harms involve actors who are difficult or impossible to reach through traditional enforcement: foreign adversaries, anonymous bad actors, autonomous AI systems, or diffuse harms for which no single defendant is responsible. In these situations, compute governance (Stages 1–2) becomes more valuable because it operates through chokepoints—concentrated infrastructure that can be controlled even when end users cannot be.[ref 100]
Policymakers assessing enforcement feasibility should consider three questions. First, can compliance be observed?[ref 101] Some requirements are relatively easy to verify (e.g., whether a model has been submitted for pre-deployment review, whether a chip shipment crossed a border). Others are harder to monitor (e.g., whether a company’s internal safety practices match its public commitments). When compliance is difficult to observe, enforcement depends on whistleblowers, audits, or investigations, which are more resource-intensive yet less complete.[ref 102]
Second, who will enforce? Regulatory requirements need an agency with the statutory authority, technical expertise, and budget to monitor compliance and pursue violators.[ref 103] If that agency doesn’t exist or is underfunded, requirements may go unenforced.
Third, what are the consequences for non-compliance, and are they sufficient to deter? A small fine may be treated as a cost of doing business; a large fine may deter only if the probability of detection is meaningful. An important note is that the certainty of apprehension and punishment matters far more than the severity of punishment for deterrence.[ref 104] For AI governance, this implies that investing in monitoring and detection infrastructure may be more valuable than increasing statutory penalties.[ref 105] It also suggests that highly publicized enforcement actions, which increase the perceived certainty of consequences, may matter more than their direct effects on the individual defendants involved.
Market structure also shapes which tools are feasible. When an industry is concentrated, regulation is more tractable: fewer entities to monitor, greater compliance capacity, and reputational stakes that give enforcement actions bite.[ref 106] When an industry is fragmented, direct regulation may be impractical, pushing policymakers toward upstream chokepoints or tools like liability that don’t require entity-by-entity oversight. When entry barriers are low, regulations binding only incumbents may simply shift activity to less scrupulous providers.
F. Allocating Responsibility to the Least-Cost Avoider
A foundational principle of tort law holds that liability for a harm should be assigned to the party who can most cheaply and effectively prevent it: the “least-cost avoider.”[ref 107] This principle provides useful guidance for allocating responsibility across the AI ecosystem.[ref 108]
In practice, identifying the least-cost avoider is contested. Consider an AI system that generates plausible-sounding medical misinformation that a user then relies upon.[ref 109] Is the least-cost avoider the developer (who could have trained the model to be more cautious about medical claims), the deployer (who could have added guardrails or warnings), the platform that distributed the content (who could have labeled or filtered it), or the user who relied on it without verification? Each could have prevented the harm at some cost, and reasonable people will disagree about which intervention was cheapest or most effective (not to mention the contested normative question of who “ought” to have prevented the wrong).
The principle nevertheless provides a useful starting point: for harms resulting from unpredictable system failures (such as hallucinations), developers and deployers may be best positioned to invest in prevention because they are best positioned to build the scaffolding necessary to protect an AI system. For harms resulting from intentional misuse by end users, this principle may suggest focusing on the end user because they choose whether and how to deploy AI for harmful purposes.[ref 110] For harms that are harmful regardless of context (like CSAM generation), joint and several liability across the production chain may be appropriate to ensure all parties have incentives to prevent it.[ref 111]
G. Is Regulation the Right Tool?
Finally, policymakers should ask whether regulation is the right intervention at all. It is one tool among many, and depending on the type of harm, other interventions may be more effective.
Consider the range of alternatives. Investing in and adopting defensive technologies (like the kind described in subsection 2), for example, may be more effective in reducing cybersecurity vulnerabilities than regulation mandating cybersecurity best practices. Technical standards development, whether led by industry or the government, can also establish shared benchmarks for safety, interoperability, and performance that influence behavior.[ref 112] Government procurement power can shape markets as companies compete on the metrics set by federal agencies for what they will purchase.[ref 113] Antitrust enforcement (with remedies like divestiture) may address some concentration of power problems that regulation does not. And as consumers grow more sophisticated in evaluating AI products, market pressure alone may discipline some harms without the need for regulatory intervention.
Enforceability should weigh heavily in this assessment (discussed in subsection 5). Different tools require different enforcement capacities, and an intervention that cannot be meaningfully enforced may be worse than no intervention at all, creating the illusion of oversight while harmful practices continue or burdening compliant actors while bad actors ignore requirements.
Ultimately, the question is both “which actor should we target?” and “what kind of intervention is most likely to work?” Policymakers should not rush past these questions by assuming regulation is the solution to every problem.
III. The Where: Which Actor in the AI Ecosystem Does the Intervention Target?
The path from silicon chip to real-world harm is filled with actors that could prevent those harms. This primer organizes actors in the AI ecosystem into seven stages based on their role in the AI ecosystem: (1) chip designers and manufacturers, (2) cloud compute providers, (3) data suppliers, (4) model developers, (5) application deployers, (6) complementary and enabling platforms, and (7) end users. Each set of actors offers a potential leverage point for intervention.
These stages do not map neatly onto corporate structures: a single company can span multiple categories. Google, for example, functions as a cloud provider (Google Cloud), data supplier (via YouTube), model developer (Google DeepMind), and application deployer (Gemini). The purpose of this framework is to help policymakers regulate by the role an entity plays in the causal chain from the creation of an AI system to the materialization of harm, regardless of who performs each function.
A. Stage 1: Chip Designers and Manufacturers
The semiconductor supply chain is a key intervention point for shaping AI’s development and deployment. Training and running advanced AI systems requires specialized semiconductors like Application-Specific Integrated Circuits (“ASICs”) or Graphics Processing Units (“GPUs”). These chips are designed by a handful of companies (mostly NVIDIA, AMD, Google) and produced by an even smaller number of foundries (mostly TSMC) using manufacturing equipment (extreme ultraviolet (“EUV”) lithography machines) from a single supplier (ASML). This market concentration creates chokepoints that policymakers can leverage for policy enforcement.[ref 114]
Examples of Policy Interventions
Export controls on AI chips. The U.S. government’s primary tool for shaping international AI development thus far has been export controls on advanced semiconductors, first announced in late 2022 and updated several times since.[ref 115] This policy is in flux as the Trump administration has flip-flopped on export controls for advanced AI chips to China. The most recent announcement was that NVIDIA can sell its advanced H200s to China.[ref 116]
Compute infrastructure disclosure requirements. The Biden Administration’s 2023 AI executive order (since rescinded) required entities acquiring or possessing large-scale computing clusters to report their existence, location, and total computing capacity to the government.[ref 117] This was intended to give policymakers visibility into the physical infrastructure being assembled for advanced AI training.
On-chip governance mechanisms. Researchers have proposed adding technical components to chips that would give regulators visibility into large training runs without compromising AI companies’ commercial interests.[ref 118] Though requiring further research into technical feasibility, verification mechanisms have been a prerequisite for international cooperation in other domains (like nuclear nonproliferation) and may be just as valuable for AI governance.[ref 119]
Advantages of Targeting This Stage
Focusing policy interventions on semiconductor companies has four key advantages: excludability, quantifiability, detectability, and enforcement feasibility.[ref 120]
First, computing resources are excludable because people can be prevented from accessing them. Unlike data or algorithms, which are easily copied and shared, there are a finite number of operations that a single GPU can perform. If one actor is fully utilizing those operations, no one else can.
Second, compute is quantifiable—it “can be easily measured, reported, and verified” in terms of the operations per second a chip can perform or its communication bandwidth with other chips.[ref 121]
Third, large-scale training runs are detectable. The most advanced AI models currently require large-scale training runs using thousands of specialized chips concentrated in power-intensive data centers. These facilities are detectable by third parties, with some visible from satellite imagery.
Finally, the semiconductor supply chain is extraordinarily concentrated, making enforcement feasible.[ref 122] NVIDIA controls 80-95% of the market for AI chip design; TSMC fabricates approximately 90% of advanced chips; ASML supplies 100% of the extreme ultraviolet lithography machines used by leading foundries. This concentration makes the other three advantages actionable: fewer actors makes monitoring and enforcement easier.[ref 123]
Disadvantages of Targeting This Stage
Despite these advantages, semiconductor-focused interventions have three significant drawbacks: they rely on an assumption that may not hold, they are blunt and they become less effective the more they are used.
First, semiconductor-focused regulation relies on compute serving as an effective proxy for capability. If AI performance improves such that less-than-state-of-the-art models become capable of serious harm, or if algorithmic efficiency gains reduce the compute needed for dangerous capabilities, then semiconductor-focused interventions will miss their intended target.[ref 124] Additionally, as Arvind Narayanan and Sayash Kapoor have argued, “AI safety is not a model property,” since whether an output is harmful depends on context, and capability restrictions are thus, although laudable, a misguided approach.[ref 125]
Chip-level interventions are also among the bluntest available.[ref 126] Because semiconductors are general-purpose inputs, restrictions at this stage cannot distinguish between beneficial and harmful uses of AI. Export controls that limit access to advanced chips, for example, constrain medical research and climate modeling just as much as they constrain weapons development or surveillance. Policymakers targeting this stage risk throttling AI development altogether rather than surgically addressing specific harms.
Finally, semiconductor interventions are valuable in the short term but potentially counterproductive in the long-term. On-chip governance mechanisms and export controls, while potentially controlling how chips are used or limiting adversaries’ access to them in the short term, encourage investment in alternatives. On-chip restrictions could push buyers toward more open alternatives produced in other jurisdictions. Some have argued U.S. export controls benefit China’s semiconductor industry by encouraging further investment,[ref 127] though others believe such indigenization fears are overblown.[ref 128] And geopolitical competition may prevent countries from regulating their own semiconductor industries at all, for fear of ceding a competitive edge. Finally, compute-based restrictions may encourage innovation that renders compute less likely to be a bottleneck in the future. For example, DeepSeek’s efficiency may be an unintended consequence of limiting Chinese firms’ access to computing resources, with compute constraints forcing researchers to develop more efficient algorithms.
Summary
Semiconductor-based interventions are a powerful policy tool. They work best for harms that are identifiable without much context, where a single malicious actor’s access to advanced capabilities increases risk regardless of how they’re used. They are particularly valuable when traditional enforcement is impractical—against foreign actors, in situations involving diffuse harms, or when agencies cannot possibly monitor all end users. But policymakers should be aware that these interventions are a blunt instrument that incentivize workarounds, and they depend on compute remaining a bottleneck for dangerous capabilities.
B. Stage 2: Cloud Compute Providers
A handful of cloud computing providers—Amazon Web Services, Microsoft Azure, and Google Cloud—operate the computing infrastructure used by most developers to train and deploy AI models. Because this stage and the previous one both focus on the computational resources underpinning advanced AI, they share many characteristics and are often grouped together under the general heading of “compute governance.” This section focuses on the ways in which targeting cloud providers differs from targeting the semiconductor supply chain.[ref 129]
Examples of Policy Interventions
Know-Your-Customer (KYC) requirements. Efforts to impose KYC obligations on cloud providers date back to Trump’s first-term EO 13984 (2021),[ref 130] which Biden’s EO 14110 (2023)[ref 131] later expanded with AI-specific reporting mandates. Providers would be required to notify the government when foreign actors access computing resources above certain thresholds, aiming to prevent adversaries from anonymously using U.S. infrastructure for dangerous AI development.
Cybersecurity compliance and AI safety standards. In 2024, the Commerce Department’s Bureau of Industry and Security (BIS) proposed rules requiring cloud providers and their clients to report on frontier AI development activities, including compliance with cybersecurity frameworks and results of mandatory red-teaming tests.[ref 132] This would leverage cloud providers as enforcers to ensure hosted AI projects meet security benchmarks.[ref 133]
Government oversight of frontier AI training. Some researchers have recommended requiring licenses for AI training that exceeds certain compute thresholds.[ref 134] Cloud providers would require government approval before allowing training runs capable of producing frontier models—resembling licensing in the aerospace and nuclear energy industries.
Advantages of Targeting This Stage
Cloud computing shares the same fundamental advantages as semiconductor governance—concentration, excludability, quantifiability, and detectability—but offers additional benefits for regulators.
First, cloud providers’ business models already require extensive monitoring. Because they charge customers based on usage, they precisely measure resource consumption through metrics like floating-point operations, GPU hours, and energy consumption. This existing infrastructure can be repurposed for regulatory compliance with less added burden.
In addition, unlike the semiconductor supply chain, which is distributed across the United States’ allied nations, including the Netherlands, Japan, and Germany, the world’s largest cloud providers are headquartered in the United States. This gives American policymakers more jurisdictional flexibility in designing and enforcing regulations.[ref 135]
Cloud providers can also respond to non-compliance immediately. Unlike semiconductor restrictions, where there is a lag between placement on an export control list and actual business disruption, cloud access can be revoked in real time (similar to how banks can freeze accounts). This makes cloud-based enforcement more like financial regulation than trade regulation.
Disadvantages of Targeting This Stage
Cloud provider interventions share the two core weaknesses of semiconductor controls and add a third.
Like semiconductor interventions, cloud-based regulation relies on the assumption that advanced AI requires access to large compute clusters. If algorithmic efficiency improves enough that dangerous capabilities can be achieved with modest resources, then cloud-focused controls will miss their target.
Cloud restrictions also risk sparking the same kind of workarounds and indigenization that undermine export controls. Developers facing extensive compliance requirements may switch to less-regulated providers in other jurisdictions, and countries seeking AI independence or “sovereignty”[ref 136] may invest in domestic cloud infrastructure precisely to escape U.S.-based oversight. The more effective cloud controls are in the short term, the stronger the incentive to route around them in the long term.
Finally, cloud interventions also raise concerns that detailed tracking of activity on clients’ servers could expose information that companies treat as trade secrets like training techniques.[ref 137] And broad authority to cut off companies’ access to computing resources creates potential for abuse, as officials might target companies disfavored by the governing party or use access as leverage for purposes beyond AI safety.
Summary

Cloud provider interventions function as a more responsive version of semiconductor controls—enforcement can happen immediately rather than through supply-chain disruption. They are particularly valuable when real-time response matters or when tracking the identity of AI developers (rather than just their capability) is important. However, they come with greater privacy trade-offs and the same diminishing-returns problem as other compute governance approaches.
C. Stage 3: Data Suppliers
AI models are trained on data sourced from many entities: large-scale web scrapers (like C4), crowdsourced platforms (like Amazon Mechanical Turk), and specialized data labeling companies (like ScaleAI and Mercor).[ref 138] The goal of data-supplier-focused interventions is to improve the upstream collection and quality of AI training data to reduce downstream harms.[ref 139]
Examples of Policy Interventions
Individual data rights. Several states require data brokers to register with the government and disclose details about the data they collect, how it’s used, and their sharing practices. California’s Delete Act aims to allow residents to request deletion of their personal information from data brokers through a single request.[ref 140] Illinois’s Biometric Information Privacy Act (BIPA) requires opt-in consent for entities collecting biometric data,[ref 141] significantly affecting AI facial recognition training. With AI, honoring these rights may involve removing data from supplier databases, retraining models, or filtering outputs traceable to deleted data, though the FTC has ordered complete model deletion in cases of egregious data misuse.[ref 142]
Collective licensing and compensation mechanisms. John Axhamn has proposed an “Extended Collective Licensing (ECL)” scheme that would allow AI developers to legally train on copyrighted works while ensuring rightsholders receive compensation.[ref 143] A Congressional Research Service report discusses these frameworks as potential solutions to the tension between AI training and intellectual property rights.[ref 144]
Public datasets. Governments and research institutions could create and maintain high-quality public datasets. The Trump administration’s Genesis Mission is an attempt to unify federal scientific archives into a centralized, standardized platform, democratizing AI development for smaller companies and academic researchers who lack resources to develop proprietary datasets.[ref 145]
Advantages of Targeting This Stage
Addressing data quality and legality at the point of collection and aggregation can prevent problems from multiplying as models are deployed.[ref 146]
Many data supplier regulations align with existing privacy laws like GDPR and CCPA.[ref 147] This allows policymakers to build on established definitions, enforcement mechanisms, and compliance infrastructure rather than creating entirely new regulatory regimes.
The data broker[ref 148] and AI data labeling[ref 149] industries are also relatively concentrated, allowing authorities to oversee a significant portion of data flowing into AI systems by regulating a manageable number of entities.
Disadvantages of Targeting This Stage
Data suppliers can operate globally, potentially sourcing data from or locating servers in jurisdictions with weaker regulations. AI developers might bypass rules by using offshore brokers or scraping data outside the state’s reach.[ref 150]
Defining who qualifies as a regulated “data supplier” is also difficult.[ref 151] Rules could be too narrow (missing web scrapers) or too broad (burdening nonprofits like Wikipedia or individual bloggers). And compliance costs may further consolidate the market around larger players who can afford them.
Finally, regulations restricting collection, sale, or use of data may face First Amendment challenges. The Supreme Court’s decision in Sorrell v. IMS Health held that the “creation and dissemination of information are speech,” meaning data regulations can potentially trigger heightened constitutional scrutiny.[ref 152]
Summary

Data supplier regulations are most useful for harms directly linked to data inputs—privacy violations, copyright infringement, and biased training data—and where key data sources are concentrated and identifiable. They also benefit from alignment with existing privacy frameworks like GDPR and CCPA. They are less effective when data is highly diffuse, when suppliers operate across jurisdictions, or when defining the scope of regulated entities is difficult.
D. Stage 4: AI Model Developers
This stage focuses on organizations that research, develop, and train large-scale AI models—entities like OpenAI, Anthropic, Google DeepMind, Meta AI, and xAI. Given their central role in developing core AI capabilities, model developers are frequent targets for policy intervention.[ref 153]
Examples of Policy Interventions
Transparency and Disclosure Mandates. The most common type of intervention at the state level promotes transparency through disclosure requirements.[ref 154] These can take several forms: requiring companies to publish reports on model development and testing processes; mandating watermarks or content provenance techniques to label AI-generated content; creating whistleblower protections for AI lab employees; and establishing incident reporting requirements for significant safety events.
Testing, Design, and Oversight Requirements. These interventions focus on ensuring safety through design mandates and ongoing oversight.[ref 155] They might include ex ante design features (cybersecurity safeguards, content filtering, “kill switches”), standardized pre-deployment evaluations, red-teaming by internal safety experts,[ref 156] or third-party audits by civil society organizations (like METR) or government agencies (like the UK AISI or US CAISI).[ref 157]
Liability frameworks. Policy researchers have advocated holding model developers liable for harms caused by their systems.[ref 158] California’s SB 53, for example, authorizes the state Attorney General to bring civil actions against developers for failure to report safety incidents or comply with their own frameworks, with damages up to $1,000,000.[ref 159] Insurance requirements could complement direct liability by ensuring compensation is available and creating actuarial signals about the riskiest models.[ref 160] For catastrophic risks, policymakers could consider ex ante mechanisms like mandatory liability insurance or industry-wide compensation funds, modeled on frameworks like the Price-Anderson Act for nuclear accidents.[ref 161]
Advantages of Targeting this Stage
Transparency measures are among the least controversial categories of model developer regulation.[ref 162] Even experts who disagree about the speed and shape of AI risks often agree on the need for more transparency.[ref 163] The rationale is that disclosure empowers users, researchers, and regulators to make informed decisions—if people know how a model was created and tested, they can better assess its reliability and risk.
Testing and oversight requirements can target vulnerabilities in base models that propagate to downstream applications. If a foundation model has a security vulnerability or can be tricked into revealing training data, applications built on top of it can inherit those vulnerabilities.[ref 164] It also leverages technical expertise outside government: regulators can set standards and review results while outsourcing the highly technical evaluation process to specialists.[ref 165]
Finally, liability incentivizes developers to prevent harms by requiring them to pay for damage caused by their models. Liability forces companies to internalize externalities rather than shifting costs to users or society. It also can function as a floor of legal protection, with some egregious AI harms likely falling within the scope of existing tort law.[ref 166]
Disadvantages of Targeting this Stage
Transparency requirements carry their own risks. Detailed disclosures about training data or architectures could expose trade secrets, allowing competitors (including foreign actors) to free-ride on research investments. Watermarking faces technical feasibility concerns: determined actors can remove watermarks, and open-source models that don’t apply them will remain unlabeled. And in the United States, compelled disclosure requirements may face First Amendment challenges as compelled speech.[ref 167]
Oversight requirements face a different problem: defining “safe enough” is extremely difficult. AI systems can fail in unpredictable ways, and any set of evaluations risks missing novel failure modes. Worse, developers might learn to game required tests, tuning models to pass evaluations without truly improving safety.[ref 168] Extensive testing requirements can also slow innovation and concentrate the market as larger, well-resourced companies absorb compliance costs more easily.
Finally, liability is limited by the fact that many AI harms are not within developers’ sole control. AI systems are general-purpose tools used in countless contexts far removed from what creators envisioned. If an open-source model is integrated into hundreds of applications, it may be unfair to blame the model’s creators for a particular application’s failure or a user’s misuse. Defining “reasonable care” for AI, determining causation when multiple actors are involved, and apportioning liability (joint and several vs. proportional) all present difficult legal questions.[ref 169] Liability also functions best when wrongdoers can afford to pay; when the defendant lacks resources or the harm is too large, liability does not fully compensate victims and is a less effective deterrent.
Summary
Model developers are a natural focal point for AI regulation because they control the foundational capabilities on which downstream applications depend. Transparency requirements enjoy the broadest support and face the lowest political barriers, though they must be designed to avoid exposing proprietary information. Testing and oversight requirements can catch vulnerabilities before they propagate downstream, but they must be iteratively adjusted as capabilities evolve—static evaluations will quickly become obsolete. Liability frameworks complete the picture by internalizing costs, but their effectiveness depends on resolving difficult questions about causation, apportionment, and the financial capacity of defendants to pay for harms their models enable.
E. Stage 5: Application Deployers
The application layer is where AI capabilities are operationalized into products and services. The entity developing the model can also be the deployer (OpenAI’s ChatGPT is built on its GPT models), but different companies can also build applications on top of models developed by others. Applications span nearly every sector: predictive algorithms for employment screening (HireVue, Pymetrics) and criminal justice risk assessments (COMPAS); generative models powering chatbots (Character.ai) and coding environments (Cursor); and agentic systems capable of completing tasks without human intervention (Claude Code, Devin).
Examples of Policy Interventions
Incident reporting. When AI applications malfunction or cause harm, rapid disclosure enables regulators and the public to identify patterns and respond before problems spread. Analogous requirements exist across regulated industries: the FDA mandates adverse-event reporting for medical devices, NHTSA requires crash reporting for autonomous vehicles, and the FAA tracks near-miss incidents in aviation. Extending this model to AI deployers would require companies to notify a designated agency when their systems produce significant failures—whether a hiring algorithm systematically excludes qualified candidates or a medical diagnostic tool generates dangerous misdiagnoses. The core difficulty is defining what counts as a reportable “incident” for general-purpose AI systems that operate across diverse contexts.
Tort liability. Application deployers are also potential targets for liability.[ref 170] Injured parties can sue the deployer for compensation if a particular application causes harm. One mother, for instance, sued Character.AI over her son’s suicide, alleging design defects.[ref 171] In a separate case, the parents of a sixteen-year-old sued OpenAI, alleging that ChatGPT acted as a “suicide coach” that encouraged their son’s suicidal ideation.[ref 172] The possibility of liability creates incentives to build safe products. Legislatures can play an important role in ensuring this system functions well. California’s AB 316, for example, is a recently enacted bill that aims to ensure there is no AI exception to existing tort liability frameworks.[ref 173] It prevents defendants from disclaiming responsibility by arguing that an AI agent acted autonomously.[ref 174] Legislatures could also codify duties of care rather than leaving courts to define them through the common-law process.
Age restrictions. These provisions require deployers to implement age-appropriate design for systems used by minors, including limiting data collection, obtaining parental consent, and requiring plain-language explanations. Texas’s SCOPE Act (2024) offers a comprehensive template: it requires parental consent before minors can create accounts, prohibits in-app purchases and geolocation tracking for minors, bans targeted advertising to children, and mandates content filtering for material promoting self-harm, substance abuse, or exploitation.[ref 175] This approach is valuable because it shifts the compliance burden onto platforms rather than parents, creating structural protections that don’t depend on individual digital literacy or vigilance.
Self-exclusion. These statutes require deployers to build protective features into products—such as session caps, break reminders, and disabling infinite scroll—that help users limit their own consumption. The UK Gambling Commission’s “reality check” regulations provide a direct model:[ref 176] operators must display recurring on-screen reminders of elapsed session time that users must actively acknowledge before adding new funds,[ref 177] and the UK has banned autoplay features entirely while mandating time intervals between interactions.[ref 178] This framework is valuable because it acknowledges that willpower alone may be insufficient against products engineered for engagement, and it creates friction that can help users close the gap between what they want and what they want to want.
Outright bans. In contexts where AI is deemed too dangerous, policymakers might prohibit its use entirely. The U.S. Space Force temporarily banned generative AI based on security concerns.[ref 179] Several cities have banned law enforcement use of facial recognition based on privacy concerns.[ref 180] Illinois recently banned AI therapy chatbots out of concern for user safety.[ref 181] Recently proposed legislation in Tennessee would make it a felony to train a language model to “provide emotional support, including through open-ended conversations with a user.”[ref 182]
Advantages of Targeting This Stage
Regulating at the application layer gives lawmakers maximum context about AI-related harms. Because deployers operate in defined settings, regulators can set outcome-oriented requirements (i.e., maximum error rates for medical diagnosis or bias thresholds for hiring) and verify through real-world data that requirements are reducing harms.
This approach strongly aligns with existing regulatory expertise. Sector agencies like the FDA, NHTSA, EEOC, and SEC already police safety and integrity within their domains. Extending their mandates to cover AI-enabled products leverages existing staff, testing protocols, and enforcement tools. In many cases, new legislation may not be required because existing sector-specific laws and agency authorities can be applied to AI.
Disadvantages of Targeting This Stage
Effective application-layer intervention requires coordinating across many industries, each with its own stakeholders and lobbyists who may resist oversight. While sector-specific legislation may be more precise, policymakers may prefer omnibus “AI bills” for political reasons, since a single high-profile bill can yield greater electoral rewards than piecemeal legislation.
Even with political will for sector-specific regulation, different agencies crafting different rules creates fragmentation. AI applications that don’t fit neatly into existing categories may slip through gaps. Products crossing regulatory boundaries—a health chatbot handling both insurance questions and medical advice—may face overlapping or conflicting obligations.
A further concern is regulatory capture. Sector regulators develop close relationships with the industries they oversee; over time, this can blunt enforcement or slow rule updates as technology evolves.
Summary
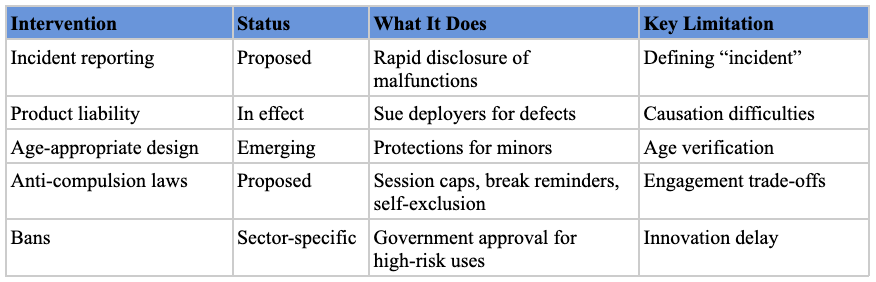
The application layer is one of the most promising regulatory targets because deployers operate in concrete settings where harms are observable and measurable, and because many enforcement agencies—the FTC, EEOC, FDA, NHTSA—already have authority to regulate AI-related activities without new legislation. It is less effective when products span multiple regulatory domains, creating gaps and inconsistencies between agencies.
The least-cost-avoider principle is useful here: deployers who control application design and the context in which AI capabilities reach users should bear responsibility for design flaws and foreseeable failures, while liability for sophisticated misuse that deployers could not reasonably anticipate or prevent should shift to end users.
F. Stage 6: Complementary and Enabling Platforms
Platforms are often essential for translating digital outputs into real-world consequences. E-commerce marketplaces like Amazon facilitate physical goods purchases; gig economy platforms like TaskRabbit connect requesters with workers who perform physical tasks; social media networks like Meta distribute content to mass audiences. While these platforms may not develop AI themselves, they can serve as essential channels through which AI-enabled harms materialize. A language model requires access to enabling infrastructure to purchase precursor chemicals, hire a courier, or broadcast disinformation.
This intermediary role makes enabling platforms uniquely important for AI governance. They represent the last major chokepoint before harm occurs, operating at the boundary between digital intent and physical or social consequence.
Examples of Policy Interventions
E-commerce and Procurement Platforms
Know-Your-Customer and suspicious activity reporting. Platforms could be required to verify purchaser identities for certain categories of goods (chemicals, laboratory equipment, dual-use materials) and report suspicious purchasing patterns to relevant authorities, similar to banking regulations under the Bank Secrecy Act.[ref 183]
AI-aware transaction monitoring. As AI agents gain the ability to autonomously browse and purchase goods, platforms may need new detection mechanisms. Jonathan Zittrain has proposed that AI agents carry identifying credentials—akin to “license plates”—that would allow platforms to apply heightened scrutiny to agent-initiated transactions, particularly for sensitive goods categories.[ref 184]
Gig Economy and Labor Platforms
Task screening and identity verification. Platforms like TaskRabbit, Fiverr, and Upwork could be required to maintain explicit prohibitions on tasks that facilitate illegal activity—delivering unknown substances, conducting surveillance, accessing restricted areas—and to require enhanced identity verification for task categories with higher abuse potential.
Worker protection and refusal rights. Gig workers may be unwitting participants in harmful schemes.[ref 185] Regulations could guarantee workers the right to refuse suspicious tasks without penalty and require platforms to maintain reporting channels for workers who suspect they are being used for illicit purposes.[ref 186]
Social Media and Content Distribution Platforms
Synthetic content labeling requirements. Building on recent state laws, policymakers could mandate that AI-generated content be labeled when distributed on social media,[ref 187] including technical standards for embedded metadata (such as C2PA provenance standards)[ref 188] and disclosure requirements for accounts that post primarily AI-generated content.[ref 189]
Amplification accountability. Beyond content moderation, platforms could face obligations related to algorithmic amplification—transparency requirements for recommendation algorithms, prohibitions on amplifying content that violates platform policies, or duties to detect coordinated inauthentic behavior.
Section 230 reform. The most significant potential intervention involves modifying Section 230 of the Communications Decency Act, which currently immunizes platforms from liability for user-generated content.[ref 190] Reform proposals range from narrow carve-outs (removing immunity for algorithmically amplified content) to broader conditions (requiring reasonable content moderation as a prerequisite for immunity).[ref 191]
Advantages of Targeting This Stage
These platforms represent the final major chokepoint before harms materialize. Even if upstream interventions fail, enabling platforms can still prevent the final step. A bioweapon cannot be synthesized without ingredients; an influence campaign cannot succeed without distribution.
Additionally, unlike AI-specific entities, enabling platforms already operate under extensive regulatory frameworks (e.g., consumer protection laws, export controls, anti-money-laundering rules). Extending these frameworks to address AI-enabled harms leverages established compliance capabilities.
Finally, platform intermediation creates records that facilitate both ex ante screening (flagging suspicious patterns) and ex post investigation (reconstructing how harm materialized).
Disadvantages of Targeting This Stage
The sheer volume of platform activity is the first challenge. Major platforms process billions of transactions.[ref 192] Any screening system will produce false positives and false negatives; at scale, even low error rates translate into millions of affected transactions.
Even with effective screening, platforms often cannot determine whether a transaction is AI-enabled. Without reliable signals distinguishing human from agent activity, platforms cannot easily apply differential scrutiny.[ref 193] Requiring AI disclosure depends on the honesty of precisely those actors least likely to comply when pursuing harmful ends.
Content-related interventions face an additional obstacle. For social media platforms, content-based regulations face significant constitutional scrutiny under the First Amendment. Requirements to remove or label certain categories of speech must be narrowly tailored to compelling government interests.
Finally, users seeking to evade restrictions can shift to less-regulated platforms, international services, or decentralized alternatives like cryptocurrency marketplaces or federated social networks.
Summary
Enabling platforms are most valuable as intervention targets when harms require real-world resources or distribution that platforms mediate. They are the last major chokepoint where harms can be intercepted, and they benefit from existing compliance infrastructure that can be extended to AI-specific concerns. Platform-level interventions are less effective when users can easily shift to unregulated alternatives; they also face significant First Amendment constraints for content-related regulations. The least-cost-avoider principle suggests platforms should bear responsibility for harms they are well-positioned to prevent: suspicious purchasing patterns, task requests that facially violate policies, and content that clearly meets removal criteria. But platforms are not well-positioned to prevent harms requiring information they lack or judgment calls they cannot reliably make at scale.
G. Stage 7: End Users
End users are the final actor in the AI ecosystem. Institutional users like businesses and government agencies embed AI tools into existing workflows, often under sector-specific laws. Individual users typically lack formal compliance programs or resources to vet AI systems, yet their choices can still inflict measurable harm and are subject to liability under the tort system.[ref 194]
Examples of Policy Interventions
Organizations Using AI
Human oversight requirements. These require qualified people to oversee or override AI predictions.[ref 195] A bank using predictive AI for loan approvals might require a human loan officer to sign off on high-stakes decisions. The idea is that human oversight provides a fail-safe to catch errors or bias that AI systems might miss, though there are compelling critiques that people might simply rubber-stamp AI decisions.[ref 196] They are also called “human-in-the-loop” requirements.
Training and certification. Hospitals, financial firms, or law enforcement agencies might be required to obtain accredited licenses or complete mandated coursework before deploying high-risk AI systems.
Record-keeping and audit trails. Organizations may need to log prompts, outputs, and decision rationales so regulators or litigants can reconstruct how harmful decisions occurred.
Individuals Using AI
Use existing tort law to find liability. Many harms individuals can inflict with AI—hacking, defamation, malpractice—are already covered by criminal statutes, tort principles, or professional ethics rules.[ref 197] Even if the tool changes (AI), the duty does not. For example, a lawyer must still verify citations whether they come from Westlaw or a language model. State attorneys general and other entities authorized to enforce laws can reinforce this through guidance and sanctions without creating new technology-specific offenses.
Create AI-specific duties for genuine gaps. Where existing law does not squarely address new harms, legislatures can craft targeted rules—criminalizing non-consensual AI-generated intimate imagery or requiring disclosure for synthetic political ads depicting candidates saying things they never said.[ref 198]
Advantages of Targeting This Stage
End-user liability puts accountability on the actor often best positioned to prevent harm. The individual or organization that chooses to post a deepfake, ignore a safety warning, or rely blindly on AI output controls the immediate risk and can avoid it at low cost—by double-checking facts, limiting sensitive prompts, or declining to deploy AI in high-stakes contexts.
Focusing sanctions at the user layer also protects upstream innovation. Model developers and application builders can continue releasing general-purpose tools without bearing the full weight of every possible downstream abuse, because liability attaches only when users turn tools toward prohibited or negligent uses.
Finally, user-level liability also carries expressive value. By singling out certain AI-enabled acts as punishable—non-consensual synthetic pornography, fraudulent legal filings, deceptive political ads—the law signals which uses of AI violate shared norms, helping shape social expectations in a fast-moving technological landscape.
Disadvantages of Targeting This Stage
End-user liability is inherently retroactive: it activates only after harm has occurred. For irreversible injuries—viral deepfakes that permanently taint reputations, election disinformation that cannot be “un-voted,” psychological trauma from non-consensual intimate images—damages or takedowns arrive too late to help those already harmed.
Identifying individual bad actors is also logistically difficult. Malicious users can automate anonymous accounts, route traffic through foreign servers, or hide behind encryption, making attribution expensive or impossible. Enforcement may depend on platforms or foreign authorities with their own incentives and delays, and plaintiffs face steep proof burdens for causation, while prosecutors must establish intent beyond reasonable doubt.
First Amendment constraints present additional obstacles when regulations target individual expression. Penalties for AI-generated content must be drafted to avoid viewpoint discrimination and unconstitutional vagueness.
Finally, aggressive liability risks over-deterrence. If users fear ambiguous civil suits or criminal charges, journalists may shy away from probing models to expose bias, artists may forgo transformative remixes, and small businesses may abandon useful automation rather than gamble on uncertain legal boundaries.
Summary
End-user interventions work best when harms result from intentional misuse and the likelihood of effective deterrence is high. They are less useful when offenders are hard to identify or influence (foreign disinformation operators, anonymous bad actors). To strengthen deterrence, policymakers can offer multiple independent enforcement mechanisms (government action plus private rights of action) and impose high statutory penalties. The least-cost-avoider principle can be helpful here: where the user’s choice is the proximate cause of harm, liability should follow.
Conclusion
AI policy is difficult. The technology is general-purpose, fast-moving, and embedded in an ecosystem of actors with overlapping roles and responsibilities. But difficulty is no excuse for imprecision. This primer has argued that effective AI regulation requires specificity along three dimensions: the harm being addressed, the design principles guiding the intervention, and the stage of the AI lifecycle being targeted.
These choices inevitably involve tradeoffs. Preventive interventions reduce irreversible harms but risk being overbroad. Upstream regulations offer leverage over the entire ecosystem but are too blunt to address application-specific problems. Targeting the least-cost avoider is efficient but may concentrate compliance burdens on a small number of firms. No single intervention can address all AI harms, and most will implicate competing values.
This primer does not resolve those tradeoffs—nor could it, given how much depends on context, values, and the specific harm at issue. What it offers instead is a framework for confronting them with greater clarity. Policymakers who can specify which harm they are addressing, justify the regulatory design they have chosen, and identify where in the AI ecosystem their intervention will take effect are better positioned to write laws that are effective, proportionate, and durable.