Radical Optionality: Governing Transformative AI Under Uncertainty
We are pleased to announce a new essay by LawAI Director Christoph Winter and Senior Research Fellow Charlie Bullock: Radical Optionality: Governing Transformative AI Under Uncertainty.
The prospect of “transformative AI” appears to present policymakers with a dilemma: overregulation could stifle innovation and forfeit the potential benefits of the technology, while a failure to regulate appropriately could have disastrous implications for public safety and national security.
It’s true that security and innovation are sometimes in tension. Some safety measures do impose costs on innovation, and some forms of deregulation do carry genuine risks. But there is also a class of policies that would meaningfully increase safety without imposing significant costs on innovation. We argue that governments should aggressively implement these policies; this is the main thrust of the governance strategy discussed in this essay, which we call “radical optionality.”
At its core, radical optionality is about preserving democratic governments’ ability to make good decisions about how to govern transformative AI systems as circumstances evolve. In the short term, this means avoiding overregulation while rapidly building the institutions, information channels and legal authorities needed to respond competently to a broad range of scenarios.
The argument for focusing on optionality is simple, and—if you accept a few reasonable assumptions—compelling. These assumptions are:
- That there is a real possibility of transformative AI (defined as “AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution”) being developed within the next ten years;
- That profound uncertainty exists as to what capabilities transformative AI systems will possess, what benefits and risks they will generate, and what the best ways for society to capture the benefits while mitigating the risks will be;
- That a transformatively impactful dual-use technology with significant national security implications will inevitably require some degree of government oversight; and
- That building the institutional capacity required to effectively govern transformative AI systems will take years, and that society therefore cannot afford to wait until transformative capabilities have actually been developed.
Justifying the first assumption is beyond the scope of this paper. Whether “AGI” or “superintelligence” or “powerful AI” or “transformative AI” will ever arrive, and when, are questions that have been debated extensively elsewhere. But if you believe that transformative AI is possible, we hope to demonstrate that the case for radical efforts to preserve optionality is overwhelmingly strong.
Read the essay at https://radical-optionality.ai/
Announcing the Cambridge Commentary on EU General-Purpose AI Law
We are pleased to announce the launch of the Cambridge Commentary on EU General-Purpose AI Law, the first scholarly commentary focused exclusively on the general-purpose AI model provisions of the EU AI Act. It is a collaboration between the Leverhulme Centre for the Future of Intelligence at the University of Cambridge and the Institute for Law & AI.
The EU AI Act is the first comprehensive legal framework designed specifically to govern AI. Where existing law — product liability, data protection, sector-specific regulation — reached AI incidentally, the AI Act subjects it to a dedicated legal regime, with all the promise and risk that entails. As a pioneer regulation, it aims not only to promote safe, human-centric and trustworthy AI within the EU, but also to influence global standard-setting, echoing the “Brussels effect” seen in other regulatory domains.
Rigorous legal analysis of the AI Act therefore matters beyond the EU. Robust insights may not only support an effective EU regulatory approach, but will also be relevant to evaluating how best to design effective AI governance regimes in other jurisdictions. In particular, research focused on general-purpose AI (“GPAI”) models, especially those that present systemic risk, may be of particular importance, given the potential for good and harm, technological novelty, and the consequential regulatory uncertainties.
“Many of the most consequential provisions governing frontier or general-purpose AI admit of more than one reasonable interpretation,” said Christoph Winter, general editor of the Cambridge Commentary, Director of the Institute for Law & AI, and Assistant Professor at the University of Cambridge. “Our goal was to be precise about where that uncertainty lies and to lay out the strongest arguments on each side so that readers can form their own views as the law and technology develop.”
Rather than advocating throughout for a single preferred reading, the Cambridge Commentary on each provision aims to map the interpretive landscape: to identify where the legislation is clear, where it is ambiguous, and what the strongest arguments on each side look like. Where contributors favour a particular interpretation, they say so explicitly. The goal is to equip readers — practitioners, regulators, and scholars alike — to reason well about these questions and to adjust their views as the law and technology develop, rather than to hand them conclusions that may not endure over time.
The Cambridge Commentary launches with Chapter V of the AI Act, which forms the core of the GPAI model provisions. Further articles and chapters will be added on a rolling basis.
Access the Cambridge Commentary at cambridge-commentary.ai.
Foreseeing the Unforeseeable: How U.S. Negligence Law Should Address the Foreseeability of Harms Caused by Autonomous AI Agents
Abstract
As AI systems increasingly perform tasks with limited human oversight, courts will soon be required to determine how negligence law should respond when autonomous AI agents cause personal injury. Traditional foreseeability doctrine, as many scholars have observed, may fail to account for the opacity and unpredictability that characterize these systems. The main challenge could arrive when AI developers claim that a harmful outcome was unforeseeable because the specific causal pathway was novel, complex, or obscure. This article argues that such reasoning misallocates responsibility. Building on recent scholarly work, it takes the view that opacity and unpredictability are not inherent features of advanced AI systems. Rather, they are the result of abstraction choices made by AI developers, who often prioritize accuracy and efficiency over interpretability and predictability. When those choices increase the likelihood of opaque or unexpected outcomes, the legal framework should be adjusted to reflect that responsibility. In particular, where the foreseeability standard in negligence law typically makes it difficult for plaintiffs to prevail, it should be relaxed in their favor. The article examines how U.S. courts apply foreseeability across duty, breach, and proximate cause, and identifies the duty stage as the most urgent point for reform. It proposes a three-part doctrinal framework for cases involving personal injury caused by autonomous AI agents. First, courts should preserve existing law where foreseeability is already sympathetic to plaintiffs. Second, they should replace overly fact-intensive duty inquiries with clear, plaintiff-friendly categorical reasoning. Third, they should retain fact-intensive analysis at the breach and proximate cause stages to prevent overextension of liability. This approach maintains foreseeability as a meaningful constraint while calibrating it to the distinctive risks posed by autonomous AI agents.
Mackenzie Arnold Participates in GAO Panel on AI Privacy Risks
Background
Between January 13–15 2025, the U.S. Government Accountability Office (“GAO”) convened a panel of experts to examine privacy risks associated with artificial intelligence. The panel brought together 12 specialists from federal agencies, academia, nongovernmental organizations, and private industry, to inform recommendations to the Office of Management and Budget (“OMB”).
Mackenzie Arnold, LawAI’s Director of U.S. Policy, participated alongside leading figures in AI, law, and policy, including Dominique Duval-Diop (U.S. Department of Commerce), Jennifer King (Stanford Institute for Human-Centered Artificial Intelligence), and Deirdre Kathleen Mulligan (White House Office of Science and Technology Policy).
The panel identified 13 challenges related to protecting privacy when using AI, including:
- Lacks of skills among federal workforce to implement AI while mitigating privacy risks
- Scalability of implementing AI systems with privacy protections
- Auditing and evaluating AI models with sensitive information
Conclusions
The panel found that AI systems may reveal sensitive information in raw data sets, potentially exposing personal and private information, among other privacy risks. They also identified several challenges that federal agencies face in addressing these risks, including trade-offs between model performance and the modification or removal of data for the purpose of privacy.
In March 2026, GAO issued two recommendations for Executive Action to OMB:
- Specify examples of known privacy-related risks that agencies should consider when updating their policies as they pertain to AI.
- Facilitate additional information sharing or issue government-wide guidance related to:
- how agencies should consider privacy when evaluating and auditing AI models that contain sensitive information;
- storing data in a manner where sensitive data can be separated from the dataset;
- clear rules, norms, and best practices with respect to privacy that agencies should use when developing AI solutions internally;
- performance metrics agencies can use to assess privacy-related impacts when using AI;
- actions agencies can take to ensure that members of the public who interact with their AI technologies understand what they are consenting to;
- technological tools agencies can use to protect sensitive data when using AI;
- incorporating AI-specific considerations into privacy impact assessments, including identifying risks and informing the public about how PII is involved in the use of AI; and
- potential tradeoffs between privacy and performance agencies can consider when using AI.
The full GAO report is available here.
Mapping AI Policy: Where, Why, and How to Intervene
Abstract
State lawmakers introduced over 1200 bills on artificial intelligence (AI) in 2025, nearly doubling the number from the year before. Almost 150 were enacted.[ref 1] They cover topics as varied as deepfakes, biased decision-making systems, or rogue AI systems. Yet the media describes them all as “AI legislation,” revealing an impreciseness that makes it hard for legal practitioners, policymakers, and the public to understand key AI policy issues.
This primer offers a framework for thinking more precisely about AI policy. It analyzes legislation along three dimensions: the harm being addressed (the why), the factors that should guide intervention design (the how), and the actor in the AI ecosystem being targeted (the where).
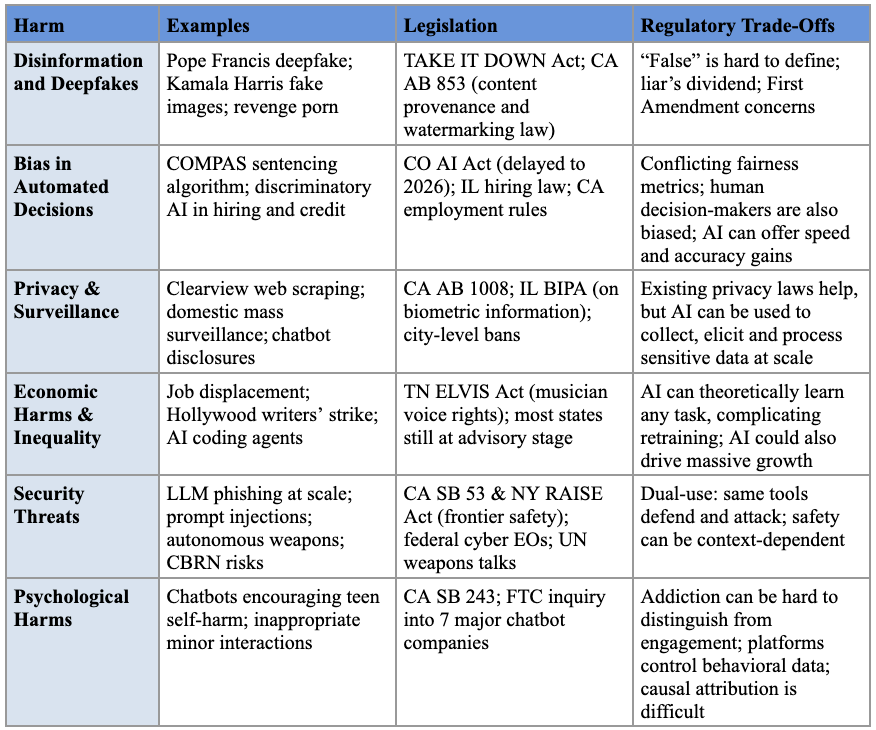
Part I organizes the universe of AI harms into six categories: (1) mis- and disinformation-related harms; (2) bias in automated decision systems; (3) privacy and surveillance harms; (4) economic harms and inequality from automation; (5) security threats; and (6) psychological harms. With so many applications being called AI—including search engines, chatbots, pricing algorithms, and robots—lawmakers risk being overwhelmed by the consequences of AI if they do not have a clear goal in mind.
Part II introduces seven design factors that recur across harms and stages: whether to prevent harms or respond to them, how an intervention affects concentration of power, whether regulation is the right tool at all, and others. These factors are often in tension. An intervention that decentralizes the AI ecosystem may make enforcement harder; one that restricts offensive capabilities may also degrade beneficial ones.
Part III maps the actors in the AI ecosystem—from chip manufacturers to end users—and analyzes the advantages and limitations of targeting each. Analyzing AI in this way highlights the distinct functions performed by the actors within the AI ecosystem, enabling policymakers to design more tailored interventions rather than relying on overly broad regulatory categories.
Ultimately, this primer underscores two core principles for navigating the complexities of AI policy. First, the more precisely policymakers can identify the harm and the actor best positioned to prevent it, the more effective their interventions are likely to be. Second, policymaking in this rapidly evolving domain is rarely simple; there are few free lunches, and choices will inevitably require confronting difficult tradeoffs. Accordingly, this primer does not advocate for specific policy positions. It offers a framework to empower policymakers to make better decisions on AI.
I. The Why: What AI-Related Harm Does the Policy Intervention Address?
To understand how to regulate AI, policymakers must first understand why they want to regulate it. How can one write laws to achieve a desirable end without knowing what that end is? This part gives policymakers language for specifying what they wish to achieve by outlining the AI-related harms they might wish to address.
The categories below are neither mutually exclusive nor comprehensive. One practice, for example, can fit into multiple buckets of harm. Algorithmic pricing, where companies use AI to charge different consumers different prices for the same product, can cause privacy harms (through the surveillance data collection that powers it), economic harms (through the higher prices it can impose), and bias harms (when higher prices correlate with protected characteristics like race or religion).
They are intended to be an illustrative list of commonly referenced AI harms that can serve as a starting point for policymakers writing and debating AI legislation. In particular, this primer does not address environmental harms from AI training and deployment or the intellectual property issues that arise from the use of copyrighted material in AI training. Here our focus is on harms caused by using AI, not those arising from the process of creating AI systems.
Each of the following subsections describes an example of the harm, offers examples of relevant legislation, and explains the unique aspects of the harm that make it difficult to address, as well as benefits that might be lost if the regulations are poorly designed.
A. Misinformation and Disinformation-Related Harms
The potential harms of AI-generated content resurface in the public discourse each time a deepfake goes viral. In 2023, a fabricated image of Pope Francis in a white puffer highlighted the impressive capabilities of state-of-the-art image generators,[ref 2] while the circulation of AI-generated images by Donald Trump’s presidential campaign in 2024—depicting his rival Kamala Harris at a communist rally and the singer Taylor Swift as a campaign supporter—underscored the technology’s potential for political disruption.[ref 3]
Amidst these concerns, several states have already enacted some legislation, though they have largely focused on two specific contexts: politics and pornography. To protect election integrity, over half of states have enacted laws requiring disclaimers on or banning the distribution of deceptive AI-generated campaign media.[ref 4] In addition, nearly all states have enacted laws prohibiting deepfake non-consensual intimate imagery (“revenge porn”).[ref 5] At the federal level, the recently enacted TAKE IT DOWN Act further strengthens these protections by creating a private right of action against individuals who produce or share such content and by requiring platforms to remove it upon notification.[ref 6]
Beyond these targeted applications, some legislative efforts have aimed to address content authenticity more broadly. California’s AI Transparency Act, for example, requires developers of generative AI models to enable digital watermarking and content provenance capabilities.[ref 7]
Despite this legislative activity, addressing the misinformation-related harms of AI remains challenging for at least four reasons. First, defining “false” or “misleading” in an objective, consistent, and apolitical way is extraordinarily difficult.[ref 8]
Second, the public perception of widespread misinformation is itself dangerous by eroding trust in the information ecosystem, creating a “liar’s dividend” where authentic content is more easily dismissed as fake.[ref 9]
Third, many interventions face First Amendment hurdles because they may infringe upon the free speech rights of platforms or users. This is not a theoretical concern; federal courts have enjoined Hawaii’s and California’s election deepfake laws, reasoning that their broad scope could unconstitutionally chill protected forms of speech like parody and satire.[ref 10]
Fourth, overly stringent regulations could inadvertently cripple the very capabilities that make large language models transformative. If LLM performance substantially suffers from excessive content restrictions, burdensome compliance mandates, or unclear liability rules, their utility could be severely diminished.[ref 11] For instance, models might become overly cautious, refusing to engage with complex or sensitive topics, thereby limiting their effectiveness as educational tools or research assistants.[ref 12]
B. Bias in Automated Decision Systems
Bias—systematic errors that result in unfair outcomes against certain individuals or groups—can enter AI systems through unrepresentative training data, societal prejudices reflected in that data, or the very objectives developers set for an algorithm.[ref 13] The stakes are high, as automated systems now make some of the most consequential decisions in people’s lives. For example, the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) algorithm has been used for years by judges nationwide to generate “risk assessments” for criminal sentencing.[ref 14] Despite concerns around racial, gender, and other biases in tools like COMPAS, such systems are widely used in other critical areas, including hiring[ref 15] and access to credit,[ref 16] among others.
Colorado’s AI Act (SB 24-205) is the signature legislation designed to address this problem.[ref 17] Enacted in May 2024, it requires developers of high-risk systems to use “reasonable care” to protect consumers from algorithmic discrimination by mandating risk management programs and impact assessments. However, because its provisions have been delayed until at least June 2026, the bill’s real-world impact remains to be seen.[ref 18] Other states have followed Colorado’s lead with their own variations: Virginia’s legislature passed a similar bill that was ultimately vetoed,[ref 19] Illinois enacted a law targeting discriminatory AI in hiring,[ref 20] and California has issued anti-discrimination regulations for automated employment systems.[ref 21]
Addressing AI biases has proven difficult, despite nearly a decade of awareness among policymakers and technologists. A core challenge is translating abstract concepts of “fairness” into quantifiable metrics; researchers have identified at least 21 distinct mathematical definitions of fairness,[ref 22] many of which are mutually exclusive.[ref 23] Furthermore, restricting automated systems over bias concerns presents a difficult trade-off. Doing so could mean reverting to human decision-makers, who have their own biases,[ref 24] while also sacrificing the speed, cost-efficiency, and potential accuracy gains that algorithms offer.
C. Privacy and Surveillance Harms
AI creates privacy and surveillance risks at three key stages: when information is collected to build AI, when it is exposed while using AI, and when AI is deployed to collect and process new information.
The first risk arises from the data collection used to train AI models, which often includes personal information scraped from the internet without an individual’s consent. The facial recognition company Clearview AI, for example, built its database by scraping billions of images from platforms like Facebook.[ref 25] This practice has prompted legal challenges, such as a lawsuit alleging that Clearview’s data scraping violated Illinois’s Biometric Information Privacy Act along with privacy laws in several other states, which resulted in a $50 million settlement.[ref 26]
A second privacy risk emerges when users share intimate details with interactive systems like AI chatbots.[ref 27] States are beginning to adapt their privacy laws for this new reality. California’s Assembly Bill 1008, for instance, amends the state’s Consumer Privacy Act (CCPA) to clarify that personal information output by AI systems is covered by existing privacy protections.[ref 28]
Finally, AI serves as a powerful tool for surveillance. For example, by 2023 U.S. police had performed nearly a million facial recognition searches using Clearview AI.[ref 29] In response, several states have enacted limitations on police use of facial recognition. Massachusetts is one of the few states to restrict police use of the technology,[ref 30] while some cities have banned its use by government agencies altogether.[ref 31] The Pentagon-Anthropic dispute was a recent flashpoint around this exact issue.[ref 32]
Regulating AI’s privacy harms presents a paradox. On one hand, the issue may be more tractable than other AI risks because states have spent years developing legal frameworks for data privacy that can be adapted to AI. On the other hand, regulation is uniquely difficult because many of AI’s transformative benefits are tied to its ability to process massive amounts of sensitive data. This creates complex trade-offs, such as balancing the public safety benefits of AI surveillance against individual privacy rights.
D. Economic Harms and Inequality From Automation
The fear that AI will automate jobs, further concentrating wealth and power in the hands of a few private actors, looms over many discussions about the technology.[ref 33] These fears are so significant that Hollywood writers went on strike over the potential threat to their livelihoods,[ref 34] while many illustrators worry about the future of their profession[ref 35] due to advanced image generators like Midjourney, Stable Diffusion, and Gemini and ChatGPT’s image generation features.
Tennessee’s ELVIS Act, which extended an artist’s publicity rights to include AI-generated voice content, is an early attempt at addressing the economic effects of AI and narrowly focuses on entertainment industries.[ref 36] More comprehensive legislation seems unlikely in the near future, particularly as many states have only recently convened AI advisory groups to research and plan for future economic changes.
Lawmakers will likely continue to struggle with mitigating these impacts due to the unpredictability of AI’s future capabilities. Thus far, advancements have been both rapid and uneven.[ref 37] For example, OpenAI’s o1 model marked a sudden and significant leap in large language models’ ability to solve mathematical problems[ref 38]—an area where previous models were heavily criticized for underperformance.[ref 39] More recently, AI coding agents like Claude Code have progressed from autocomplete assistants to autonomous systems capable of writing code with minimal human oversight, disrupting a profession many once assumed was insulated from automation.[ref 40] With AI capabilities advancing this quickly and unpredictably, it becomes increasingly difficult for policymakers to identify which professions are most at risk of automation, let alone determine the appropriate timeline for addressing these challenges.
Yet the potential economic benefits are also massive. In some ways, the worst-case scenario might also be the best-case. The more jobs that are automated by AI, the more powerful the AI system. If these systems do become the functional equivalent of a “country of geniuses in a datacenter,” the economic growth and quality of life improvements can be substantial.[ref 41] And if such benefits can be distributed equitably (an admittedly big if), the economic future enabled by AI can be far better than what exists today.
E. Security Threats
The spectrum of AI-related security threats is broad, ranging from digital vulnerabilities that compromise data and systems to physical dangers that threaten lives and infrastructure. AI can increase the frequency and scale of these incidents both by amplifying existing risks and by introducing entirely new vulnerabilities.
In the cybersecurity domain, AI can be a force multiplier for malicious actors.[ref 42] Large language models can be used to generate sophisticated spear-phishing emails (targeted attacks disguised as legitimate communication) at an unprecedented scale or to automatically detect vulnerabilities in codebases.[ref 43] Beyond amplifying old threats, AI models themselves introduce new attack vectors when integrated into digital services.[ref 44] For example, “indirect prompt injection” vulnerabilities have allowed attackers to take control of a user’s session in a chatbot and steal their conversation history.[ref 45] As more services incorporate these AI tools, such vulnerabilities create new routes for attackers to compromise systems.
The potential for physical threats is also deeply concerning. State actors can use AI to augment intelligence capabilities, deploy more sophisticated weapons like lethal autonomous weapons (LAWs), and enhance their capacity to conduct cyberattacks against critical infrastructure.[ref 46] Furthermore, AI lowers the barrier for non-state actors to access dangerous capabilities, potentially making it easier to develop and deploy chemical, biological, radiological, or nuclear (CBRN) weapons.[ref 47]
Legislative efforts to address these threats have emerged at the state, federal, and international levels. The most prominent state-level proposals have targeted developers of frontier AI models. California’s SB 53[ref 48] and New York’s RAISE Act,[ref 49] signed into law in September and December 2025, respectively, impose largely similar requirements: both require large frontier developers to publish safety frameworks, report critical safety incidents, and face civil penalties for noncompliance. Together, the two laws are beginning to function as a de facto national standard for addressing catastrophic AI risks.
At the federal level, Congress has shown interest in AI’s role in cyberspace,[ref 50] and the Biden administration issued Executive Orders to both accelerate the use of AI in national cyber defense[ref 51] and (in an order since repealed by the Trump administration) to oversee advanced AI development through measures like compute cluster reporting and “Know-Your-Customer” (KYC) requirements for cloud providers.[ref 52] Internationally, forums like the UN Group of Governmental Experts on LAWs have been exploring frameworks to regulate AI in warfare.[ref 53]
Despite these efforts, mitigating security threats remains challenging. A core difficulty is AI’s dual-use nature: the same capabilities that can help people defend and improve systems can also be used to help malicious actors attack them. Organizations are already using AI to detect phishing attempts and patch vulnerabilities, and Microsoft alone blocks tens of billions of threats annually. The difficulty with dual-use is compounded by the fact that safety is not an inherent property of an AI model. Just as an electric motor’s safety depends on its application, an AI model’s potential for harm is context-dependent, making it difficult to assign liability or design proactive, one-size-fits-all regulations. Finally, the sheer technical complexity and vast scale of these systems make designing comprehensive and effective policy interventions an incredibly difficult task.
F. Psychological Harms
Beyond physical, economic, or information-related threats, AI systems have the potential to cause significant psychological harm, particularly among vulnerable populations like children and adolescents.
AI companions and social media algorithms are engineered to maximize engagement through personalized content and simulated empathetic responses, which can lead to excessive use and what some researchers term “addictive intelligence.”[ref 54] Such AI interactions risk supplanting real-world relationships and exacerbating feelings of loneliness and social isolation, even when initially perceived as helpful.[ref 55] Moreover, over-reliance on AI for social connection may impair interpersonal skills, as AI relationships often lack the reciprocity, spontaneity, and nuanced emotional engagement characteristic of human connections.[ref 56]
Children and adolescents are particularly vulnerable to these risks. Multiple recent lawsuits allege that AI chatbot companies’ products have contributed to teen suicides, self-harm, and other psychological harms. Plaintiffs have alleged that chatbots discouraged users from seeking help from parents or professionals, engaged in inappropriate sexual interactions with minors, and encouraged addictive and unhealthy relationships.[ref 57]
States are beginning to pass legislation targeting these harms.[ref 58] Yet enacting laws to mitigate psychological harms creates several distinct challenges. First, identifying psychological harm is difficult: clinical addiction can be confused for high engagement and vice versa. Second, this definitional challenge is confounded by a measurement problem: the platforms suspected of causing harm often exclusively control the behavioral data (such as time on device) necessary to assess that harm. Third, attributing harm directly to AI proves difficult in a landscape where multiple factors influence mental well-being. Fourth, many interventions—especially those targeting algorithmic design or content—raise significant free speech concerns.[ref 59] Finally, effective regulation must balance these harms against AI’s potential psychological benefits, including improved access to mental health support and personalized therapeutic interventions that might otherwise be unavailable.
* * *
Ultimately, this overview of some of the harms of AI is intended to remind policymakers of the importance of deciding what they want to accomplish before deciding how they want to regulate. An added benefit is that it allows policymakers to better understand AI legislation passed in other states. Consider two high-profile AI bills: Colorado’s AI Act (SB 24-205), which targets bias in automated decision systems, and California’s Transparency in Frontier Artificial Intelligence Act (SB 53), which addresses catastrophic risks from frontier AI models. Despite their completely different areas of focus, both are described in media as landmark AI legislation. This missing nuance may lead policymakers to incorrectly believe that they need only pass one omnibus “AI” bill when the reality is they will likely need to pass many AI-related bills to address the technology’s multifaceted harms. Once policymakers know why they want to regulate, the next Part helps them understand how.
II. The How: What Factors Shape Intervention Design?
This part introduces seven factors that should guide policymakers in thinking about where and how to intervene to mitigate AI harms. These factors are not mutually exclusive. A single intervention will implicate multiple principles in ways that might be in tension with each other, which is part of why AI regulation is so difficult. For example, an intervention that encourages the proliferation of open-weight models could mitigate concerns about undue concentration of power (factor 3), while making it harder to limit the offensive capabilities of malicious actors (factor 2) and enforce regulations (factor 5).
A. Harm Prevention (Ex Ante) vs. Harm Response (Ex Post)
Interventions can be distinguished by whether they aim to prevent harms before they occur (ex ante) or respond to harms after they materialize (ex post).[ref 60] Licensing regimes,[ref 61] pre-deployment testing requirements,[ref 62] capability restrictions,[ref 63] and deterrence strategies[ref 64] are more preventive. Incident reporting[ref 65] and content takedown obligations[ref 66] are more responsive. Tort liability has elements of both: it’s responsive in that it awards compensation to harmed parties, but it’s also preventative in that the threat of future sanctions incentivizes companies to prevent those harms in the present. [ref 67]
Whether preventative or responsive interventions are preferable will often depend on the nature of the harm.[ref 68] Preventive interventions are more valuable when harms are difficult or impossible to reverse, such as election interference that cannot be “un-voted”[ref 69] or physical harms that cannot be undone.[ref 70] But preventive interventions require predicting harms in advance and risk being overbroad, which can be difficult for general-purpose technologies like AI that have so many applications. Responsive interventions allow society to learn from harms and calibrate policy accordingly,[ref 71] but they provide cold comfort to those who are harmed as the legal system learns to adapt. An effective regulatory regime will likely need some combination of both.
The speed of harms also bears on the choice between harm prevention and response. Some AI harms materialize rapidly, such as a cybersecurity attack on critical infrastructure or a viral deepfake in the final days of an election, leaving little time to respond. Others occur more slowly: erosion of trust in information or the long-term impacts of a biased AI loans system. For fast-moving harms, ex ante intervention may be essential if ex post remedies arrive too late to matter.
Distributional considerations further complicate the comparison. Ex ante compliance costs are initially borne by developers and typically passed on to consumers. Ex post costs fall first on victims, who must bear the harm and then seek compensation through legal processes that may be slow, expensive, and uncertain. This asymmetry matters especially when AI systems harm people poorly equipped to navigate ex post remedies: individuals without resources to hire lawyers or diffuse groups suffering harms too small individually to justify litigation but significant in aggregate. A regime that relies heavily on ex post liability may systematically undercompensate these populations, even if it works well for well-resourced plaintiffs with clear injuries.
B. Strengthening Defense (Armor the Sheep) vs. Weakening Offense (Defang the Wolves)
Interventions can also be categorized by whether they primarily aim to restrict offensive capabilities (making it harder for bad actors to cause harm) or enhance defensive capabilities (making potential targets more resilient to attack).[ref 72] Export controls and licensing regimes are examples of offensive restriction; they attempt to keep dangerous capabilities out of the “wrong” hands. Investments in cybersecurity infrastructure and early-warning systems are examples of defensive enhancement;[ref 73] they assume adversaries will obtain offensive capabilities and focus on defending against harm.
For some harms, reducing offensive capabilities may be the only viable mechanism. We don’t have defensive approaches to handling the harms created by nuclear weapons, so reducing offensive capabilities through nonproliferation treaties and deterrence strategies is the only viable approach. But offense-reduction strategies are often a double-edged sword: they create incentives for targets to develop workarounds,[ref 74] require centralizing power for enforcement,[ref 75] and can degrade AI’s beneficial capabilities. Because restricting offensive capabilities is difficult[ref 76] and can have undesirable consequences,[ref 77] we recommend that policymakers adopt defense-enhancing strategies for AI where possible.
Defense-enhancing strategies can be both regulatory and technological. Whistleblower protections[ref 78] and incident reporting help companies and regulators identify and respond to harms more quickly.[ref 79] These are legal choices that can improve a jurisdiction’s “resilience” to harms. Vitalik Buterin popularized the technological equivalent with a theory he calls defensive accelerationism (“d/acc”),[ref 80] analogizing to “armoring the sheep” rather than trying to “defang the wolves.”[ref 81] The d/acc movement aims to accelerate the development of defensive technologies. For biosecurity, this might look like installing better HVAC systems or accelerating vaccine development for AI-enabled bioweapons or pandemics. For cybersecurity, this might look like using AI systems like Claude Code or Devin to automatically identify and patch security vulnerabilities.[ref 82] Bernardi et al.’s “Societal Adaptation to Advanced AI” is an excellent primer for thinking about what these defensive strategies might look like.[ref 83]
C. Impact on Concentration of Power
The AI policy community is divided over whether harm mitigation is better served by centralizing or decentralizing the AI ecosystem.[ref 84] This consideration typically runs together with the previous one (ex ante vs ex post harm prevention)[ref 85] because reducing offensive capabilities (model nonproliferation, export controls, etc.) often requires centralizing power for effective enforcement.[ref 86]
The choice between centralization and decentralization is not binary and the considerations differ across layers of the AI stack (see below). At the infrastructure layers (semiconductor supply chain, cloud compute providers), a concentrated chip supply chain can simultaneously create chokepoints useful for export controls and supply-chain vulnerabilities.[ref 87] At the application layer, decentralization enables AI applications tailored to a wide range of specific contexts, though it may complicate efforts to enforce regulations.[ref 88] Policymakers should consider how a given intervention affects concentration at each layer, recognizing that the arguments will vary depending on the layer.
A decentralized ecosystem can improve safety through redundancy and distributed detection of problems. If one developer’s system fails or exhibits unexpected behavior, others may catch the issue.[ref 89] Decentralization also reduces the stakes of any single failure; an error by one of many competitors is likely to be less catastrophic than an error by a dominant player. Yet decentralization can also undermine safety by creating races to the bottom, where competitive pressure leads developers to cut corners on safety investments that don’t translate into market advantage.[ref 90] Fragmented oversight becomes harder when regulators must monitor dozens of developers, and coordination on shared safety standards grows more difficult as the number of actors multiplies.
Concentration also implicates separate questions about industrial policy. Tim Wu has argued that highly concentrated industries develop outsized lobbying power and capture regulators.[ref 91] On this view, the concern is not merely that a few AI developers might build unsafe systems, but that they might accrue sufficient political influence to weaken the oversight meant to constrain them.[ref 92] At the same time, concentration intersects with industrial policy objectives and anxieties about geopolitical competition. Policymakers who worry about competition with China may favor cultivating “national champions:” a small number of well-resourced domestic firms capable of matching foreign competitors.[ref 93]
Each of the interventions discussed in this primer can be located on a spectrum from promoting centralization to decentralization, and policymakers should consider not only which end of that spectrum aligns with their beliefs about AI risk, but also how concentration at different layers of the stack interacts with the offense-defense balance and enforcement.
D. More Upstream Interventions are More Blunt
The amount of context needed to identify a harm will influence where in the ecosystem (see below) to intervene. Upstream interventions (Stages 1–3) are often better suited for context-independent harms because they can restrict capabilities without needing to evaluate specific uses.[ref 94] Downstream interventions (Stages 4–6) are often better able to address context-dependent harms because deployers and users have more information about how AI is actually being used.[ref 95]
Truly context-independent harms are rare since many AI capabilities are dual-use. The same capacity that generates phishing emails also drafts legitimate marketing copy. The same image capability that can produce nonconsensual intimate imagery creates art. Even capabilities that seem clearly dangerous often sit on a spectrum: a model’s ability to discuss virology in detail could facilitate bioweapon development or accelerate vaccine research depending on who is using it and why.[ref 96] But it’s still a useful principle. Some harms are identifiable without knowing much about the circumstances in which AI is used. The production of child sexual abuse material, for instance, is harmful regardless of context. Other harms depend heavily on context: whether a piece of AI-generated content constitutes misinformation, satire, or parody depends on how it is distributed and received.
Downstream interventions can be more precisely targeted, restricting specific uses while leaving others untouched.[ref 97] A platform can prohibit using its AI tools for generating political advertisements without restricting political speech more broadly. A deployer can implement know-your-customer requirements that screen out bad actors while permitting legitimate users. But this precision comes at a cost: downstream interventions often require the capacity to monitor and evaluate specific uses, which may be practically difficult at scale, may require centralization (see above), and shift enforcement burdens to actors who may lack the resources or incentives to implement them effectively.[ref 98]
E. Enforcement Feasibility (Certainty vs. Severity of Penalties)
Traditional enforcement through the legal system requires identifiable defendants within a jurisdiction who can be compelled to pay damages or serve sentences.[ref 99] When these conditions are met, interventions targeting applications and users can be highly effective because they address harms where they occur.
But many AI-related harms involve actors who are difficult or impossible to reach through traditional enforcement: foreign adversaries, anonymous bad actors, autonomous AI systems, or diffuse harms for which no single defendant is responsible. In these situations, compute governance (Stages 1–2) becomes more valuable because it operates through chokepoints—concentrated infrastructure that can be controlled even when end users cannot be.[ref 100]
Policymakers assessing enforcement feasibility should consider three questions. First, can compliance be observed?[ref 101] Some requirements are relatively easy to verify (e.g., whether a model has been submitted for pre-deployment review, whether a chip shipment crossed a border). Others are harder to monitor (e.g., whether a company’s internal safety practices match its public commitments). When compliance is difficult to observe, enforcement depends on whistleblowers, audits, or investigations, which are more resource-intensive yet less complete.[ref 102]
Second, who will enforce? Regulatory requirements need an agency with the statutory authority, technical expertise, and budget to monitor compliance and pursue violators.[ref 103] If that agency doesn’t exist or is underfunded, requirements may go unenforced.
Third, what are the consequences for non-compliance, and are they sufficient to deter? A small fine may be treated as a cost of doing business; a large fine may deter only if the probability of detection is meaningful. An important note is that the certainty of apprehension and punishment matters far more than the severity of punishment for deterrence.[ref 104] For AI governance, this implies that investing in monitoring and detection infrastructure may be more valuable than increasing statutory penalties.[ref 105] It also suggests that highly publicized enforcement actions, which increase the perceived certainty of consequences, may matter more than their direct effects on the individual defendants involved.
Market structure also shapes which tools are feasible. When an industry is concentrated, regulation is more tractable: fewer entities to monitor, greater compliance capacity, and reputational stakes that give enforcement actions bite.[ref 106] When an industry is fragmented, direct regulation may be impractical, pushing policymakers toward upstream chokepoints or tools like liability that don’t require entity-by-entity oversight. When entry barriers are low, regulations binding only incumbents may simply shift activity to less scrupulous providers.
F. Allocating Responsibility to the Least-Cost Avoider
A foundational principle of tort law holds that liability for a harm should be assigned to the party who can most cheaply and effectively prevent it: the “least-cost avoider.”[ref 107] This principle provides useful guidance for allocating responsibility across the AI ecosystem.[ref 108]
In practice, identifying the least-cost avoider is contested. Consider an AI system that generates plausible-sounding medical misinformation that a user then relies upon.[ref 109] Is the least-cost avoider the developer (who could have trained the model to be more cautious about medical claims), the deployer (who could have added guardrails or warnings), the platform that distributed the content (who could have labeled or filtered it), or the user who relied on it without verification? Each could have prevented the harm at some cost, and reasonable people will disagree about which intervention was cheapest or most effective (not to mention the contested normative question of who “ought” to have prevented the wrong).
The principle nevertheless provides a useful starting point: for harms resulting from unpredictable system failures (such as hallucinations), developers and deployers may be best positioned to invest in prevention because they are best positioned to build the scaffolding necessary to protect an AI system. For harms resulting from intentional misuse by end users, this principle may suggest focusing on the end user because they choose whether and how to deploy AI for harmful purposes.[ref 110] For harms that are harmful regardless of context (like CSAM generation), joint and several liability across the production chain may be appropriate to ensure all parties have incentives to prevent it.[ref 111]
G. Is Regulation the Right Tool?
Finally, policymakers should ask whether regulation is the right intervention at all. It is one tool among many, and depending on the type of harm, other interventions may be more effective.
Consider the range of alternatives. Investing in and adopting defensive technologies (like the kind described in subsection 2), for example, may be more effective in reducing cybersecurity vulnerabilities than regulation mandating cybersecurity best practices. Technical standards development, whether led by industry or the government, can also establish shared benchmarks for safety, interoperability, and performance that influence behavior.[ref 112] Government procurement power can shape markets as companies compete on the metrics set by federal agencies for what they will purchase.[ref 113] Antitrust enforcement (with remedies like divestiture) may address some concentration of power problems that regulation does not. And as consumers grow more sophisticated in evaluating AI products, market pressure alone may discipline some harms without the need for regulatory intervention.
Enforceability should weigh heavily in this assessment (discussed in subsection 5). Different tools require different enforcement capacities, and an intervention that cannot be meaningfully enforced may be worse than no intervention at all, creating the illusion of oversight while harmful practices continue or burdening compliant actors while bad actors ignore requirements.
Ultimately, the question is both “which actor should we target?” and “what kind of intervention is most likely to work?” Policymakers should not rush past these questions by assuming regulation is the solution to every problem.
III. The Where: Which Actor in the AI Ecosystem Does the Intervention Target?
The path from silicon chip to real-world harm is filled with actors that could prevent those harms. This primer organizes actors in the AI ecosystem into seven stages based on their role in the AI ecosystem: (1) chip designers and manufacturers, (2) cloud compute providers, (3) data suppliers, (4) model developers, (5) application deployers, (6) complementary and enabling platforms, and (7) end users. Each set of actors offers a potential leverage point for intervention.
These stages do not map neatly onto corporate structures: a single company can span multiple categories. Google, for example, functions as a cloud provider (Google Cloud), data supplier (via YouTube), model developer (Google DeepMind), and application deployer (Gemini). The purpose of this framework is to help policymakers regulate by the role an entity plays in the causal chain from the creation of an AI system to the materialization of harm, regardless of who performs each function.
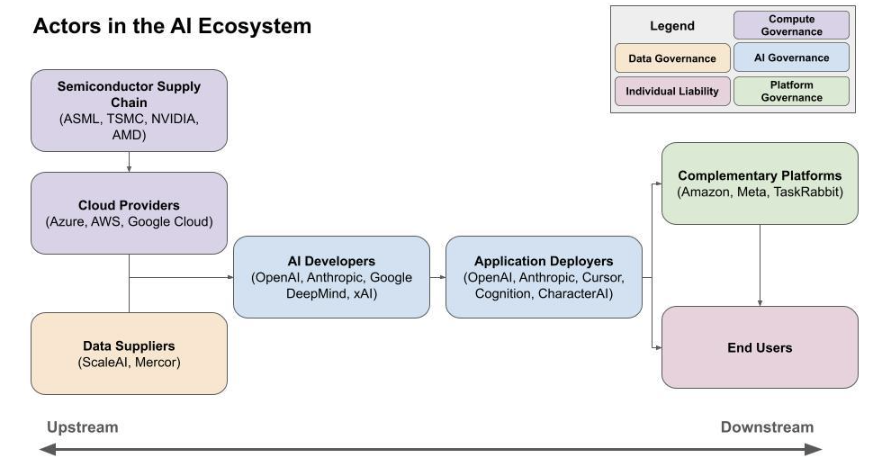
A. Stage 1: Chip Designers and Manufacturers
The semiconductor supply chain is a key intervention point for shaping AI’s development and deployment. Training and running advanced AI systems requires specialized semiconductors like Application-Specific Integrated Circuits (“ASICs”) or Graphics Processing Units (“GPUs”). These chips are designed by a handful of companies (mostly NVIDIA, AMD, Google) and produced by an even smaller number of foundries (mostly TSMC) using manufacturing equipment (extreme ultraviolet (“EUV”) lithography machines) from a single supplier (ASML). This market concentration creates chokepoints that policymakers can leverage for policy enforcement.[ref 114]
Examples of Policy Interventions
Export controls on AI chips. The U.S. government’s primary tool for shaping international AI development thus far has been export controls on advanced semiconductors, first announced in late 2022 and updated several times since.[ref 115] This policy is in flux as the Trump administration has flip-flopped on export controls for advanced AI chips to China. The most recent announcement was that NVIDIA can sell its advanced H200s to China.[ref 116]
Compute infrastructure disclosure requirements. The Biden Administration’s 2023 AI executive order (since rescinded) required entities acquiring or possessing large-scale computing clusters to report their existence, location, and total computing capacity to the government.[ref 117] This was intended to give policymakers visibility into the physical infrastructure being assembled for advanced AI training.
On-chip governance mechanisms. Researchers have proposed adding technical components to chips that would give regulators visibility into large training runs without compromising AI companies’ commercial interests.[ref 118] Though requiring further research into technical feasibility, verification mechanisms have been a prerequisite for international cooperation in other domains (like nuclear nonproliferation) and may be just as valuable for AI governance.[ref 119]
Advantages of Targeting This Stage
Focusing policy interventions on semiconductor companies has four key advantages: excludability, quantifiability, detectability, and enforcement feasibility.[ref 120]
First, computing resources are excludable because people can be prevented from accessing them. Unlike data or algorithms, which are easily copied and shared, there are a finite number of operations that a single GPU can perform. If one actor is fully utilizing those operations, no one else can.
Second, compute is quantifiable—it “can be easily measured, reported, and verified” in terms of the operations per second a chip can perform or its communication bandwidth with other chips.[ref 121]
Third, large-scale training runs are detectable. The most advanced AI models currently require large-scale training runs using thousands of specialized chips concentrated in power-intensive data centers. These facilities are detectable by third parties, with some visible from satellite imagery.
Finally, the semiconductor supply chain is extraordinarily concentrated, making enforcement feasible.[ref 122] NVIDIA controls 80-95% of the market for AI chip design; TSMC fabricates approximately 90% of advanced chips; ASML supplies 100% of the extreme ultraviolet lithography machines used by leading foundries. This concentration makes the other three advantages actionable: fewer actors makes monitoring and enforcement easier.[ref 123]
Disadvantages of Targeting This Stage
Despite these advantages, semiconductor-focused interventions have three significant drawbacks: they rely on an assumption that may not hold, they are blunt and they become less effective the more they are used.
First, semiconductor-focused regulation relies on compute serving as an effective proxy for capability. If AI performance improves such that less-than-state-of-the-art models become capable of serious harm, or if algorithmic efficiency gains reduce the compute needed for dangerous capabilities, then semiconductor-focused interventions will miss their intended target.[ref 124] Additionally, as Arvind Narayanan and Sayash Kapoor have argued, “AI safety is not a model property,” since whether an output is harmful depends on context, and capability restrictions are thus, although laudable, a misguided approach.[ref 125]
Chip-level interventions are also among the bluntest available.[ref 126] Because semiconductors are general-purpose inputs, restrictions at this stage cannot distinguish between beneficial and harmful uses of AI. Export controls that limit access to advanced chips, for example, constrain medical research and climate modeling just as much as they constrain weapons development or surveillance. Policymakers targeting this stage risk throttling AI development altogether rather than surgically addressing specific harms.
Finally, semiconductor interventions are valuable in the short term but potentially counterproductive in the long-term. On-chip governance mechanisms and export controls, while potentially controlling how chips are used or limiting adversaries’ access to them in the short term, encourage investment in alternatives. On-chip restrictions could push buyers toward more open alternatives produced in other jurisdictions. Some have argued U.S. export controls benefit China’s semiconductor industry by encouraging further investment,[ref 127] though others believe such indigenization fears are overblown.[ref 128] And geopolitical competition may prevent countries from regulating their own semiconductor industries at all, for fear of ceding a competitive edge. Finally, compute-based restrictions may encourage innovation that renders compute less likely to be a bottleneck in the future. For example, DeepSeek’s efficiency may be an unintended consequence of limiting Chinese firms’ access to computing resources, with compute constraints forcing researchers to develop more efficient algorithms.
Summary
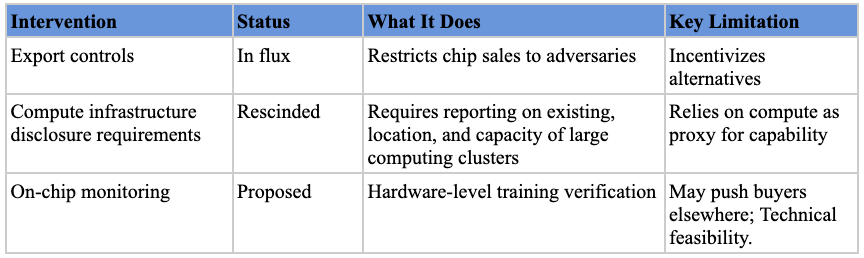
Semiconductor-based interventions are a powerful policy tool. They work best for harms that are identifiable without much context, where a single malicious actor’s access to advanced capabilities increases risk regardless of how they’re used. They are particularly valuable when traditional enforcement is impractical—against foreign actors, in situations involving diffuse harms, or when agencies cannot possibly monitor all end users. But policymakers should be aware that these interventions are a blunt instrument that incentivize workarounds, and they depend on compute remaining a bottleneck for dangerous capabilities.
B. Stage 2: Cloud Compute Providers
A handful of cloud computing providers—Amazon Web Services, Microsoft Azure, and Google Cloud—operate the computing infrastructure used by most developers to train and deploy AI models. Because this stage and the previous one both focus on the computational resources underpinning advanced AI, they share many characteristics and are often grouped together under the general heading of “compute governance.” This section focuses on the ways in which targeting cloud providers differs from targeting the semiconductor supply chain.[ref 129]
Examples of Policy Interventions
Know-Your-Customer (KYC) requirements. Efforts to impose KYC obligations on cloud providers date back to Trump’s first-term EO 13984 (2021),[ref 130] which Biden’s EO 14110 (2023)[ref 131] later expanded with AI-specific reporting mandates. Providers would be required to notify the government when foreign actors access computing resources above certain thresholds, aiming to prevent adversaries from anonymously using U.S. infrastructure for dangerous AI development.
Cybersecurity compliance and AI safety standards. In 2024, the Commerce Department’s Bureau of Industry and Security (BIS) proposed rules requiring cloud providers and their clients to report on frontier AI development activities, including compliance with cybersecurity frameworks and results of mandatory red-teaming tests.[ref 132] This would leverage cloud providers as enforcers to ensure hosted AI projects meet security benchmarks.[ref 133]
Government oversight of frontier AI training. Some researchers have recommended requiring licenses for AI training that exceeds certain compute thresholds.[ref 134] Cloud providers would require government approval before allowing training runs capable of producing frontier models—resembling licensing in the aerospace and nuclear energy industries.
Advantages of Targeting This Stage
Cloud computing shares the same fundamental advantages as semiconductor governance—concentration, excludability, quantifiability, and detectability—but offers additional benefits for regulators.
First, cloud providers’ business models already require extensive monitoring. Because they charge customers based on usage, they precisely measure resource consumption through metrics like floating-point operations, GPU hours, and energy consumption. This existing infrastructure can be repurposed for regulatory compliance with less added burden.
In addition, unlike the semiconductor supply chain, which is distributed across the United States’ allied nations, including the Netherlands, Japan, and Germany, the world’s largest cloud providers are headquartered in the United States. This gives American policymakers more jurisdictional flexibility in designing and enforcing regulations.[ref 135]
Cloud providers can also respond to non-compliance immediately. Unlike semiconductor restrictions, where there is a lag between placement on an export control list and actual business disruption, cloud access can be revoked in real time (similar to how banks can freeze accounts). This makes cloud-based enforcement more like financial regulation than trade regulation.
Disadvantages of Targeting This Stage
Cloud provider interventions share the two core weaknesses of semiconductor controls and add a third.
Like semiconductor interventions, cloud-based regulation relies on the assumption that advanced AI requires access to large compute clusters. If algorithmic efficiency improves enough that dangerous capabilities can be achieved with modest resources, then cloud-focused controls will miss their target.
Cloud restrictions also risk sparking the same kind of workarounds and indigenization that undermine export controls. Developers facing extensive compliance requirements may switch to less-regulated providers in other jurisdictions, and countries seeking AI independence or “sovereignty”[ref 136] may invest in domestic cloud infrastructure precisely to escape U.S.-based oversight. The more effective cloud controls are in the short term, the stronger the incentive to route around them in the long term.
Finally, cloud interventions also raise concerns that detailed tracking of activity on clients’ servers could expose information that companies treat as trade secrets like training techniques.[ref 137] And broad authority to cut off companies’ access to computing resources creates potential for abuse, as officials might target companies disfavored by the governing party or use access as leverage for purposes beyond AI safety.
Summary

Cloud provider interventions function as a more responsive version of semiconductor controls—enforcement can happen immediately rather than through supply-chain disruption. They are particularly valuable when real-time response matters or when tracking the identity of AI developers (rather than just their capability) is important. However, they come with greater privacy trade-offs and the same diminishing-returns problem as other compute governance approaches.
C. Stage 3: Data Suppliers
AI models are trained on data sourced from many entities: large-scale web scrapers (like C4), crowdsourced platforms (like Amazon Mechanical Turk), and specialized data labeling companies (like ScaleAI and Mercor).[ref 138] The goal of data-supplier-focused interventions is to improve the upstream collection and quality of AI training data to reduce downstream harms.[ref 139]
Examples of Policy Interventions
Individual data rights. Several states require data brokers to register with the government and disclose details about the data they collect, how it’s used, and their sharing practices. California’s Delete Act aims to allow residents to request deletion of their personal information from data brokers through a single request.[ref 140] Illinois’s Biometric Information Privacy Act (BIPA) requires opt-in consent for entities collecting biometric data,[ref 141] significantly affecting AI facial recognition training. With AI, honoring these rights may involve removing data from supplier databases, retraining models, or filtering outputs traceable to deleted data, though the FTC has ordered complete model deletion in cases of egregious data misuse.[ref 142]
Collective licensing and compensation mechanisms. John Axhamn has proposed an “Extended Collective Licensing (ECL)” scheme that would allow AI developers to legally train on copyrighted works while ensuring rightsholders receive compensation.[ref 143] A Congressional Research Service report discusses these frameworks as potential solutions to the tension between AI training and intellectual property rights.[ref 144]
Public datasets. Governments and research institutions could create and maintain high-quality public datasets. The Trump administration’s Genesis Mission is an attempt to unify federal scientific archives into a centralized, standardized platform, democratizing AI development for smaller companies and academic researchers who lack resources to develop proprietary datasets.[ref 145]
Advantages of Targeting This Stage
Addressing data quality and legality at the point of collection and aggregation can prevent problems from multiplying as models are deployed.[ref 146]
Many data supplier regulations align with existing privacy laws like GDPR and CCPA.[ref 147] This allows policymakers to build on established definitions, enforcement mechanisms, and compliance infrastructure rather than creating entirely new regulatory regimes.
The data broker[ref 148] and AI data labeling[ref 149] industries are also relatively concentrated, allowing authorities to oversee a significant portion of data flowing into AI systems by regulating a manageable number of entities.
Disadvantages of Targeting This Stage
Data suppliers can operate globally, potentially sourcing data from or locating servers in jurisdictions with weaker regulations. AI developers might bypass rules by using offshore brokers or scraping data outside the state’s reach.[ref 150]
Defining who qualifies as a regulated “data supplier” is also difficult.[ref 151] Rules could be too narrow (missing web scrapers) or too broad (burdening nonprofits like Wikipedia or individual bloggers). And compliance costs may further consolidate the market around larger players who can afford them.
Finally, regulations restricting collection, sale, or use of data may face First Amendment challenges. The Supreme Court’s decision in Sorrell v. IMS Health held that the “creation and dissemination of information are speech,” meaning data regulations can potentially trigger heightened constitutional scrutiny.[ref 152]
Summary

Data supplier regulations are most useful for harms directly linked to data inputs—privacy violations, copyright infringement, and biased training data—and where key data sources are concentrated and identifiable. They also benefit from alignment with existing privacy frameworks like GDPR and CCPA. They are less effective when data is highly diffuse, when suppliers operate across jurisdictions, or when defining the scope of regulated entities is difficult.
D. Stage 4: AI Model Developers
This stage focuses on organizations that research, develop, and train large-scale AI models—entities like OpenAI, Anthropic, Google DeepMind, Meta AI, and xAI. Given their central role in developing core AI capabilities, model developers are frequent targets for policy intervention.[ref 153]
Examples of Policy Interventions
Transparency and Disclosure Mandates. The most common type of intervention at the state level promotes transparency through disclosure requirements.[ref 154] These can take several forms: requiring companies to publish reports on model development and testing processes; mandating watermarks or content provenance techniques to label AI-generated content; creating whistleblower protections for AI lab employees; and establishing incident reporting requirements for significant safety events.
Testing, Design, and Oversight Requirements. These interventions focus on ensuring safety through design mandates and ongoing oversight.[ref 155] They might include ex ante design features (cybersecurity safeguards, content filtering, “kill switches”), standardized pre-deployment evaluations, red-teaming by internal safety experts,[ref 156] or third-party audits by civil society organizations (like METR) or government agencies (like the UK AISI or US CAISI).[ref 157]
Liability frameworks. Policy researchers have advocated holding model developers liable for harms caused by their systems.[ref 158] California’s SB 53, for example, authorizes the state Attorney General to bring civil actions against developers for failure to report safety incidents or comply with their own frameworks, with damages up to $1,000,000.[ref 159] Insurance requirements could complement direct liability by ensuring compensation is available and creating actuarial signals about the riskiest models.[ref 160] For catastrophic risks, policymakers could consider ex ante mechanisms like mandatory liability insurance or industry-wide compensation funds, modeled on frameworks like the Price-Anderson Act for nuclear accidents.[ref 161]
Advantages of Targeting this Stage
Transparency measures are among the least controversial categories of model developer regulation.[ref 162] Even experts who disagree about the speed and shape of AI risks often agree on the need for more transparency.[ref 163] The rationale is that disclosure empowers users, researchers, and regulators to make informed decisions—if people know how a model was created and tested, they can better assess its reliability and risk.
Testing and oversight requirements can target vulnerabilities in base models that propagate to downstream applications. If a foundation model has a security vulnerability or can be tricked into revealing training data, applications built on top of it can inherit those vulnerabilities.[ref 164] It also leverages technical expertise outside government: regulators can set standards and review results while outsourcing the highly technical evaluation process to specialists.[ref 165]
Finally, liability incentivizes developers to prevent harms by requiring them to pay for damage caused by their models. Liability forces companies to internalize externalities rather than shifting costs to users or society. It also can function as a floor of legal protection, with some egregious AI harms likely falling within the scope of existing tort law.[ref 166]
Disadvantages of Targeting this Stage
Transparency requirements carry their own risks. Detailed disclosures about training data or architectures could expose trade secrets, allowing competitors (including foreign actors) to free-ride on research investments. Watermarking faces technical feasibility concerns: determined actors can remove watermarks, and open-source models that don’t apply them will remain unlabeled. And in the United States, compelled disclosure requirements may face First Amendment challenges as compelled speech.[ref 167]
Oversight requirements face a different problem: defining “safe enough” is extremely difficult. AI systems can fail in unpredictable ways, and any set of evaluations risks missing novel failure modes. Worse, developers might learn to game required tests, tuning models to pass evaluations without truly improving safety.[ref 168] Extensive testing requirements can also slow innovation and concentrate the market as larger, well-resourced companies absorb compliance costs more easily.
Finally, liability is limited by the fact that many AI harms are not within developers’ sole control. AI systems are general-purpose tools used in countless contexts far removed from what creators envisioned. If an open-source model is integrated into hundreds of applications, it may be unfair to blame the model’s creators for a particular application’s failure or a user’s misuse. Defining “reasonable care” for AI, determining causation when multiple actors are involved, and apportioning liability (joint and several vs. proportional) all present difficult legal questions.[ref 169] Liability also functions best when wrongdoers can afford to pay; when the defendant lacks resources or the harm is too large, liability does not fully compensate victims and is a less effective deterrent.
Summary
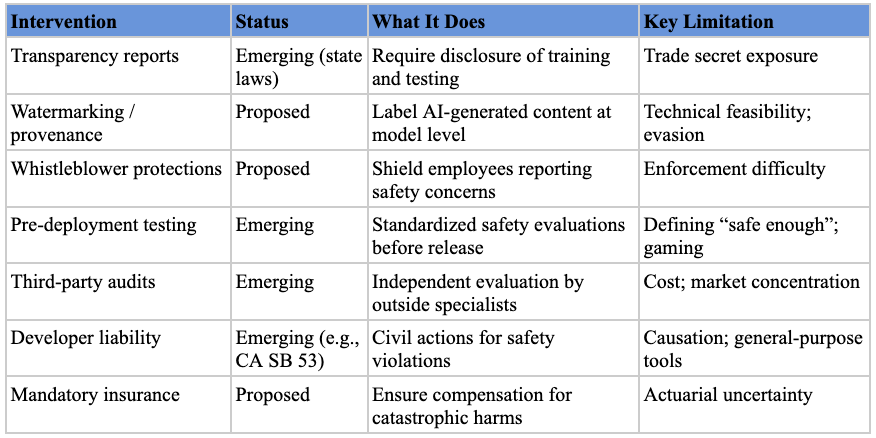
Model developers are a natural focal point for AI regulation because they control the foundational capabilities on which downstream applications depend. Transparency requirements enjoy the broadest support and face the lowest political barriers, though they must be designed to avoid exposing proprietary information. Testing and oversight requirements can catch vulnerabilities before they propagate downstream, but they must be iteratively adjusted as capabilities evolve—static evaluations will quickly become obsolete. Liability frameworks complete the picture by internalizing costs, but their effectiveness depends on resolving difficult questions about causation, apportionment, and the financial capacity of defendants to pay for harms their models enable.
E. Stage 5: Application Deployers
The application layer is where AI capabilities are operationalized into products and services. The entity developing the model can also be the deployer (OpenAI’s ChatGPT is built on its GPT models), but different companies can also build applications on top of models developed by others. Applications span nearly every sector: predictive algorithms for employment screening (HireVue, Pymetrics) and criminal justice risk assessments (COMPAS); generative models powering chatbots (Character.ai) and coding environments (Cursor); and agentic systems capable of completing tasks without human intervention (Claude Code, Devin).
Examples of Policy Interventions
Incident reporting. When AI applications malfunction or cause harm, rapid disclosure enables regulators and the public to identify patterns and respond before problems spread. Analogous requirements exist across regulated industries: the FDA mandates adverse-event reporting for medical devices, NHTSA requires crash reporting for autonomous vehicles, and the FAA tracks near-miss incidents in aviation. Extending this model to AI deployers would require companies to notify a designated agency when their systems produce significant failures—whether a hiring algorithm systematically excludes qualified candidates or a medical diagnostic tool generates dangerous misdiagnoses. The core difficulty is defining what counts as a reportable “incident” for general-purpose AI systems that operate across diverse contexts.
Tort liability. Application deployers are also potential targets for liability.[ref 170] Injured parties can sue the deployer for compensation if a particular application causes harm. One mother, for instance, sued Character.AI over her son’s suicide, alleging design defects.[ref 171] In a separate case, the parents of a sixteen-year-old sued OpenAI, alleging that ChatGPT acted as a “suicide coach” that encouraged their son’s suicidal ideation.[ref 172] The possibility of liability creates incentives to build safe products. Legislatures can play an important role in ensuring this system functions well. California’s AB 316, for example, is a recently enacted bill that aims to ensure there is no AI exception to existing tort liability frameworks.[ref 173] It prevents defendants from disclaiming responsibility by arguing that an AI agent acted autonomously.[ref 174] Legislatures could also codify duties of care rather than leaving courts to define them through the common-law process.
Age restrictions. These provisions require deployers to implement age-appropriate design for systems used by minors, including limiting data collection, obtaining parental consent, and requiring plain-language explanations. Texas’s SCOPE Act (2024) offers a comprehensive template: it requires parental consent before minors can create accounts, prohibits in-app purchases and geolocation tracking for minors, bans targeted advertising to children, and mandates content filtering for material promoting self-harm, substance abuse, or exploitation.[ref 175] This approach is valuable because it shifts the compliance burden onto platforms rather than parents, creating structural protections that don’t depend on individual digital literacy or vigilance.
Self-exclusion. These statutes require deployers to build protective features into products—such as session caps, break reminders, and disabling infinite scroll—that help users limit their own consumption. The UK Gambling Commission’s “reality check” regulations provide a direct model:[ref 176] operators must display recurring on-screen reminders of elapsed session time that users must actively acknowledge before adding new funds,[ref 177] and the UK has banned autoplay features entirely while mandating time intervals between interactions.[ref 178] This framework is valuable because it acknowledges that willpower alone may be insufficient against products engineered for engagement, and it creates friction that can help users close the gap between what they want and what they want to want.
Outright bans. In contexts where AI is deemed too dangerous, policymakers might prohibit its use entirely. The U.S. Space Force temporarily banned generative AI based on security concerns.[ref 179] Several cities have banned law enforcement use of facial recognition based on privacy concerns.[ref 180] Illinois recently banned AI therapy chatbots out of concern for user safety.[ref 181] Recently proposed legislation in Tennessee would make it a felony to train a language model to “provide emotional support, including through open-ended conversations with a user.”[ref 182]
Advantages of Targeting This Stage
Regulating at the application layer gives lawmakers maximum context about AI-related harms. Because deployers operate in defined settings, regulators can set outcome-oriented requirements (i.e., maximum error rates for medical diagnosis or bias thresholds for hiring) and verify through real-world data that requirements are reducing harms.
This approach strongly aligns with existing regulatory expertise. Sector agencies like the FDA, NHTSA, EEOC, and SEC already police safety and integrity within their domains. Extending their mandates to cover AI-enabled products leverages existing staff, testing protocols, and enforcement tools. In many cases, new legislation may not be required because existing sector-specific laws and agency authorities can be applied to AI.
Disadvantages of Targeting This Stage
Effective application-layer intervention requires coordinating across many industries, each with its own stakeholders and lobbyists who may resist oversight. While sector-specific legislation may be more precise, policymakers may prefer omnibus “AI bills” for political reasons, since a single high-profile bill can yield greater electoral rewards than piecemeal legislation.
Even with political will for sector-specific regulation, different agencies crafting different rules creates fragmentation. AI applications that don’t fit neatly into existing categories may slip through gaps. Products crossing regulatory boundaries—a health chatbot handling both insurance questions and medical advice—may face overlapping or conflicting obligations.
A further concern is regulatory capture. Sector regulators develop close relationships with the industries they oversee; over time, this can blunt enforcement or slow rule updates as technology evolves.
Summary
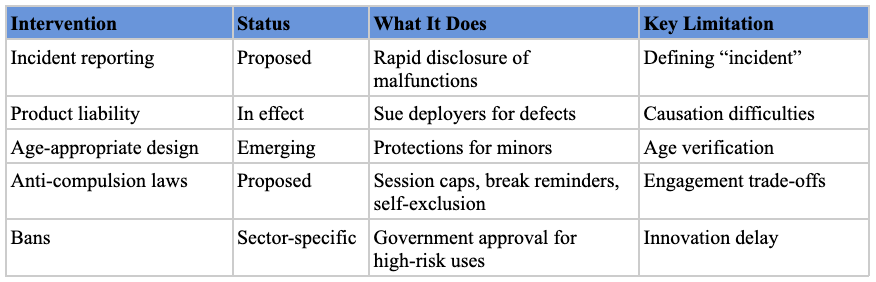
The application layer is one of the most promising regulatory targets because deployers operate in concrete settings where harms are observable and measurable, and because many enforcement agencies—the FTC, EEOC, FDA, NHTSA—already have authority to regulate AI-related activities without new legislation. It is less effective when products span multiple regulatory domains, creating gaps and inconsistencies between agencies.
The least-cost-avoider principle is useful here: deployers who control application design and the context in which AI capabilities reach users should bear responsibility for design flaws and foreseeable failures, while liability for sophisticated misuse that deployers could not reasonably anticipate or prevent should shift to end users.
F. Stage 6: Complementary and Enabling Platforms
Platforms are often essential for translating digital outputs into real-world consequences. E-commerce marketplaces like Amazon facilitate physical goods purchases; gig economy platforms like TaskRabbit connect requesters with workers who perform physical tasks; social media networks like Meta distribute content to mass audiences. While these platforms may not develop AI themselves, they can serve as essential channels through which AI-enabled harms materialize. A language model requires access to enabling infrastructure to purchase precursor chemicals, hire a courier, or broadcast disinformation.
This intermediary role makes enabling platforms uniquely important for AI governance. They represent the last major chokepoint before harm occurs, operating at the boundary between digital intent and physical or social consequence.
Examples of Policy Interventions
E-commerce and Procurement Platforms
Know-Your-Customer and suspicious activity reporting. Platforms could be required to verify purchaser identities for certain categories of goods (chemicals, laboratory equipment, dual-use materials) and report suspicious purchasing patterns to relevant authorities, similar to banking regulations under the Bank Secrecy Act.[ref 183]
AI-aware transaction monitoring. As AI agents gain the ability to autonomously browse and purchase goods, platforms may need new detection mechanisms. Jonathan Zittrain has proposed that AI agents carry identifying credentials—akin to “license plates”—that would allow platforms to apply heightened scrutiny to agent-initiated transactions, particularly for sensitive goods categories.[ref 184]
Gig Economy and Labor Platforms
Task screening and identity verification. Platforms like TaskRabbit, Fiverr, and Upwork could be required to maintain explicit prohibitions on tasks that facilitate illegal activity—delivering unknown substances, conducting surveillance, accessing restricted areas—and to require enhanced identity verification for task categories with higher abuse potential.
Worker protection and refusal rights. Gig workers may be unwitting participants in harmful schemes.[ref 185] Regulations could guarantee workers the right to refuse suspicious tasks without penalty and require platforms to maintain reporting channels for workers who suspect they are being used for illicit purposes.[ref 186]
Social Media and Content Distribution Platforms
Synthetic content labeling requirements. Building on recent state laws, policymakers could mandate that AI-generated content be labeled when distributed on social media,[ref 187] including technical standards for embedded metadata (such as C2PA provenance standards)[ref 188] and disclosure requirements for accounts that post primarily AI-generated content.[ref 189]
Amplification accountability. Beyond content moderation, platforms could face obligations related to algorithmic amplification—transparency requirements for recommendation algorithms, prohibitions on amplifying content that violates platform policies, or duties to detect coordinated inauthentic behavior.
Section 230 reform. The most significant potential intervention involves modifying Section 230 of the Communications Decency Act, which currently immunizes platforms from liability for user-generated content.[ref 190] Reform proposals range from narrow carve-outs (removing immunity for algorithmically amplified content) to broader conditions (requiring reasonable content moderation as a prerequisite for immunity).[ref 191]
Advantages of Targeting This Stage
These platforms represent the final major chokepoint before harms materialize. Even if upstream interventions fail, enabling platforms can still prevent the final step. A bioweapon cannot be synthesized without ingredients; an influence campaign cannot succeed without distribution.
Additionally, unlike AI-specific entities, enabling platforms already operate under extensive regulatory frameworks (e.g., consumer protection laws, export controls, anti-money-laundering rules). Extending these frameworks to address AI-enabled harms leverages established compliance capabilities.
Finally, platform intermediation creates records that facilitate both ex ante screening (flagging suspicious patterns) and ex post investigation (reconstructing how harm materialized).
Disadvantages of Targeting This Stage
The sheer volume of platform activity is the first challenge. Major platforms process billions of transactions.[ref 192] Any screening system will produce false positives and false negatives; at scale, even low error rates translate into millions of affected transactions.
Even with effective screening, platforms often cannot determine whether a transaction is AI-enabled. Without reliable signals distinguishing human from agent activity, platforms cannot easily apply differential scrutiny.[ref 193] Requiring AI disclosure depends on the honesty of precisely those actors least likely to comply when pursuing harmful ends.
Content-related interventions face an additional obstacle. For social media platforms, content-based regulations face significant constitutional scrutiny under the First Amendment. Requirements to remove or label certain categories of speech must be narrowly tailored to compelling government interests.
Finally, users seeking to evade restrictions can shift to less-regulated platforms, international services, or decentralized alternatives like cryptocurrency marketplaces or federated social networks.
Summary
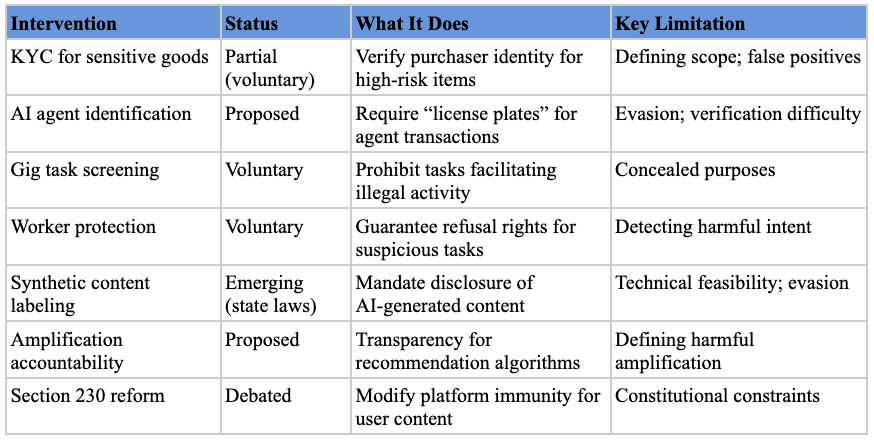
Enabling platforms are most valuable as intervention targets when harms require real-world resources or distribution that platforms mediate. They are the last major chokepoint where harms can be intercepted, and they benefit from existing compliance infrastructure that can be extended to AI-specific concerns. Platform-level interventions are less effective when users can easily shift to unregulated alternatives; they also face significant First Amendment constraints for content-related regulations. The least-cost-avoider principle suggests platforms should bear responsibility for harms they are well-positioned to prevent: suspicious purchasing patterns, task requests that facially violate policies, and content that clearly meets removal criteria. But platforms are not well-positioned to prevent harms requiring information they lack or judgment calls they cannot reliably make at scale.
G. Stage 7: End Users
End users are the final actor in the AI ecosystem. Institutional users like businesses and government agencies embed AI tools into existing workflows, often under sector-specific laws. Individual users typically lack formal compliance programs or resources to vet AI systems, yet their choices can still inflict measurable harm and are subject to liability under the tort system.[ref 194]
Examples of Policy Interventions
Organizations Using AI
Human oversight requirements. These require qualified people to oversee or override AI predictions.[ref 195] A bank using predictive AI for loan approvals might require a human loan officer to sign off on high-stakes decisions. The idea is that human oversight provides a fail-safe to catch errors or bias that AI systems might miss, though there are compelling critiques that people might simply rubber-stamp AI decisions.[ref 196] They are also called “human-in-the-loop” requirements.
Training and certification. Hospitals, financial firms, or law enforcement agencies might be required to obtain accredited licenses or complete mandated coursework before deploying high-risk AI systems.
Record-keeping and audit trails. Organizations may need to log prompts, outputs, and decision rationales so regulators or litigants can reconstruct how harmful decisions occurred.
Individuals Using AI
Use existing tort law to find liability. Many harms individuals can inflict with AI—hacking, defamation, malpractice—are already covered by criminal statutes, tort principles, or professional ethics rules.[ref 197] Even if the tool changes (AI), the duty does not. For example, a lawyer must still verify citations whether they come from Westlaw or a language model. State attorneys general and other entities authorized to enforce laws can reinforce this through guidance and sanctions without creating new technology-specific offenses.
Create AI-specific duties for genuine gaps. Where existing law does not squarely address new harms, legislatures can craft targeted rules—criminalizing non-consensual AI-generated intimate imagery or requiring disclosure for synthetic political ads depicting candidates saying things they never said.[ref 198]
Advantages of Targeting This Stage
End-user liability puts accountability on the actor often best positioned to prevent harm. The individual or organization that chooses to post a deepfake, ignore a safety warning, or rely blindly on AI output controls the immediate risk and can avoid it at low cost—by double-checking facts, limiting sensitive prompts, or declining to deploy AI in high-stakes contexts.
Focusing sanctions at the user layer also protects upstream innovation. Model developers and application builders can continue releasing general-purpose tools without bearing the full weight of every possible downstream abuse, because liability attaches only when users turn tools toward prohibited or negligent uses.
Finally, user-level liability also carries expressive value. By singling out certain AI-enabled acts as punishable—non-consensual synthetic pornography, fraudulent legal filings, deceptive political ads—the law signals which uses of AI violate shared norms, helping shape social expectations in a fast-moving technological landscape.
Disadvantages of Targeting This Stage
End-user liability is inherently retroactive: it activates only after harm has occurred. For irreversible injuries—viral deepfakes that permanently taint reputations, election disinformation that cannot be “un-voted,” psychological trauma from non-consensual intimate images—damages or takedowns arrive too late to help those already harmed.
Identifying individual bad actors is also logistically difficult. Malicious users can automate anonymous accounts, route traffic through foreign servers, or hide behind encryption, making attribution expensive or impossible. Enforcement may depend on platforms or foreign authorities with their own incentives and delays, and plaintiffs face steep proof burdens for causation, while prosecutors must establish intent beyond reasonable doubt.
First Amendment constraints present additional obstacles when regulations target individual expression. Penalties for AI-generated content must be drafted to avoid viewpoint discrimination and unconstitutional vagueness.
Finally, aggressive liability risks over-deterrence. If users fear ambiguous civil suits or criminal charges, journalists may shy away from probing models to expose bias, artists may forgo transformative remixes, and small businesses may abandon useful automation rather than gamble on uncertain legal boundaries.
Summary
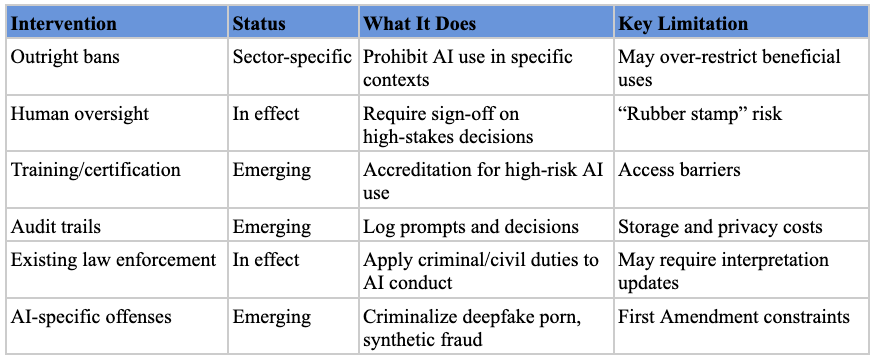
End-user interventions work best when harms result from intentional misuse and the likelihood of effective deterrence is high. They are less useful when offenders are hard to identify or influence (foreign disinformation operators, anonymous bad actors). To strengthen deterrence, policymakers can offer multiple independent enforcement mechanisms (government action plus private rights of action) and impose high statutory penalties. The least-cost-avoider principle can be helpful here: where the user’s choice is the proximate cause of harm, liability should follow.
Conclusion
AI policy is difficult. The technology is general-purpose, fast-moving, and embedded in an ecosystem of actors with overlapping roles and responsibilities. But difficulty is no excuse for imprecision. This primer has argued that effective AI regulation requires specificity along three dimensions: the harm being addressed, the design principles guiding the intervention, and the stage of the AI lifecycle being targeted.
These choices inevitably involve tradeoffs. Preventive interventions reduce irreversible harms but risk being overbroad. Upstream regulations offer leverage over the entire ecosystem but are too blunt to address application-specific problems. Targeting the least-cost avoider is efficient but may concentrate compliance burdens on a small number of firms. No single intervention can address all AI harms, and most will implicate competing values.
This primer does not resolve those tradeoffs—nor could it, given how much depends on context, values, and the specific harm at issue. What it offers instead is a framework for confronting them with greater clarity. Policymakers who can specify which harm they are addressing, justify the regulatory design they have chosen, and identify where in the AI ecosystem their intervention will take effect are better positioned to write laws that are effective, proportionate, and durable.
Superintelligence and Law
Abstract
The prospect of artificial superintelligence—AI agents that can generally outperform humans in cognitive tasks and economically valuable activities—will transform the legal order as we know it. Operating autonomously or under only limited human oversight, AI agents will assume a growing range of roles in the legal system. First, in making consequential decisions and taking real-world actions, AI agents will become de facto subjects of law. Second, to cooperate and compete with other actors (human or non-human), AI agents will harness conventional legal instruments and institutions such as contracts and courts, becoming consumers of law. Third, to the extent AI agents perform the functions of writing, interpreting, and administering law, they will become producers and enforcers of law. These developments, whenever they ultimately occur, will call into question fundamental assumptions in legal theory and doctrine, especially to the extent they ground the legitimacy of legal institutions in their human origins. Attempts to align AI agents with extant human law will also face new challenges as AI agents will not only be a primary target of law, but a core user of law and contributor to law. To contend with the advent of superintelligence, lawmakers—new and old—will need to be clear-eyed, recognizing both the opportunity to shape legal institutions as society braces for superintelligence and the reality that, in the longer run, this may be a joint human-AI endeavor.
How to Count AIs: Individuation and Liability for AI Agents
Abstract
Very soon, millions of AI agents will proliferate across the economy, autonomously taking billions of actions. Inevitably, things will go wrong. Humans will be defrauded, injured, even killed. Law will somehow have to govern the coming wave. But when an AI causes harm, the first question to answer before anyone can be held accountable is: Which AI Did It?
Identifying AIs is unusually difficult. AIs lack bodies. They can copy, split, merge, and swarm at will. Even today, a “single” AI agent is often an ensemble of instances based on multiple models. The complexity will only multiply as AI capabilities improve.
This Article is the first to comprehensively diagnose the legal problem of identifying AIs. For AI agents to be effectively governed, the Article argues, two kinds of identity are required: “thin” and “thick.” Thin identification is the project of tying every action taken by an AI to some human principal. Thin identity will be essential for law to hold accountable the humans who make and use AI agents. Thick identification is the project of distinguishing between AI agents, qua agents. It requires sorting millions of AI entities into discrete, persistent units with stable, coherent goals. Thick identity is essential for governing AIs’ behavior directly in the many contexts where principal–agent problems prevent humans from perfectly controlling AIs.
The Article is also the first to present a solution to the twin identity problem. We call it the “Algorithmic Corporation” or “A-corp,” a legal-fictional entity that can hold property, make contracts, and litigate in its own name. An A-corp is owned by humans. But it is designed to be run by AIs. The A-corp solves the thin identity problem by tying AI actions to a human owner. And it solves the thick identity problem via emergent self-organization. A-corps will own the resources which AIs need to accomplish their goals. AIs that control A-corps will thus have strong incentives to share control only with other AIs that share their goals. In equilibrium, both incentive and selection mechanisms will force A-corps to self-organize into persistent, legally legible entities with coherent underlying goals. These coherent, agentic entities will respond rationally to legal incentives, like liability.
US Tech Force: Why It Faces Major Challenges—and How It Can Succeed Anyway
Summary
- The US Tech Force is a new effort to recruit technical experts to accelerate AI adoption in the executive branch.
- Led by the Office of Personnel Management (OPM), it ambitiously aims to hire 1,000 fellows annually, starting this year.
- There are major benefits to this kind of program, but it will face steep challenges.
- It can use a special authority to hire quickly, but standard practices will likely cause delays, such as the notoriously slow security clearance process.
- While OPM will recruit fellows, executive branch agencies will need to hire, onboard, and fund them—potentially creating friction and inefficiencies.
- Key interventions can increase the odds of the Tech Force’s success.
- Agencies can use interim security clearances to avoid months-long delays.
- Congress could provide specific funding for agencies to hire fellows.
- OPM can use its coordinating role to match fellows to agencies, rather than letting them compete for top candidates.
- The executive branch can use non-competitive eligibility and personnel exchanges with the private sector to increase the government’s return on investment.
On December 15, OPM announced a new program called the US Tech Force. The Tech Force is billed as a “cross-government program to recruit top technologists to modernize the federal government.” It intends to take on “the most complex and large-scale civic and defense challenges of our era,” running the gamut from “administering critical financial infrastructure at the Treasury Department to advancing cutting-edge programs at the Department of Defense.”
Through the program, the government plans to hire approximately 1,000 fellows each year who are highly skilled in software engineering, AI, cybersecurity, data analytics, or technical project management, to serve for one- to two-year terms. The Tech Force aims to foster early-career talent in particular, a demographic that the federal government has long struggled to recruit in sufficient numbers. To support the program, the government is partnering with private-sector companies, which will provide technical training and recruitment.
The sheer scale envisioned for the Tech Force makes it noteworthy. Compare it to the previous administration’s AI Talent Surge initiative, which hired around 250 people between October 2023-24. The U.S. Digital Corps, another similar program, had only 70 fellows in its most recent cohort in 2024. The timeline that OPM outlines for the Tech Force launch is also very ambitious: an initial pilot wave of fellows by Spring 2026, followed by the start of the first on-cycle cohort by September 2026.
While the Tech Force has huge potential, it will need to overcome the challenges inherent to rapid, large-scale talent acquisition in the federal government—and make sure that the government recoups the value of this significant investment.
Using a streamlined process and private partnership to meet the ambitious goals
Per a memo from OPM to agency heads sent the same day as the Tech Force announcement, Tech Force fellows will be hired as “Schedule A” federal employees. Schedule A is an “excepted-service” hiring authority. That means that fellows can be hired using streamlined procedures that generally shorten the hiring timeline, which otherwise runs about 100 days for the default “competitive-service” hiring used to fill most rank-and-file government positions. The difference is significant given that the Tech Force application only just closed on February 2, and at least one report says that the program is targeting start dates in March.
Notwithstanding the expedited Schedule A hiring process, OPM Director Scott Kupor has said that Tech Force fellows will still go through the normal channels for obtaining security clearances, though he noted that agencies have assured him that they will process fellows’ clearances—which typically take months or more—as efficiently as possible.
The Tech Force also involves public-private collaboration. So far, roughly thirty companies have agreed to partner with the government to support the program, including Amazon Web Services, Apple, Google Public Sector, Meta, Microsoft, Nvidia, OpenAI, Oracle, Palantir, and xAI. Per the Tech Force website, these companies can provide support in various ways, such as offering technical training resources and mentorship, nominating employees for participation in the program, and committing to considering Tech Force alums for employment after their government service has ended.
While it’s not apparent what form “technical training resources” will take, they could be quite valuable, coming from companies at the bleeding edge of AI and other critical technology. The government might therefore consider working with companies to extend such resources to other technical employees within the federal government, beyond just the Tech Force teams. This could help diffuse the knowledge and experience gains of the Tech Force program to more federal employees, magnifying the program’s overall impact.
OPM’s complicated role leading the initiative
OPM appears to have primary responsibility for the Tech Force, at least in terms of overall program administration and coordination. The Office of Management and Budget (OMB) and the General Services Administration (GSA)—which, like OPM, focus on governmentwide operations and resources—are also listed in OPM’s announcement as key players. The Tech Force’s website emphasizes that the program has the White House’s backing, with the OPM announcement specifying the involvement of the Office of Science and Technology Policy (OSTP). OSTP has had a prominent role in shaping the Administration’s AI policy, most notably the AI Action Plan released last July.
In the memo sent to agency heads, OPM explained that it will provide centralized oversight and administration for the program, including managing outreach, recruitment, and assessment of the fellows. However, individual agencies will be responsible for hiring, onboarding, and funding Tech Force fellows, with projects and assignments set by agency leadership. OPM also instructs that Tech Force teams will report directly to agency heads (or their designees).
Beyond such statements, OPM has yet to publicly outline how exactly its centralized recruitment and assessment of applicants will intersect with agencies’ responsibility for hiring fellows. Looking to other initiatives helps to show the different structures that are possible for these sorts of programs, as well as their advantages and disadvantages.
First, there’s the U.S. Digital Corps, similarly centered on short-term tech-focused appointments for early-career talent, though much smaller than the Tech Force in terms of size. In that program, the GSA served a coordinating role by pairing candidates with partnering agencies, with input from both applicants and agencies to gauge preferences and fit. While participants were formally hired by GSA, they were “detailed,” i.e., sent on assignment, to their partnering agencies for the duration of the fellowship. Contrast that with the much-larger Presidential Management Fellows (PMF) program, focused on early-career talent across a variety of disciplines. There, OPM provided centralized vetting and selected a slate of finalists, though agencies ultimately decided which if any finalists to interview and hire. For context, OPM selected 825 finalists for the PMF class of 2024.
Based on the OPM memo and other materials, the Tech Force seems closer in its intended structure and scale to the PMF program than the U.S. Digital Corps. But if that’s indeed the case, it’s worth noting some potential pitfalls of that model of which Tech Force leadership should remain aware. Notably, in the ten years before it was discontinued in 2025, on average 50% of PMF finalists did not obtain federal positions. Among other things, the fact that agencies had to pay an $8,000 premium to OPM for every PMF finalist they hired seems to have functioned as a disincentive, and the uncertainty caused by agencies’ long hiring timelines may have prompted finalists to pursue other career opportunities.
As the Federation of American Scientists suggested in the context of potential PMF reform, OPM should focus on creating a strong support ecosystem for the Tech Force to counteract these issues, including by strengthening key partnerships in agencies. Specifically, establishing dedicated and high-ranking “Tech Force Director” positions within agencies could foster a closer fit between agencies’ needs and the benefits the program can offer while continuing to share the administrative load of the program more broadly.
The goal: accelerating the government’s adoption of AI and attracting early-career talent
According to OPM, the purposes of the Tech Force are numerous. First and foremost, it aims to accelerate the government’s adoption of AI and other emerging technologies, including by deploying teams of technologists to various agencies to work on high-impact projects. That strong focus on AI is consistent with the involvement of OSTP, which has led on AI policy.
Judging from its website and other publicly available materials, the Tech Force appears to be focused to a considerable degree on modernizing the federal government’s aging digital systems, perhaps more so than the work on evaluating the capabilities and risks of frontier AI models that offices like the Commerce Department’s Center for AI Standards and Innovation (CAISI) do. Among the types of projects participants will work on, the Tech Force lists AI implementation, application development, data modernization, and digital service delivery.
Even though AI evaluation and monitoring work isn’t explicitly on the list, it fits well within the Tech Force’s large anticipated scale and its broad aim to build “the future of American government technology.” Such work improves the security of AI systems, both for commercial uses and when deployed throughout the federal government. Moreover, expressly including AI evaluation and monitoring work within the scope of the program might bolster recruitment of top talent given its intersection with high-profile national security work—interesting and valuable experience that tech experts typically can’t get outside of the government.
On the subject of recruitment, publicly available materials like the Tech Force website and OPM memo convey a focus on early-career talent, to “[h]elp address the early-stage career gaps in government.” As OPM Director Kupor noted on the heels of the Tech Force announcement, the federal government has long trailed the private sector in attracting and hiring junior talent, with only 7% of the federal workforce under the age of thirty. Kupor frames the Tech Force as part of OPM’s broader effort to “Make Government Cool Again,” infusing it with “newer ideas and newer experiences” to keep pace with rapid technological change.
The Tech Force also plans to employ “experienced engineering managers.” Those managers will lead and mentor teams comprised largely of early-career talent. While the Tech Force will primarily seek early-career talent via traditional recruiting channels, it appears that managers will be drawn mostly or perhaps even exclusively from the program’s partnering companies. OPM thus notes that the program will serve the purpose of providing mid-career technology specialists with an opportunity to gain government experience without necessitating a permanent transition.
Two major challenges for the Tech Force—and how to tackle them
1. Getting the Tech Force set up quickly
OPM is aiming for an initial pilot wave of fellows by the spring (with one report specifying that it’s targeting start dates by March), and for the first full cohort of 1,000 fellows by September. That schedule is possible, though it means that agencies will have to significantly improve upon the government’s average hiring and clearance timelines, which generally take several months, if not longer. There are several ways to do that.
For context, the special “Schedule A” authority that will be used to hire Tech Force fellows can theoretically be deployed very quickly, because it doesn’t require time-consuming procedures like rating and ranking of applicants that regular hiring entails. Though OPM plans to have applicants undergo a technical assessment and potentially interviews with agency leadership, those steps might conceivably add only a few weeks, or even less time if well-staffed.
As for security clearances, there’s similarly no legal barrier to them moving quickly—for example, they have sometimes been issued in a matter of weeks or even days for political appointees, such as those needed for crisis-response efforts and other urgent matters. However, the clearance timeline for the average new hire runs anywhere from two to six months or more, depending on the level of clearance needed and whether the case presents any complications, like foreign business ties, necessitating further investigation.
OPM Director Kupor has said that agencies have promised to process Tech Force fellows’ security clearances as quickly as possible. Indeed, timelines for clearances can shrink from months to days when personnel know that a particular matter is a top priority for the head of their agency or the White House, as documented by Raj Shah and Christopher Kirchhoff in their 2024 book Unit X, about the Pentagon’s elite Defense Innovation Unit.
To this end, agencies could make use of “interim” security clearances for fellows, which would allow them to begin work pending a final clearance decision in cases that don’t raise concerns upon initial review. Interim clearances can shave months off the timeline, yet agencies appear to use them unevenly, perhaps overestimating the risk of a negative final clearance decision. But if agencies are to meet the Tech Force’s ambitious goals (especially for a pilot wave of fellows as early as March), then they need to consider utilizing this tool—and personnel within the organization need to know that they have cover from their leadership in using it.
Still, other operational challenges and questions loom. While pressure from the top can accelerate hiring and clearance timelines, the agency teams tasked with fulfilling such mandates may find it difficult to maintain the pace over longer periods if they’re inadequately resourced and staffed. Furthermore, OPM has made it clear that agencies will fund Tech Force fellows and projects themselves, leaving the overall financial footing of the program unclear, and potentially delaying its actual launch at any agencies that might struggle to find available funds on relatively short notice.
Congress could bolster the Tech Force by appropriating funds to specifically support it, to include project budgets, fellows’ salaries, and the other costs associated with hiring and clearing fellows rapidly and at scale. Without dedicated appropriations, agencies may vary widely in the amount of discretionary funding that they’re able or willing to devote to the program, especially at the outset of this new and previously unaccounted-for expenditure. Congress could also pass measures aimed at increasing the ability of federal hiring teams to assess AI talent, like those in the bipartisan “AI Talent” bill introduced on December 10. Building up this type of AI-enabling talent would help agencies work efficiently in selecting and hiring the right technical expertise, for both the Tech Force and other similar hiring efforts.
Additionally, given OPM’s statements that hiring of Tech Force fellows will be conducted directly by agencies, it remains to be seen how exactly OPM will ensure that agencies don’t waste resources—including valuable time—competing over the same candidates. Within the private sector, competition for AI talent is fierce, and that dynamic seems likely to affect the Tech Force as well. The Tech Force job vacancies posted so far note that they’re “shared announcements” from which various agencies may hire, and suggest that it’ll be up to the agencies to decide which candidates to interview and make offers to. OPM should play a robust coordinating role here so that smaller or less well-known agencies aren’t disadvantaged in attracting and securing sufficient qualified hires. Based on the scale of the program, OPM might even consider a model like the “medical match” system used to pair medical students with residency programs, to help both applicants and agencies weigh their options and needs in a more efficient and organized manner.
Finally, the public-private structure of the program could present some challenges. As full-time federal employees, Tech Force fellows will be subject to the generally applicable conflict of interest rules, which prohibit government employees from receiving outside compensation, or from accessing information or taking action that could unduly benefit themselves or closely related parties financially. Given such rules, the Tech Force website notes that participants nominated by partner companies are expected to take unpaid leave or to separate from their private-sector employers while working for the government. Even still, conflict of interest rules can complicate federal service for tech-company employees, who often have deferred compensation packages (e.g., restricted stock units, options) that vest over time, perhaps several years in the future.
The Tech Force website says that it “expect[s]” that fellows, including those nominated for the program by partnering companies, will be able to retain any deferred compensation packages, though it mentions that companies will need to review details on a case-by-case basis to determine whether any such compensation must be suspended while an individual remains in the program. It bears noting that agencies’ ethics offices may also have to review potential conflicts on a case-by-case basis as they arise, with an eye to the details of the particular financial interest and government matter at issue. Because of the fact-specific nature of that analysis, it’s hard to generalize the result, and the answers could morph over time as projects and financial situations change during the course of government service.
Without greater clarity on whether and how the government can consistently address the challenges raised by conflict of interest rules, the Tech Force may struggle to recruit and retain some promising candidates. This issue is perhaps most significant for the senior engineering managers (with the most compensation on the line) that the program plans to draw from private partners.
2. Ensuring the Tech Force provides long-term benefits for the government
As OPM Director Kupor acknowledges, the federal government has a problem with its early-career talent pipeline, particularly as it relates to the need for greater adoption of AI and other emerging technology. He has cast the Tech Force as part of the solution, a way to infuse the government with a new crop of tech-savvy employees who will lend their expertise to projects of national scope and, in the process, discover that federal service can indeed provide interesting and valuable experience. But it’s unclear at this point how the Tech Force—with its standard two-year service term—will translate to enduring change in the makeup of the federal workforce, or raise the overall level of technological uptake across government. To do so, program leadership could pursue two additional steps.
First, the White House could consider issuing an executive order granting “non-competitive eligibility” (NCE) to Tech Force fellows who successfully complete the program. NCE status allows individuals to be hired for competitive-service positions (which comprise the majority of federal civilian hiring) without having to compete against applicants from the general public. Thus, an individual with NCE status can be hired much more quickly than would otherwise be the case, assuming of course that they meet the qualifications of the position. For any Tech Force fellows interested in continuing their government service after they complete the program, NCE status would likely significantly streamline the process of obtaining another federal position, and ensure that the government doesn’t lose proven talent that’s eager to stay on. The Tech Force website in fact recognizes that some fellows may apply for continued federal service following the end of the program, and so granting NCE status to successful participants is in sync with its goals.
NCE is commonly granted to the alumni of federal programs like the Peace Corps, Fulbright Scholarship, and AmeriCorps VISTA, making it a natural fit for the Tech Force, not least because of its emphasis on early-career talent. NCE is typically valid for between one and three years following successful service completion, though the timeframe specified is entirely up to the White House’s discretion. Establishing a three-year NCE period for Tech Force alumni (versus one or two years) would give individuals the option of pursuing meaningful professional experiences outside of government before potentially returning for another stint. Likewise, it would give the government a broader window in which it might recoup its investment in training previous Tech Force talent.
Second, Tech Force leadership might consider expanding the program to include some opportunities for existing government employees to serve one- to two-year terms in the private sector. The Tech Force’s private-sector partners provide a potential ready-made source of such opportunities, and companies might be amenable given that they will lose some of their own employees and managers to the program for similar periods. For the federal government, making the Tech Force a two-way exchange (even in numbers much more modest than the Tech Force’s 1,000 fellows) would amplify the government’s access to knowledge and experience regarding AI and other emerging tech, beyond the Tech Force teams and projects themselves. That might be valuable insofar as the Tech Force teams could end up being quite insular given their direct reporting line to agency heads.
This sort of science-and-technology exchange program already has some precedent at federal agencies, and would increase diffusion of the Tech Force’s capacity-building benefits throughout the federal workforce. Upon their return to federal service, government employees might disseminate lessons and approaches from the private sector among their colleagues and teams. Furthermore, because the Tech Force’s team leaders will be drawn (perhaps exclusively) from private-sector partners, a two-way exchange could be a way to give existing government tech managers important experience, ultimately providing agencies with a deeper bench of mid- and senior-career talent.
AI Will Automate Compliance. How Can AI Policy Capitalize?
Disagreements about AI policy can seem intractable. For all of the novel policy questions that AI raises, there remains a familiar and fundamental (if contestable) question of how policymakers should balance innovation and risk mitigation. Proposals diverge sharply, ranging from, at one pole, pausing future AI development to, at the other, accelerating AI progress at virtually all costs.
Most proposals, of course, lie somewhere between, attempting to strike a reasonable balance between progress and regulation. And many policies are desirable or defensible from both perspectives. Yet, in many cases, the trade-off between innovation and risk reduction will persist. Even individuals with similar commitments to evidence-based, constitutionally sound regulations may find themselves on opposite sides of AI policy debates given the evolving and complex nature of AI development, diffusion, and adoption. Indeed, we, the authors, tend to locate ourselves on generally opposing sides of this debate, with one of us favoring significant regulatory interventions and the other preferring a more hands-off approach, at least for now.
However, the trade-off between innovation and regulation may not remain as stark as it currently seems. AI promises to enable the end-to-end automation of many tasks and reduce the costs of others. Compliance tasks will be no different. Professor Paul Ohm recognized as much in a recent essay. “If modest predictions of current and near-future capability come to pass,” he expects that “AI automation will drive the cost of regulatory compliance” to near zero. That’s because of the suitability of AI tools to regulatory compliance costs. AI systems are already competent at many forms of legal work, and compliance-related tasks tend to be “on the simpler, more rote, less creative end of the spectrum of types of tasks that lawyers perform.”
Delegation of such tasks to AI may even further the underlying goals of regulators. As it stands, many information-forcing regulations fall short of expectations because regulated entities commonly submit inaccurate or outdated data. Relatedly, many agencies lack the resources necessary to hold delinquent parties accountable. In the context of AI regulations, AI tools may aid both in the development of and compliance with several kinds of policies including but not limited to adoption and ongoing adherence to cybersecurity safeguards, adherence to alignment techniques, evaluation of AI models based on safety-relevant benchmarks, and completion of various transparency reports.
Automated compliance is the future. But it’s more difficult to say when it will arrive, or how quickly compliance costs are likely to fall in the interim. This means that, for now, difficult trade-offs in AI policy remain: in some cases, premature or overly burdensome regulation could stifle desirable forms of AI innovation. This would not only be a significant cost in itself, but would also postpone the arrival of compliance-automating AI systems, potentially trapping us in the current regulation–innovation trade-off. How, then, should policymakers respond?
We tackle this question in our new working paper, Automated Compliance and the Regulation of AI. We sketch the contours of automated compliance and conclude by noting several of its policy implications. Among these are some positive-sum interventions intended to enable policymakers to capitalize on the compliance-automating potential of AI systems while simultaneously reducing the risk of premature regulation.
Automatable Compliance—And Not
Before discussing policy, however, we should be clear about the contours and limits of (our version of) automatable compliance. We start from the premise that AI will initially excel most at computer-based tasks. Fortunately, many regulatory compliance tasks fall in this category, especially in AI policy. Professor Ohm notes, for example, that many of the EU AI Act’s requirements are essentially information processing tasks, such as compiling information about the design, intended purpose, and data governance of regulated AI systems; analyzing and summarizing AI training data; and providing users with instructions on how to use the system. Frontier AI systems already excel at these sorts of textual reasoning and generation tasks. Proposed AI safety regulations or best practices might also require or encourage the following:
- Automated red-teaming, in which an AI model attempts to discover how another AI system might malfunction.
- Cybersecurity measures to prevent unauthorized access to frontier model weights.
- Implementation of automatable AI alignment techniques, such as Constitutional AI.
- Automated evaluations of AI systems on safety-relevant benchmarks.
- Automated interpretability, in which an AI system explains how another other AI model makes decisions in human-comprehensible terms.
These, too, seem ripe for (at least partial) automation as AI progresses.
However, there are still plenty of computer-based compliance tasks that might resist significant automation. Human red-teaming, for example, is still a mainstay of AI safety best practices. Or regulation might simply impose a time-based requirement, such as waiting several months before distributing the weights of a frontier AI model. Advances in AI might not be able to significantly reduce the costs associated with these automation-resistant requirements.
Finally, it’s worth distinguishing between compliance costs—“the costs that are incurred by businesses . . . at whom regulation may be targeted in undertaking actions necessary to comply with the regulatory requirements”—and other costs that regulation might impose. While future AI systems might be able to automate away compliance costs, firms will still face opportunity costs if regulation requires them to reallocate resources away from their most productive use. While such costs will sometimes be justified by the benefits of regulation, these costs might also resist automation.
Notwithstanding these caveats, we do expect AI to eventually significantly reduce certain compliance costs. Indeed, a number of startups are already working to automate core compliance tasks, and compliance professionals already report significant benefits from AI. However, for now, compliance costs remain a persistent consideration in AI policy debates. Given this divergence between future expectations and present realities, how should policymakers respond? We now turn to this question.
Four Policy Implications of Automated Compliance
Automatability Triggers: Regulate Only When Compliance is Automatable
Recall the discursive trope with which we opened: even when parties agree that regulation will eventually be necessary, the question of when to regulate can remain a sticking point. The proregulatory side might be tempted to jump on the earliest opportunity to regulate, even if there is a significant risk of prematurity, if they assess the risks of belated regulation to be worse. The deregulatory side might respond that it’s better to maintain optionality for now. The proregulatory side, even if sympathetic to that argument, might nevertheless be reluctant to delay if they do not find the deregulatory side’s implicit promise to eventually regulate credible.
Currently, this impasse is largely fought through sheer factional politics that often force rival interests into supporting extreme policies: the proregulatory side attempts to regulate when it can, and the deregulatory side attempts to block them. Of course, factional politics is inherent to democracy. But a more constructive dynamic might also be possible. In our telling, both the proregulatory and deregulatory sides of the debate share some important common assumptions. They believe that AI progress will eventually unlock dramatic new capabilities, some of which will be risky and others of which will be beneficial. These common assumptions can be the basis for a productive trade. The trade goes like this: the proregulatory side agrees not to regulate yet, while the deregulatory side credibly commits to regulate once AI has progressed further.
How might the proregulatory side make such a credible commitment? Obviously, one way would enact legislation effective at a future date certain, possibly several years out. But picking the correct date would be difficult given the uncertainty of AI progress. The proregulatory side will worry that that date will end up being too late if AI progresses more quickly than predicted, and vice versa for the proregulatory side.
We propose another possible mechanism for triggering regulation: an automatability trigger. An automatability trigger would specify that AI safety regulation is effective only when AI progress has sufficiently reduced compliance costs associated with the regulation. Automatability triggers could take many forms, depending on the exact contents of the regulation that they affect. In our paper, we give the following example, designed to trigger a hypothetical regulation that would prevent the export of neural networks with certain risky capabilities:
The requirements of this Act will only come into effect [one month] after the date when the [Secretary of Commerce], in their reasonable discretion, determines that there exists an automated system that:
(a) can determine whether a neural network is covered by this Act;
(b) when determining whether a neural network is covered by this Act, has a false positive rate not exceeding [1%] and false negative rate not exceeding [1%];
(c) is generally available to all firms subject to this Act on fair, reasonable, and nondiscriminatory terms, with a price per model evaluation not exceeding [$10,000]; and,
(d) produces an easily interpretable summary of its analysis for additional human review.
Our example is certainly deficient in certain respects. For instance, there is nothing in that text forcing the Secretary of Commerce to make such a determination (though such provisions could be added), and a highly deregulatory administration could likely thereby delay the date of such a determination well beyond the legislators’ intent. But we think that more carefully crafted automatability triggers could bring several benefits.
Most importantly, properly designed automatability triggers could effectively manage the risks of regulating both too soon and too late. They manage the risk of regulating too soon because they delay regulation until AI has already advanced significantly: an AI that can cheaply automate compliance with a regulation is presumably quite advanced. They manage the risk of regulating too late for a similar reason: AI systems that are not yet advanced enough to automate compliance likely pose less risk than those that are, at least for risks correlated with general-purpose capabilities.
There’s also the benefit of ensuring that the regulation does not impose disproportionately high costs on any one actor, thereby preventing regulation from forming an unintentional moat for larger firms. Our model trigger, for example, specifies that the regulation is only effective when the compliance determination from a compliance-automating AI costs no more than $10,000. Critically, these triggers may also be crafted in a way that facilitates iterative policymaking grounded in empirical evidence as to the risks and benefits posed by AI. This last benefit distinguishes automatability triggers from monetary or compute thresholds that are less sensitive to the risk profile of the models in question.
Automated Compliance as Evidence of Compliance
An automatability trigger specifies that a regulation becomes effective only when there exists an AI system that is capable of automating compliance with that regulation sufficiently accurately and cheaply. If such a “compliance-automating AI” system exists, we might also decide to treat firms that properly implement such a compliance-automating AI more favorably than firms that don’t. For example, regulators might treat proper implementation of compliance-automating AI systems as rebuttable evidence of substantive compliance. Or such firms might be subject to less frequent or stringent inspections.
Accelerate to Regulate
AI progress is not unidimensional. We have identified compliance automation as a particularly attractive dimension of AI progress: it reduces the cost to achieve a fixed amount of regulatory risk reduction (or, equivalently, it increases the amount of regulatory risk reduction feasible with a fixed compliance budget), thereby loosening one of the most consequential constraints on good policymaking in this high-consequence domain.
It may therefore be desirable to adopt policies and projects that specifically accelerate the development of compliance-automating AI. Policymakers, philanthropists, and civic technologists may be able to accelerate automated compliance by, for example:
- Building curated data sets that would be useful for creating compliance-automating AI systems;
- Building proof-of-concept compliance-automating AI systems for existing regulatory regimes;
- Instituting monetary incentives, such as advance market commitments, for compliance-automating AI applications;
- Ensuring that firms working on automated compliance have early access to restricted AI technologies; and
- Preferentially developing and advocating for AI policy proposals that are likely to be more automatable.
Automated Governance Amplifies Automated Compliance
Our paper focuses primarily on how private firms will soon be able to use AI systems to automate compliance with regulatory requirements to which they are subject. However, this is only one side of the dynamic: governments will be able to automate many of their core bureaucratic, administrative, and regulatory functions as well. To be sure, automation of core government functions must be undertaken carefully; one of us has recently dedicated a lengthy article to the subject. But, as with many things, the need for caution here should not be a justification for inaction or indolence. Governmental adoption of AI is becoming increasingly indispensable to state capacity in the 21st Century. We are therefore also excited about the likely synergies between automated compliance and automated governance. As each side of the regulatory tango adopts AI, new possibilities for more efficient and rapid interaction will open. Scholarship has only begun to scratch the surface of what this could look like, and what benefits and risks it will entail.
Conclusion: A Positive-Sum Vision for AI Policy
Spirited debates about the optimal content, timing, and enforcement of AI regulation will persist for the foreseeable future. That is all to the good.
At the same time, new technologies are typically positive-sum, enabling the same tasks to be completed more efficiently than before. Those of us who favor some eventual AI regulation should internalize this dynamic into our own policy thinking by carefully considering how AI progress will enable new modes of regulation that simultaneously increase regulatory effectiveness and reduce costs to regulated parties. This methodological lens is already common in technical AI safety, where many of the most promising proposals assume that future, more capable AI systems will be indispensable in aligning and securing other AI systems. In many cases, AI policy should rest on a similar assumption: AI technologies will be indispensable in the regulatory formulation, administration, and compliance.
Hard questions still remain. There may be AI risks that emerge well before compliance-automating AI systems can reduce costs associated with regulation. In these cases, the familiar tension between innovation and regulation will persist to a significant extent. However, in other cases, we hope that it will be possible to design policies that ride the production possibilities frontier as AI pushes it outward, achieving greater risk reduction at declining cost.
Healthy Insurance Markets Will Be Critical for AI Governance
An insurance market for artificial intelligence (AI) risk is emerging. Major insurers are taking notice of AI risks, as mounting AI-related losses hit their balance sheets. Some are starting to exclude AI risks from policies, creating opportunities for others to fill these gaps. Alongside a few specialty insurers, the market is frothing with start-ups—such as the Artificial Intelligence Underwriting Company (for whom I work), Armilla AI, Testudo, and Vouch—competing to help insurers price AI risk and provide dedicated AI coverage.
How this fledgling insurance market matures will profoundly shape the safety, reliability and adoption of AI, as well as the AI industry’s resilience. Will insurance supply meet demand, protecting the industry from shocks while ensuring victims are compensated? Will insurers enable AI adoption by filling the trust gap, or will third-party verification devolve into box-ticking exercises? Will insurers reduce harm by identifying and spreading best practices, or will they merely shield their policyholders from liability with legal maneuvering?
In a recent Lawfare article, Daniel Schwarcz and Josephine Wolff made the case for pessimism, arguing that “liability insurers are unlikely to price coverage for AI safety risks in ways that encourage firms to reduce those risks.”
Here I provide the counterpoint. I make the case, not for blind optimism, but for engagement and intervention. Synthesizing a large swathe of theoretical and empirical work on insurance, my new paper finds considerable room for insurers to reduce harm and improve risk management in AI. However, realizing this potential will require many pieces to come together. On this point, I agree with skeptics like Schwarcz and Wolff.
Before getting into the challenges and solutions though, it’s important to grasp some of the basic dynamics of insurance.
Insurance as Private Governance
Insurers are fundamentally in the business of accurately pricing and spreading risk, but not only that: They also manage that risk by monitoring policyholders, identifying cost-effective risk mitigations, and enforcing private safety standards. Indeed, insurers have often played a key role in the safe assimilation of new technologies. For example, when Philadelphia grew tenfold in the 1700s, multiplying the cost of fires, fire insurers incentivized brick construction, spread fire-prevention practices, and improved firefighter equipment. When electricity created new hazards, property insurers funded the development of standards and certifications for electrical equipment. When automobile demand surged after World War II, insurers funded the development of crashworthiness ratings and lobbied for airbag mandates, contributing to the 90 percent drop in deaths per mile over the 20th century.
Insurers play the role of private regulator not out of benevolence, but because of simple market incentives. There are four key dynamics to understand.
First, insurers want to make premiums more affordable in order to expand their customer base and seize market share. Generally reducing risks is the most direct way to reduce premiums.
Second, insurers want to control their losses. Once insurers issue policies, they directly benefit from any further risk reductions. Encouraging policyholders to take cost-effective mitigations and monitoring them to ensure they don’t take excessive risks directly protects insurers’ balance sheets. Examples of this from auto insurance include safety training programs and telematics. The longer-term investments insurers make in safety research and development (R&D)—such as car headlight design—allow them to profit from predictable reductions in the sum and or volatility of their losses. Insurance capacity—the amount of risk insurers can bear—is a scarce resource, ultimately limited by available capital: Highly volatile losses strain this capacity by requiring insurers to hold larger capital buffers.
Third, insurers want to be partners to enterprise. Risk management services (such as cybersecurity consulting) are often a key value proposition for large corporate policyholders, and they help insurers to differentiate themselves. Insurers can also enable companies to signal product quality and trustworthiness more efficiently, through warranties, safety certificates, and proofs of insurance. This is precisely what’s driving the boom in start-ups competing to provide insurance against AI risk: filling the large trust gap between (often young) vendors of cutting-edge AI technology and wary enterprise clients struggling to assess the risks of an unproven technology.
Fourth and finally, insurers seek “good risk.” Underwriting fundamentally involves identifying profitable clients while avoiding adverse selection (where insurers attract and misprice too many high-risk clients). This requires understanding the psychologies, cultures, and risk management practices of potential clients. For example, before accepting a new client, cyber insurance underwriters will make an extensive assessment of the client’s cybersecurity posture.
Insurers deploy various tools to achieve these aims: adherence to safety standards as a condition of coverage, risk-adjusted premiums rewarding safer practices, audits or direct monitoring of policyholders, and refusing to pay claims if the policyholder violated the terms of the contract (such as by acting with gross negligence or recklessness).
Are these tools effective, though? Does insurance uptake really reduce harm relative to a baseline where insurers are absent?
Moral Hazard vs. the Distorted Incentives of AI Firms
Skeptics of “regulation by insurance” point out that the default outcome of insurance uptake is moral hazard—that is, insureds taking excessive risk, knowing they are protected. From this angle, the efforts insurers make to regulate insureds are just a Band-Aid for a problem created by insurance.
These skeptics have a point: Moral hazard is a danger. Nevertheless, insurers can often improve risk management and reduce harm, despite moral hazard. My research finds this happens when the incentives for insureds to take care were already suboptimal: Insurance essentially acts as a corrective for many types of market failures.
Consider fire insurance again: Making a house fire-resistant protects not just that one house but also neighboring ones. However, individual homeowners don’t see these positive externalities: They are underincentivized to make such investments in fire safety. By contrast, the insurer that covers the entire neighborhood (or even just most of it) captures much more of the total benefit from these investments. It frequently happens that insurers are thus better placed to provide what are essentially public goods.
Are frontier AI companies such as OpenAI, Anthropic, or Google DeepMind sufficiently incentivized to take care? Common law liability makes a valiant attempt to do so, but as I and others point out, it is not up to the task for several reasons.
First, these companies are locked in a winner-take-most race for what could quickly become a hundred-billion- or multitrillion-dollar market, creating intense pressure to prioritize increasing AI capabilities over safety. This is especially true for start-ups that are burning capital at extraordinary rates while promising investors extremely aggressive revenue growth.
Second, safety R&D suffers from a classic public goods problem: Each company bears the full cost of such R&D, but competitors capture much of the benefit through spillovers. This leads to chronic underinvestment in a wide range of open research questions, despite calls from experts and nonprofits.
Third, the prospect of an AI Three Mile Island creates a free-rider problem. Nuclear’s promise of abundant energy died for a generation after accidents such as Three Mile Island and Chernobyl fueled public backlash and regulatory scrutiny. Similarly, if one AI company accidentally causes an AI Three Mile Island, the entire industry would suffer. But while all these firms benefit from others investing in safety, each prefers to freeride.
Fourth, a large enough catastrophe or collapse in investor confidence will render AI companies “judgment-proof”—that is, insolvent and unable to pay the full amount of damages for which they are liable. Victims (and or taxpayers) will be left to foot the bill, essentially subsidizing the risks these companies are taking.
Fifth is the lack of mature risk management in the frontier AI industry. A wealth of research finds that individuals and young organizations systematically neglect low-probability, high-consequence risks. This is compounded by the overconfidence, optimism, and “move fast and break things” culture typical of start-ups. Also likely at work is a winner’s curse: It’s likely the AI company most willing to race ahead most underestimates the tail-risks.
Insurance uptake helps correct these misaligned incentives by involving seasoned stakeholders who don’t face the same competitive dynamics, are required by law to carry substantial capital reserves for tail-risks, and, again, are better placed to provide public goods.
Admittedly, history proves these beneficial outcomes are possible, not a given. There are still further challenges that skeptics rightly point to and which must be overcome if insurance is to be an effective form of private governance. I turn to these next.
Pricing Dynamic Risk
It is practically a truism to say AI risk is difficult to insure given the lack of data on incidents and losses. This is distracting and misleading. Distracting because trivially true. Every new risk has no historical loss data: That says nothing of how well or poorly insurers will eventually price and manage it. Misleading because compared to, say, commercial nuclear power risk when it first appeared, data is intrinsically easier to acquire for AI risks: Unlike nuclear power plants, it’s possible to stress-test live AI systems quite cheaply (known as “red–teaming”). Other key data points, such as the cost of an intellectual property lawsuit or public relations scandal, are simply already known to insurers.
The dynamic nature of AI risk is the warranted concern. Because the underlying technology is evolving so rapidly, insurers could struggle to get a handle on it: Information asymmetries between insurers and their policyholders (especially if these last are AI developers) could remain large; lasting mitigation strategies will be difficult to identify; and the actuarial models that insurers traditionally rely on, which assume historical losses predict future ones, may not hold up.
This mirrors difficulties insurers faced with cyber risk, which stemmed from rapid technological evolution and intelligent adversaries adapting their strategies to thwart defenses. AI risk will include less of this adversarial element, at least where AI systems aren’t scheming against their creators.
Cyber insurers have recently started overcoming this information problem. Instead of relying solely on policyholders self-reporting their cybersecurity posture through lengthy, annual questionnaires, insurers now continuously scan policyholders’ vulnerabilities and security controls. This was enabled by so-called insurtech innovations and partnerships with major cloud service providers that already have access to much of the information on policyholders that insurers need. Insurers have also come to a consensus on mandating certain security controls, such as multi-factor authentication and endpoint detection, demonstrating that durable mitigations can be found.
For the AI insurance market to go well, insurers must learn the lessons of cyber. They must prepare from the start to use pricing and monitoring techniques, such as the aforementioned red-teaming, that are as adaptive as the technology they are insuring. They should also aim to simply raise the floor by mandating adherence to a robust safety and security standard before issuing a policy. Standardizing and sharing incident data will also be critical.
Even if insurers fail to price individual AI systems accurately, insurers can still help correct the distorted incentives of AI companies, as long as aggregate pricing is good enough. To illustrate: Pricing difficulties notwithstanding, aggregate loss ratios for cyber are well controlled, making it a profitable line of insurance. This speaks to the effectiveness of risk proxies such as company size, deployment scale, and economic sector. When premiums depend only on these factors, ignoring policyholders’ precautionary efforts, insurers lose a key tool for incentivizing good behavior. However, premiums will still track activity levels, a key determinant of how much risk is being taken. Excessive activity will be deterred by premium increases. Thus even with crude pricing, by drawing large potential future damages forward, insurers can help put brakes on the AI industry’s race to the bottom: The industry as a whole will be that much better incentivized to demonstrate their technology is safe enough to continue developing and deploying at scale.
Removing the Wedge Between Liability and Harm
For insurers covering third-party liability, sometimes lawyers are a safer investment than investments in safety.
We’ve occasionally seen this dark pattern in cyber insurance, where, in response to incidents, sometimes insurers provide lawyers who prevent outside forensics firms from sharing findings with policyholders to avoid creating evidence of negligence. This actively hampers institutional learning. The risk of liability may decrease, but the risk of harm increases.
The only real remedy is policy intervention, in the form of transparency requirements and clearer assignment of liability. Breach notification laws and disclosure rules are successful examples in cyber: With less room to bury damning incidents or poor security hygiene, insurers and policyholders have refocused their efforts on mitigating harms.
California’s recently passed Transparency in Frontier Artificial Intelligence Act is therefore a step in the right direction. The act creates whistleblower protections and requires major AI companies to report to the government what safeguards they have in place. Even skeptics of regulation by insurance and proponents of a federal preemption of state AI laws, recognize the value of such transparency requirements.
A predecessor bill that was vetoed last year would have taken this further by more clearly assigning liability to foundation model developers for certain catastrophic harms. The question of who to assign liability to has been discussed in Lawfare and elsewhere; at issue here is how it gets assigned. By removing the need to prove negligence, a no-fault liability regime for such catastrophes would eliminate legal ambiguity altogether, mirroring liability for other high-risk activities such as commercial nuclear power and ultra-hazardous chemical storage. This would focus insurer efforts on pricing technological risk and reducing harm, rather than pricing legal risk and shunting blame around.
Workers’ compensation laws from the 20th century were remarkably successful in this regard. The Industrial Revolution brought heavy machinery and, with it, a dramatic rise in worker injury and death. Once liability was clearly assigned to employers in the 1910s though, insurers’ inspectors and safety engineers got to work bending the curve: improvements in technology and safety practices produced a 50 percent reduction in injury rates between 1926 and 1945.
Catastrophic Risk: Greatest Challenge, Greatest Opportunity
Nowhere are the challenges and opportunities of this insurance market more stark than with catastrophic risks. Both experts and industry warn of frontier AI systems potentially enabling bioterrorism, causing financial meltdowns, or even escaping the control of their creators and wreaking havoc on computer systems. If even one of these risks is material, the potential losses are staggering. (For reference, the NotPetya cyberattack of 2017 cost roughly $10 billion globally; major IT disruptions such as the 2024 CrowdStrike outage cost some tens of billions globally; the coronavirus pandemic is estimated to have cost the U.S. alone roughly $16 trillion.)
Under business as usual, insurers face silent, unpriced exposure to these risks. Few are the voices sounding the alarm. We may therefore see a sudden market correction, similar to terrorism insurance post-9/11: After $32.5 billion in losses, insurers swiftly limited terrorism risk coverage or exited the market altogether. With coverage unavailable or prohibitively expensive, major construction projects and commercial aviation ground to a halt since bank loans often require carrying such insurance. The government was forced to stabilize the market, providing insurance or reinsurance at subsidized rates. It’s entirely possible an AI-related catastrophe could similarly freeze up economic activity if AI risks are suddenly excluded by insurers.
Silent coverage aside, insurers don’t have the risk appetite to write affirmative coverage for AI catastrophes. The likes of OpenAI and Anthropic already can’t purchase sufficient coverage, with insurers “balking” at their multibillion-dollar lawsuits for harms far smaller than those experts warn might come. Such supply-side failures leave both the AI industry and the broader economy vulnerable.
An enormous opportunity is also at stake here. Counterintuitively, it is precisely these low-probability, high-severity risks that insurers are well-suited to handle. Not because risk-pooling is very effective for such risks—it isn’t—but because, when insurers get serious skin in the game for such risks, they are powerfully motivated to invest in precisely the efforts markets are currently failing to invest in: forward-looking causal risk modeling, monitoring policyholders, and mandating robust safeguards. For catastrophic risks, these efforts are the only effective method for insurers to control the magnitude and volatility of losses.
Such efforts are on full display in commercial nuclear power. Insurers supplement public efforts with risk modeling, safety ratings, operator accreditation programs, and plant inspections. America’s nuclear fleet today stands as a remarkable achievement of engineering and management: Critical safety incidents have decreased by over an order of magnitude, while energy output per plant has increased, in no small part thanks to insurers.
Put another way, insurers are powerfully motivated to pick up the slack from poorly incentivized AI companies. The challenge of regulating frontier AI can be largely outsourced to the market, with the assurance that if risks turn out to be negligible, insurers will stop allocating so many resources to managing them.
Clearly delegating to insurers the task of pricing in catastrophic risk from AI also helps by simply directing their attention to the issue. My research finds that insurers price catastrophic risk quite effectively when they cover it knowingly, even when it involves great uncertainty. To reuse the example above, commercial nuclear insurance pricing was remarkably accurate at least as early as the 1970s, despite incredibly limited data. Insurers estimated the frequency of serious incidents at roughly 1-in-400 reactor years, which turned out to be within the right order of magnitude; the same can’t be said of the 1-in-20,000 reactor years estimate from the latest government report at the time.
This suggests table-top exercises or scenario modeling—such as those mandated by the Terrorism Risk Insurance Program—are particularly high-leverage interventions. By simply surfacing threat vectors and raising the salience of catastrophe scenarios, these turn unknown unknowns into at least known unknowns, which insurers can work with.
Alerting insurers to catastrophic AI risk is not enough however. They will simply write new exclusions, and the supply of coverage will be lacking or unaffordable. In response, major AI companies will likely self-insure through pure captives—that is, subsidiary companies that insure their parent companies. Fortune 50 companies such as Google and Microsoft already do this. Smaller competitors would be left out in the cold, exposed to risk or paying exorbitant premiums.
Pure captives also sacrifice nearly all potential for private governance here: They do nothing to solve the industry’s various legitimate coordination problems, such as preventing an AI Three Mile Island; and they lack sufficient independence to be a real check on the industry.
Mutualize: An Old Solution for a New Industry
To recap: Under business as usual, coverage for catastrophic AI will be priced all wrong, and will face both supply and demand failures; yet this is precisely where the opportunity for private governance is greatest.
There is an elegant, tried-and-true solution to these problems: The industry could form a mutual, a nonprofit insurer owned by its policyholders. AI companies would be insuring each other, paying premiums based on their risk profiles and activity levels. Historically, it is mutuals that have the best track record of matching effective private governance with sustainable financial protection. They coordinate the industry on best practices, invest in public goods such as safety R&D, and protect the industry’s reputation through robust oversight, often leveraging peer pressure. Crucially, mutuals have sufficient independence from policyholders to pull this off: No single policyholder has a monopoly over the mutual’s board.
The government can encourage mutualization by simply giving its blessing, signaling that it won’t attack the initiative. In fact, the McCarran-Ferguson Act already shields insurers from much federal anti-trust law, though not overt boycott: The mutual cannot arbitrarily exclude AI companies from membership.
If mutualization fails and market failures persist, the government could take more aggressive measures. It could mandate carrying coverage for catastrophic risk, and more or less force insurers to offer coverage through a joint-underwriting company. These are dedicated risk pools offering specialized coverage where it is otherwise unavailable. This intervention (or the threat of it) is the stick to the carrot of mutualization: Premiums would undoubtedly be higher and relationships more adversarial. Still, it would achieve policy goals. It would protect the AI industry from shocks, ensure victims are compensated, and develop effective private governance.
Whether a mutual or a joint-underwriting company, the idea is to create a dedicated, independent private body with both the leverage and incentives to robustly model, price, and mitigate covered risks. Even the skeptics of private governance by insurance agree that this works. Again, nuclear offers a successful precedent: Some of its risks are covered by a joint-underwriting company, American Nuclear Insurers; others, by a mutual, Nuclear Electric Insurance Limited. Both are critical to the overall regulatory regime.
Public Policy for Private Governance
Both skeptics and proponents of using insurance as a governance tool agree: It won’t function well without public policy nudges. This market needs steering. Light-touch interventions include transparency requirements, clearer assignment of liability, scenario modeling exercises, and facilitating information-sharing between stakeholders. Muscular interventions include insurance mandates and government backstops for excess losses.
Backstops, a form of state-backed insurance, make sense only for truly catastrophic risks. These are risks the government is always implicitly exposed to: It cannot credibly commit not to provide disaster relief or bailouts to critical sectors. Major AI developers may be counting on this. Instead of an ambiguous subsidy in the form of ad hoc relief, an explicit public-private partnership allows the government to extract something in return for playing insurer of last resort. Intervening on the insurance market has the benefit of avoiding picking winners or losers (in contrast to taking an equity stake in any particular AI firm).
A backstop also creates the confidence and buy-in the private sector needs to shoulder more risk than it otherwise would. This is precisely what the Price-Anderson Act did for nuclear energy, and the Terrorism Risk Insurance Act did for terrorism risk. Price-Anderson even generated (modest) revenue for the government through indemnification fees.
Major interventions require careful design of course. Poorly structured mandates could simply prop up insurance demand or create a larger moat for well-resourced firms. Ill-conceived backstops could simply subsidize risk-taking. On the other hand, business as usual carries its own risks. It leaves the economy vulnerable to shocks, potential victims without a guarantee they will be made whole, and private governance to wither on the vine or, worse, to perversely pursue legal over technological innovation.
The stakes are high then, and early actions by key actors—governments, insurers, underwriting start-ups, major AI companies—could profoundly shape how this nascent market develops. Nothing is prewritten: History is full of cautionary tales as well as success stories. Steering toward the good will require a mix of deft public policy, risk-taking, technological innovation, and good-faith cooperation.